A ‘fork in the road’: How contributors on Community Notes ‘do’ truth
Facilitators: Brogan Latil (University of Amsterdam), Bastian August (University of Paderborn), Lydia Kollyri (University of Amsterdam)
Participants: Gizem Brasser (University of Amsterdam), Anna Cattaneo (DensityDesign, Politecnico di Milano), Niamh Messenger (University of Amsterdam), Emily Morrissey (University of Amsterdam), Anvee Tara (University of Amsterdam)
Designer: Anna Cataneo (DensityDesign, Politecnico di Milano)
Key Findings
In our analysis of contributor practices in Community Notes (CN) on X, we found seemingly uncoordinated yet heterogeneous clusters in how contributors perform epistemic labor in reference to their given affordances. For one, there is widespread dissensus on the legitimate use of CN, with contributor camps forming around both fact-checking information and enforcement of X’s guidelines. Secondly, without an affordance for peer-to-peer communication, contributors correspond with one another behind the interface by ‘misusing’ the note-writing affordance. Such communication takes form through, for instance, policing one another and communicative 'play'. Lastly, contributors link to disparate types of sources when evidencing their posts. While many of the most successful notes link to journalistic sources, the most common ‘successful’ sources also refer to X’s own guidelines on scams, containing evidence to the platform itself. We also noted a growing trend in the use of Grok as a source, presenting troubling implications for the terrain of public knowledge production and verification online.
1. Introduction
With the growing presence of Community Notes (CN) on X, and its recent appropriation by Meta, we are in the midst of a new (but not unprecedented) political configuration in online speech and knowledge moderation. As the “keepers of public discourse” (Crawford & Gillespie 2016, 413) and with myriad stakeholders in mind, platforms must contend with defining and enforcing the rules of online speech while satisfying conventional demands for free expression. The epistemic aporia called ‘post-truth’ and the Covid-19 pandemic exacerbated this dialectic, calling into question the politics of truth that had for so long rested in the hands of experts and institutions. Where the notion of platforms as ‘public squares’ has been a popular outlook, even the one preferred by the US Supreme Court, content moderation via fact-checking (Amazeen 2020), deplatforming (Rogers 2020), demonetization (Hua et al. 2022), demotion (Leerssen 2023), and ranking (Rieder et al. 2018) has further emboldened accusations of platforms’ ‘left-wing bias’, censorship logics, and elitist exceptionalism.
Presented as a solution to this moderation problematic, CN promises to return epistemic authority to ‘the people’ in the “Global Town Square” of X (X Business 2024). This novel, community-based fact-checking system allows verified users (contributors) to “collaboratively add context to potentially misleading posts” to “create a better informed world” (X 2025). When contributors see a potentially misinformative post on the platform, they can propose and vote on ‘notes’ in a closed-doors interface to fact-check the post’s content; when a note receives enough votes from users with opposing political ideologies (calculated by a ‘bridging’ algorithm), it is automatically attached to the post in question. According to X, these mechanisms ensure free, diverse, decentralized, and consensus-based truth-production (X 2025).
CN’s plebiscitarian shift has much in common with Web 2.0 promises and imaginaries. As Michael Stevenson (2018, 84) asserts, pre-platform online communities often operated around imaginaries of the ‘public’, where "harnessing collective intelligence was by building an 'architecture of participation' by lowering the threshold for users to contribute.” Awarding epistemic authority to users allows X to mitigate its moderation costs, pass off liabilities around problematic content, and deal with the scale of emerging posts. At the same time, its promises of truth via free speech, diverse representation of perspectives, decentralization, and consensus gain power from common anxieties around post-truth, authoritarianism, and collapsing democratic systems.
The efficacy of CN as a crowdsourced fact-checking system is currently under dispute amongst researchers and journalistic voices. In a Bloomberg article, Flam (2024) reports that CN is indeed “working” in the context of “scientific issues” - specifically when applied to posts about Covid-19. Allen et al. (2024) indicate that CN contributors use ‘high quality sources’ when fact-checking Covid-19 discourses; however, nuance around the definition of source quality is missing. Especially around highly polarizing topics, the crowdsourced nature of CN seems to earn more trustworthiness in individuals who are otherwise skeptical of authoritative or expert fact-checking (Drolsbach et al. 2024), evading the ‘backlash effect’ (McIntyre 2017).
However, the success of CN to reproduce expert-based facts 1) appears to be contingent on the topic of discussion, 2) relies on the ‘good faith’ of contributors, and 3) complicates the ground-up principles of crowdsourced wisdom. A Bellingcat article (Koltai et al. 2023), for instance, reported the spread of misinformation via CN around the identity of Taylor Swift’s bodyguard - a seemingly low-stakes issue until his connection to the Israeli Defence Force became publicly disputed. Around such newsy and politically affective topics, CN seems to lose the ability to produce consensus (Czopec 2023). This can be seen in the case of the Israeli genocide in Palestine when CN failed to curtail the circulation of misinformation around the events of October 7, 2023 (Alba et al. 2023). As a result, notes proposed on such controversies are often too slow to release before problematic posts widely circulate (Chuai et al. 2023) or are left in limbo behind the CN interface. Indeed, this trend of algorithmic and ideological dissensus has held steady over the past several years of CN and is consistent across international publics (Bouchaud & Ramaciotti 2025). The wisdom of the public, in this case, is only as good as the infrastructure that manages it.
CN not only provides a site for free speech absolutists, cyberlibertarians, and the (now common) very-online-person to hang their hats, but appeals to a wide variety of political sensibilities that enjoy ideas of decentralization, freedom of speech, or democratic organizations. Yet, contributors are bound to the affordances, algorithmic infrastructure, and rules of non-linguistic conversation in the CN interface, shaping debate and knowledge production on both individual and group levels. CN appears to be such an evaluative infrastructure where "control is radically distributed, while power remains centralized" (Kornberger et al. 2017, 84). Such promises of free-speech absolutism obscure the mechanisms of containment which allow platforms to construct invisible infrastructures for public discourse and knowledge production on their own proprietary terms, giving them the power to shape the shape of truth and its construction. In addition to if it works, it is crucial to delineate and situate on what exactly CN does its work. How CN contains the epistemic possibilities of the contributor through its interface, and how contributors negotiate with their possibilities for epistemic labor, is the object of this research.
1.2 Datasets Used
This project uses two main sources of data. The first is directly situated in the interface, mapping and interpreting the functional, cognitive, and sensory affordances of CN in line with Stanfill’s (2015) discursive interface analysis. The second comes from X’s open source CN data, available for download within the CN interface. Consisting of five different types of datasets on proposed notes, note ratings, note status history, limited contributor information, and flagged posts, we collected all available data on July 1, 2025 which accounts for roughly 2.1 million notes. This data is publicly available on the platform, which feeds into X’s promise for data transparency. However, as we describe in our Methods section, this data is curated in a way that makes research difficult and requires a high amount of effort to make it workable.
1.3 Research Questions
The question then emerges as to how contributors actually use CN in relation to its algorithms, rules, and affordances, and how these relations reconfigure truth-construction and deliberation on the platform. This project turns to the CN interface to study the epistemic processes of its contributors through the notes they produce and vote on. As a system which promises unfettered, decentralized, and plebiscitarian knowledge production through consensus, CN becomes an epistemic infrastructure through which X regulates speech and truth norms. Here, the relations between the interface affordances, rules, and contributors are of primary interest. In other words, we aim to deconstruct an ‘epistemic assemblage’. Here, we ask:
How do contributors navigate and perform epistemic labor within the CN interface?
This question itself implies that ‘truth’ is not a fixed category but is constructed specific to the political configuration, technologies, and common sense of a given context. The ‘fact’ is one flavor, or genre, of a dominant understanding of ‘truth’. And further, this question makes room to operate outside of the assumption that CN is fundamentally a fact-checking system. As our findings depict, contributors imagine the purpose of CN in disparate ways.
To study the relationship between CN’s affordances and its containment of contributor knowledge work, we focus on two levels of analysis:
Affordances
-
Who is the ideal user for X’s CN, and how does CN produce this ideal user through its affordances?
-
How does X envision the ideal environment where knowledge is negotiated, produced, and distributed?
-
How does X envision the ideal product of CN?
Contributor Practices
-
How do contributors imagine and negotiate the purpose of CN?
-
What epistemic practices do contributors use to construct notes within the CN interface?
-
What communicative practices emerge between contributors in note negotiations? Do they ‘misuse’ CN’s affordances?
-
Are some practices more ‘successful’ at publishing notes than others?
-
What sources are used in note writing?
To analyze the contributors’ practices of note-production, we use a mixed methods approach consisting of affordance, quantitative, and qualitative analysis using digital methods (Rogers 2023). Three main sources of data are used, each corresponding to one level of analysis: 1) the interface’s low-level affordances, 2) CN’s open source dataset, and 3) manually crawling notes, informed by themes emerging from the macro approach. This framework provides insight into not only the practices of contributors within the interface but also the nature of CN as an epistemic infrastructure that resists simple taxonomies.
2. Methodology
To study how CN contributors use and negotiate with the affordances for knowledge-work, our methodological approach attends to three analytical levels. The level of affordances is the first, and the latter two are macro and micro perspectives of user practices. Indeed, an analysis of user practices must be grounded in the design of the environment in which said users perform; that is, practices are produced by and emerge as a reaction to the affordances of a platform’s interface (Stanfill 2015). In addition to the aims of this project, working with X’s open-source CN data produced insights into the researchability of this system as well as how power is quietly exercised through a platform’s data curation; the availability of data does not evince the transparency of a system.
2.1 Discursive Interface Analysis
Affordances refer to how objects enable and constrain certain actions, producing norms and making certain behaviors more possible than others (Bucher and Helmond, 2018). In this way, affordances can structure behavior in digital platforms. Building on this approach, the first step of the research project focuses on exploring the hidden ideologies embedded in platform affordances and design. To examine the norms that the interface produces, a discursive interface analysis was conducted, following Stanfill’s approach (2015). As Stanfill explains, this method offers “a tool for the new media research kit to improve our understanding of how norms for technologies and their users are produced and with what implications” (Stanfill 2015, 1059). Her framework provides a way to critically examine how platforms shape user behavior and define ideal users. In particular, the analysis was guided by the following research questions:
- Who is the ideal user for X’s CN, and how does CN produce this ideal user through its affordances?
- Through this behavior, what environment is constructed? How does X envision the ideal environment where knowledge is negotiated, produced, and distributed?
To answer these questions, we drew on Stanfill’s distinction between three types of affordances: a. functional affordances, referring to the possibilities that are opened up (and others that are closed off) for users, b. cognitive affordances, which relate to meaning-making, such as naming, labeling, site taglines, and self-descriptions, c. sensory affordances, referring to how design indicates priorities for users, making something stand out.
The first phase of the study involved gaining familiarity with the platform’s interfaces and identifying low-level affordances (see Bucher and Helmond 2018). In total, four different sections of the platform were analyzed: “Notes,” “Your Profile,” “Download Data,” and “About”. A map was created for each section, outlining the various affordances and their layered structure. To enrich the analysis, Stanfill’s framework was combined with key elements from MacLeod and McArthur ’s (2019) approach. Rather than analyzing the platform as a whole, the study focused on individual affordances (see MacLeod and McArthur 2019). Each affordance was examined through the three dimensions (listed above), while also incorporating components from MacLeod and McArthur ’s model (e.g., function, behavior, identifier, and default settings). The “default option” associated with each affordance was analyzed, as it can reveal how the platform subtly guides user behavior, making some options more possible than others. Table 1 presents an example of how the X affordances were analyzed using this framework.
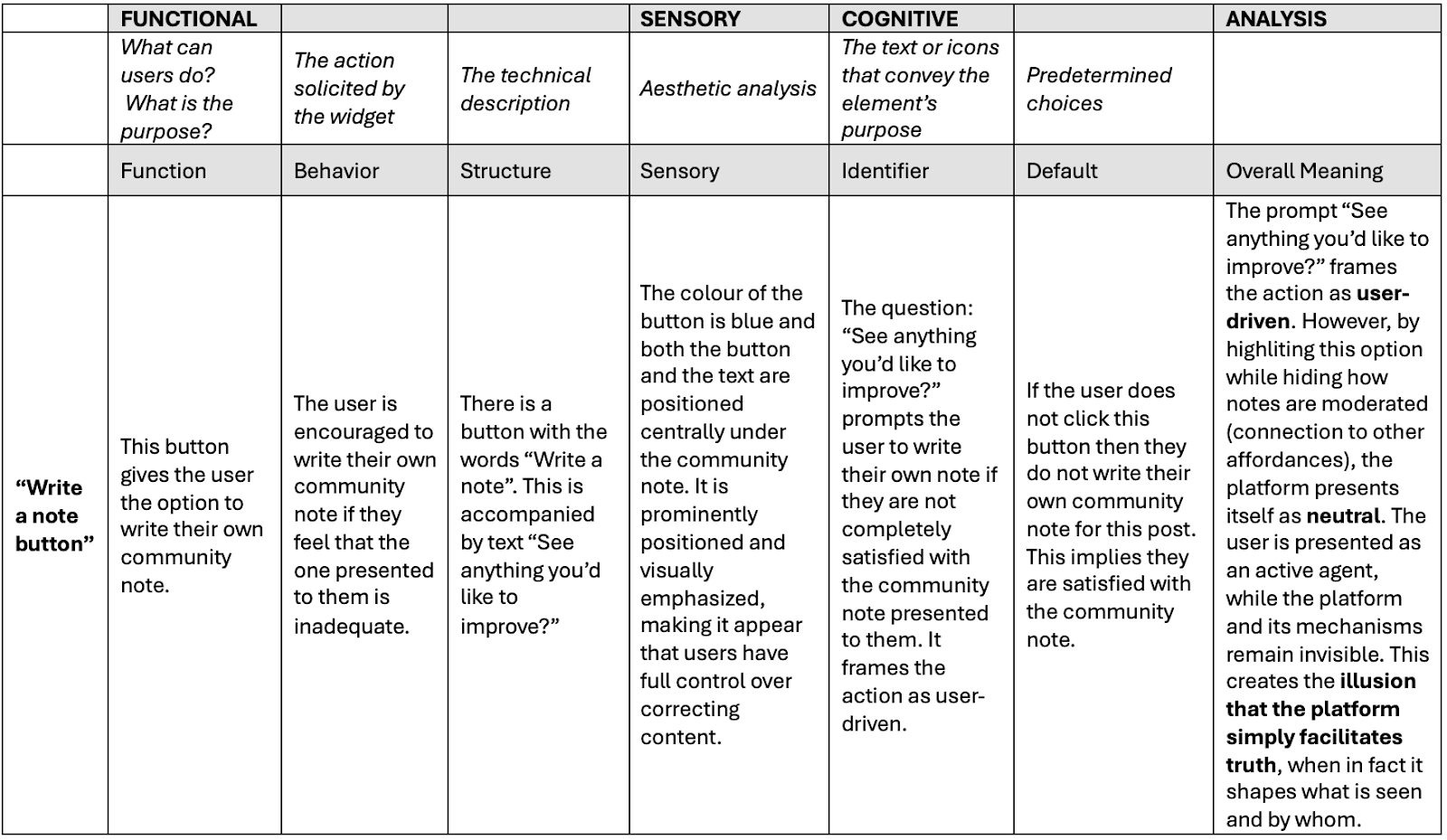
Table 1. Discursive Interface Analysis for CN Affordances. The sample used is from our analysis on the “Write a note” button.
In the final stage, the affordances identified across interfaces were examined to uncover recurring patterns and themes. This analysis addressed the research questions and revealed how the platform constructs its ideal user, promotes particular behaviors, and shapes its broader media environment.
2.2 Practices
Following our affordance analysis, we studied contributor practices with a macro, big data approach to draw out patterns and tendencies in note-writing, supplemented by a micro, content analysis to hone in on the nuance of such practices in situ.
2.2.2 Macro Approach
To study and quantify the emerging practices of CN contributors and use cases of the affordances described in the previous section, we investigated X’s accessible data on all the produced and voted on notes up until July 1, 2025 (roughly 2.1 million Notes). Due to the limited timeframe of our research, we did not focus on the voting behavior of the users but rather on how the notes themselves are constructed. We did this by quantitatively investigating the summary (textual component) of the published and unpublished notes. We asked the questions:
-
What are the most distributed topics among the published and unpublished Notes?
-
What are the most cited domains and unique URLs?
-
What are the most cited domains among each of the topics?
First, we used the Status file and extracted all the statuses of Notes that were rated as “currently rated helpful”. Then we matched the Note id of the ones with a “currently rated helpful” status (meaning the published notes) and searched their ids in the Notes file to construct two separate datasets. The first consists of all the published CNs (the ones rated helpful) and the second consists of CNs that were “not rated helpful”, therefore falling out of the “needs more ratings” status. CNs that remain in this status will not be published and will be discarded after two weeks. Since some posts did get deleted, the filtered status data for each category was bigger than the actual final notes. For example, the CNs with the status “currently rated helpful” had a rough count of 180k in the Status dataset; however, only around 166k of their unique Note IDs could be found in the Notes file. It is unclear why this discrepancy occurred, but similar discrepancies were found while generating the other datasets. The rest of the CNs, approximately 1.9 million CNs, had the status “needs more ratings”. Out of these, we took a random sample of 150k Notes to make the data processable for further analysis. After filtering, we ended up with two datasets relevant for the macro approach.
The first dataset includes notes rated helpful (the ones that got published) and consists of 166,282 unique notes. The second dataset included notes rated as not helpful and consists of 64,633 unique notes. Interestingly, the second dataset is much smaller as the algorithm to mark a note as not helpful requires a close to unanimous voting by contributors (X Community Notes, n.d.). Each of these datasets is comprised of columns such as noteID, noteAuthorParticipantId, tweetID, classification (AKA note status), summary, and date.
Step #2 Analysis of URLS
Since our analysis is interested in the contents of the summary column to analyze contributor practices, we trimmed the datasets to only include the noteID connected to the summary column. Once this step was complete, our data was ready for analysis.
Within the summary column, all of the text that the contributor writes is displayed. This means that both the body text of the note and any URLs that the contributor mentioned are included. Both of these pieces of information are valuable for our research, but together, they obstruct one another. Using Python on a Google Colab notebook with the help of Gemini 2.5, we extracted the URLs from the summary column and placed them in their own column (see Appendix for code). After doing this, we were able to display the top 10 most frequently cited URLs within each dataset to gain a sense of the types of content that users use to ground their claims.
Step #3 Analysis of Topics
To look more broadly, we also applied natural language processing (NLP) methods using a sentence-transformer model and BertTopic to generate common topics among the notes by running the NLP on the text of the new summary column with extracted URLs. The specific sentence-transformer model that we used is a perfect match for analysis of CNs, as it is a multilingual model downloaded from Huggingface that can distinguish the various languages within our dataset and map both sentences and paragraphs (Reimers and Gurevych 2019).
After running BertTopic with a cluster size of 100 on the summary column of the first dataset (helpful CNs), we generated 147 topics across the whole dataset. Using the same cluster size on the second dataset (unhelpful CNs), we created 54 topics for the notes. Evidently, the topic modelling on the unhelpful dataset did not turn out to be as valuable due to the data being less rich. After all, these notes were deemed “unhelpful” for a reason.
Step #4 Matrix Analysis of Relationship Between Topic and Domain
While looking into the topics themselves is a useful form of analysis to gain an overall understanding of popular discourse themes, we can more thoroughly answer our overall research question on truth-construction by looking at the relationships between topics and cited domains. Doing this provides a means to investigate the ways in which contributors source their knowledge and see the variance in source credibility through different topics. Instead of looking at the URLs, for this step, we investigated the domains as there is less variance so it is clearer to see how different domains may or may not be used for more than one topic. We performed this analysis only on the helpful dataset as the unhelpful notes often lacked a domain altogether.
To single out the domains, we once again used extraction methods in Python to create a third column that included each CN’s domain in addition to the summary and full URL column. After this, we created another column that appended the topic name and topic number that was assigned to each note. Finally, we exported a trimmed version of the dataset as a CSV file that included only each topic and domain pair as two columns and only included the top 25 most common topics and the top 26 most common domain names (cut to 26,860 total helpful notes). The decision to trim the dataset came from our final goal of visualizing the data in a readable way as too many topics and urls would overcrowd any visualization. Once the CSV file was exported, we created a final data table that included each topic-domain pair only once with a third column that included the frequency in which that pair occurred within the trimmed dataset. This final data table was then exported to RawGraphs and used to create a matrix to showcase distribution.
2.2.3 Micro Qualitative
Based on a combination of findings from the macro approach and predetermined research interests, we studied user practices within the CN interface itself to provide greater analytical specificity lost in big data analysis. This in situ approach allows the researcher to analyze user practices as always already relational to 1) the affordances that manage the possibilities of users and 2) the discursive actions of other users. At stake in this analysis are a series of questions fundamental to making sense of CN as a discursive infrastructure that is only vaguely positioned by X. This serves a comparative function, where the alignment between the ideal use of affordances and actual user practices can be problematized. The questions attended to at this level of analysis are:
-
What do contributors imagine and use CN for? What function(s) do they see it serving?
-
What epistemic practices do contributors develop when writing notes in CN?
-
In the absence of peer-to-peer communicative affordances, how do contributors communicate with one another?
For the micro qualitative approach, a random sample of 3,000 notes was initially taken from the macro dataset in order to make manual sampling more feasible. This random sample consisted of 1,000 notes from each status (helpful, needs more ratings, and not helpful), with the intention to analyze a second, smaller random sample of notes for an element of representability. After arriving at several findings in the macro analysis, we abandoned the random sample approach for a more focussed analysis based on magnification rather than representation. Purposive sampling was then used to identify ‘information-rich cases for study in depth’ that spoke to findings in the big dataset (Patton 1990). Due to the size of the sample and the scope of the research, purposive sampling was chosen as a sampling method to illustrate tendencies and aberrations found in the data on contributor practices.
For each selected note within the subset, it was traced to its original X post and all the notes under that post were analyzed in tandem. This enabled a contextual and interactional analysis of the notes. This permitted different contributor practices to emerge under greater analytical scrutiny than the macro analysis would allow alone. To ensure the analysis captured communicative practices, posts that only had one CN under them were excluded. Notes were also excluded if the original post was deleted and if the language of the note was not English. We analysed all the notes associated with 20 selected X posts from the subset. This resulted in the analysis of 66 notes in total.
Through emergent qualitative coding (Strauss & Corbin 1990), we explored the micro-level practices of CN contributors. The coding scheme was first conceptualized during a ‘deep hanging out’ (Geertz 1998) with notes in the CN interface, initially aiming to identify domains of contributor practices. This resulted in two primary themes for analysis — Communicative and Epistemic practices. Communicative practices refer to linguistic forms of engagement and interaction between contributors on CN. Epistemic practices refer to performances of knowledge construction and legitimization within CN. The codes were then developed and refined throughout note collection and analysis, iterating between the research questions, field notes, and suggested codes. This emergent, iterative approach ideally allows the discursive objects themselves, notes in this case, to guide the researcher’s attention. The notes were further analyzed in relation to their alignment of practices with affordances (dominant, negotiated, oppositional) grounded in Shaw’s (2017) adaptation of Hall’s decoding positions. The final version of the coding scheme is detailed below in Table 2.
| Category | Code | Description / Subcategory | Options / Examples |
| 1. Formal Information | 1.1 | Post link | — |
| 1.2 | Note text | — | |
| 1.3 | Status | Published / Awaiting votes / Not helpful | |
| 2. Epistemic Practices | 2.1 | Source type | Primary / Governmental / News / Academic / Blog / Article / Wikipedia / X post/ Tools |
| 2.2 | Claim nature | Source based / Opinion / Speculation / Interpretation | |
| 2.3 | Correspondence type | Visual / Textual / Audible / Statistical | |
| 2.4 | Contributor framing of note | Context / Fact / Truth / Advice / Criticism / Unclear | |
| 2.5 | Implied purpose | Fact-checking / Enforcing X guidelines / Adding context | |
| 3. Communicative Practices | 3.1 | Contributor conversation | NNN / Policing / Affirmation / Play |
| 3.2 | Platform vernaculars | Terms or phrases developed and used by contributors | |
| 3.3 | Disputing purpose of CN system | NNN | |
| 4. Position to Affordances | 4.1 | Position to affordances | Dominant / Negotiated / Oppositional |
Table 2. Coding Scheme for Qualitative Content Analysis
2.3 Complications
On July 10, 2025, X took down the entire CN “About” and “Under the Hood” pages. This included several informational pages we had been using for both general context and in the Affordance analysis. While our analysis was mostly complete at this point, this page, titled “Under the Hood,” was a source of X’s self-described transparency about the inner-workings of CN. Specifically, it described in conservative detail how CN works on a technical level, including their algorithms for topic modeling users into ideological camps, the mathematics of the note ‘scoring’ system, and the logic behind contributor’s impact ratings. The old pages can be viewed in part via the Wayback Machine: https://communitynotes.x.com/guide/en/contributing/top-contributors
On July 15, 2025, we found that the CN website was back online. However, significant changes were detected that beg for further research. It appears that X introduced a topic modeling algorithm to pre-curate the CN written to a certain post to get rid of unrelated/ “unhelpful” notes. Regardless, the “About” section was down for five days with no explanation, which poses serious obstructions not only to researchers but to CN contributors.
3. Findings
3.1 Affordances
Using Stanfill’s (2015) method for discursive interface analysis, our analysis of CN’s affordances yielded insight into the architecture of power that contributors operate within when performing knowledge-work. In conversation with the affordances and their relations to one another, we saw three main categories of discourse emerge. Specific affordances are grouped into the categories Performance, Feelings, and End Product below. The category “Performance” refers to how users are expected to behave in the platform, while “Feelings” captures the emotional responses that are triggered through the design. Together, these two categories produce a feedback loop wherein the consent of the contributor is cultivated and stabilized. When consented to, X’s preferred subjectivity of the contributor emerges, allowing for the production of an ideal End Product - a note which operates within and reflects X’s mechanisms of containment for public discourse and knowledge production.
3.1.1 Performance
While all affordances exercise power over a user’s performance, they do so to differing degrees and such power manifests in myriad ways. The affordances listed in this section all correspond to Stanfill’s (2015) definition of functional and cognitive affordances. Thus, the performance of the contributor is in part predetermined by X which, when it corresponds with the preferred use of the affordance, marks the ideal performance as designed by the platform. CN’s affordances drive users to perform note-production in line with X’s aims. This performance reproduces and reaffirms the feelings produced by CN’s messaging, driving one side of the consent cycle. The ideal performance is marked by the themes below.
Figure 1. The anonymity of the contributor is performed and constructed through a pseudonym.
Anonymity: CN necessitates the disconnection of contributors from their platform or offline identities through a pseudonymized profile (fig. 1). While this is likely designed to mitigate personal attacks on individual contributors and encourage note-writing practices that might be seen as controversial. More specifically, the anonymous self is characterized through metrics like ‘impact rating.’ However, there is no transparency regarding how impact or visibility is measured, nor how one’s algorithmic score is calculated. Users are expected to carefully build and maintain their profiles, creating a form of identity that requires ongoing, attentive labour. While this process is framed as a form of freedom, it in fact demands alignment with the platform’s implicit rules and norms. This tension between freedom and control reveals how power operates subtly through the interface, enforcing control through the illusion of freedom.
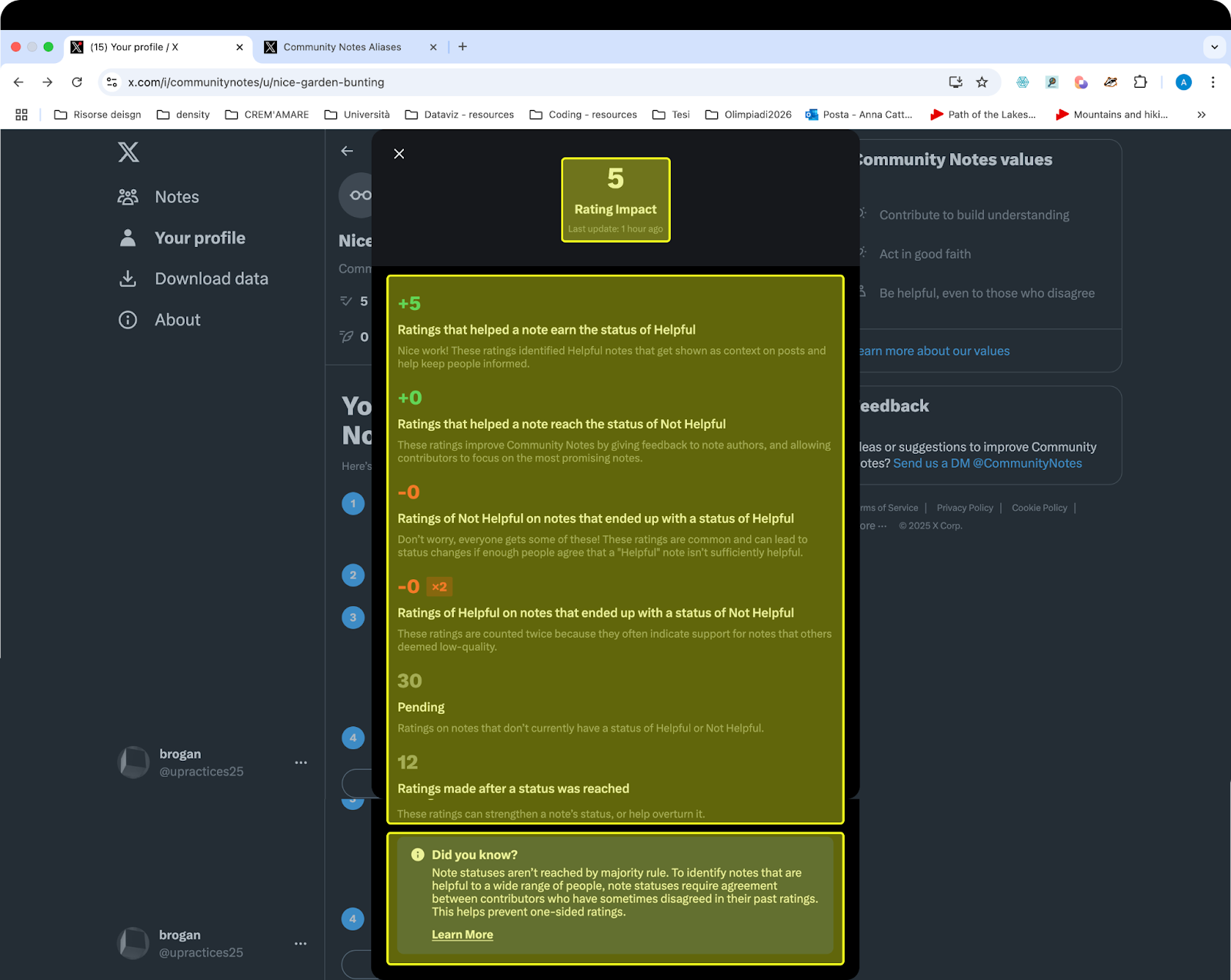
Figure 2. The profile page of a contributor where their performance is transformed into improvable metrics.
Continuous improvement: CN turns participation and discourse into a gamified performance through machine-readable metrics and impact scores (fig. 2). This sustains engagement by quantifying users’ impact and encouraging them to optimize their scores, always in competition with other users for greater voting power on notes. Impact scores are earned by writing and voting on notes that are eventually determined ‘helpful’. Indeed, the higher a contributor’s impact score, the more their vote counts in the note appraisal process.

Figure 3. Description of the “Top Writers” classification in CN’s “About” pages.
Competition between individuals: Similarly, the “Top Writers” system (fig. 3) fosters competition by rewarding individual performance with exclusive access to certain perks, such as attaching the same note to multiple related posts, access to viewing CN requests by users, and a badge in their profile. Rating impact scores and progress tracking encourage continuous self-optimization, explicitly giving contributors an exclusive status to work towards.
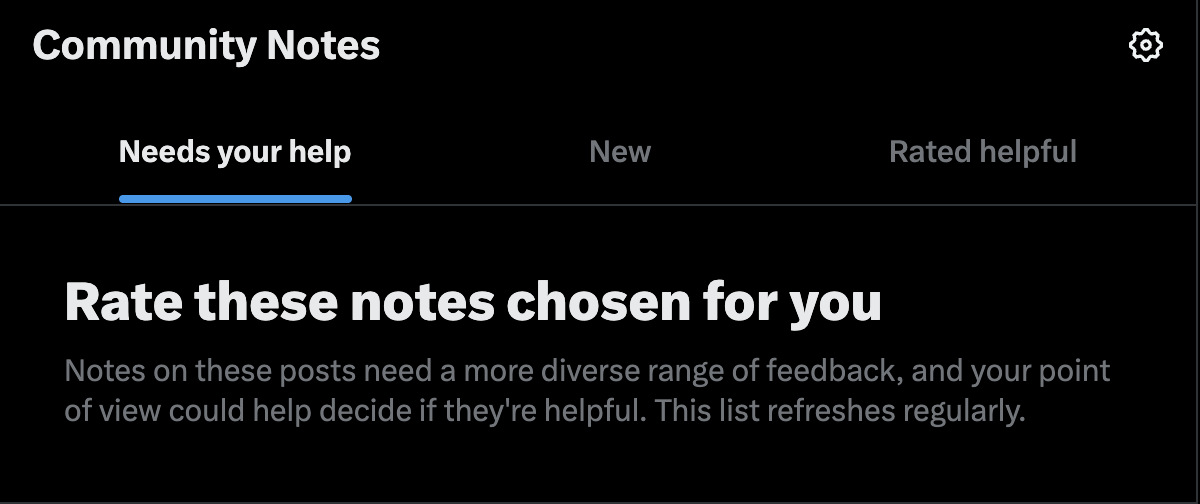
Figure 4. An instance of CN’s cognitive affordances that discursively place emphasis on the role of the contributor.
Onus on “You”: The platform centers the individual as the epistemic authority, making “you” responsible for fairness and truth (fig. 4). This shift towards the user-as-expert rouses disparate individuals to act on the platform, contributing to a “better informed world” (X 2025). By framing the issue of knowledge validation as the responsibility of the user, the actual workings of the system remain hidden and unaccountable. Indeed, the crowdsourced system does not (currently) work without contributors.


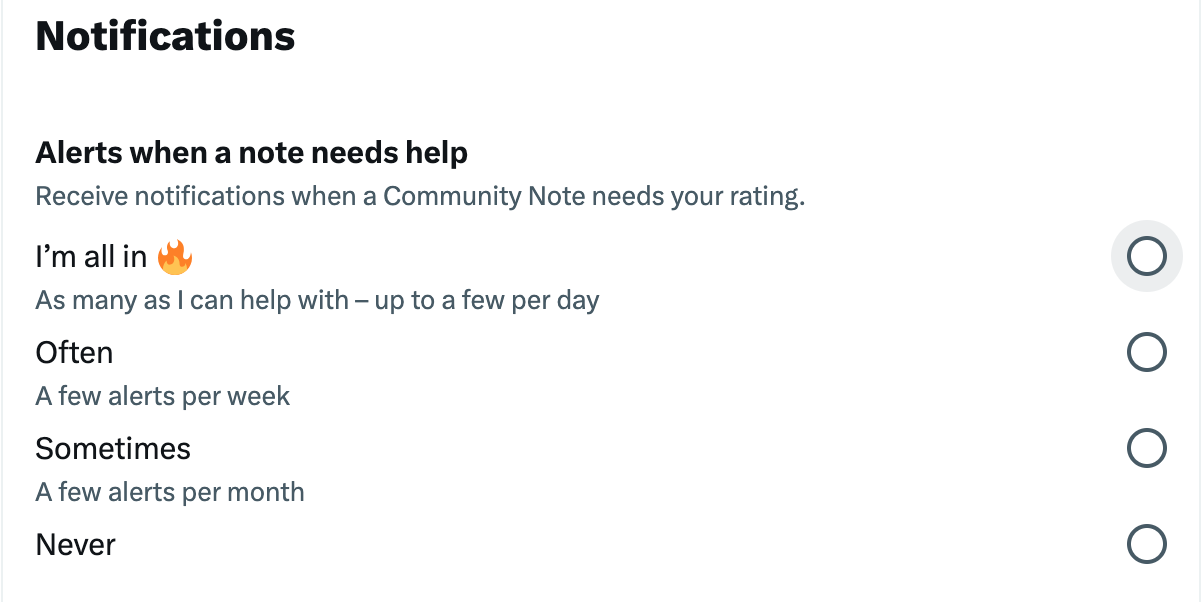
Figure 5. Affordances which set the pace of CN contributors.
Urgency and efficiency: Affordances such as timestamps and push notifications implicitly create a sense of urgency and efficiency (fig. 5), pressuring users to act quickly, contribute promptly, and stay up to date, reinforcing the platform’s pace and control over participation. More specifically, being up to date is presented not simply as useful but as necessary. Users are made to feel that if they want to stay relevant, they must be present. This expectation creates a condition of constant engagement, where users are encouraged to return frequently, monitor activity, and continue contributing. For example, notification options include the phrase “I’m all in,” accompanied by a fire emoji and the word “Help”. This combination nudges users toward that option, especially as it is positioned first. In this way, the platform embeds itself in users’ everyday routines and secures the ongoing participation. This indicates a preferred temporality to contributors’ subjectivities on the platform.
3.1.2 Feelings
In addition to affordances that actively manage the active performance of contributors, CN’s affordances also produce a range of feelings that urge contributors to act in ways preferred by the platform. These feelings motivate certain contributor practices, just as certain practices reproduce specific feelings that keep the contributor engaged in the process.
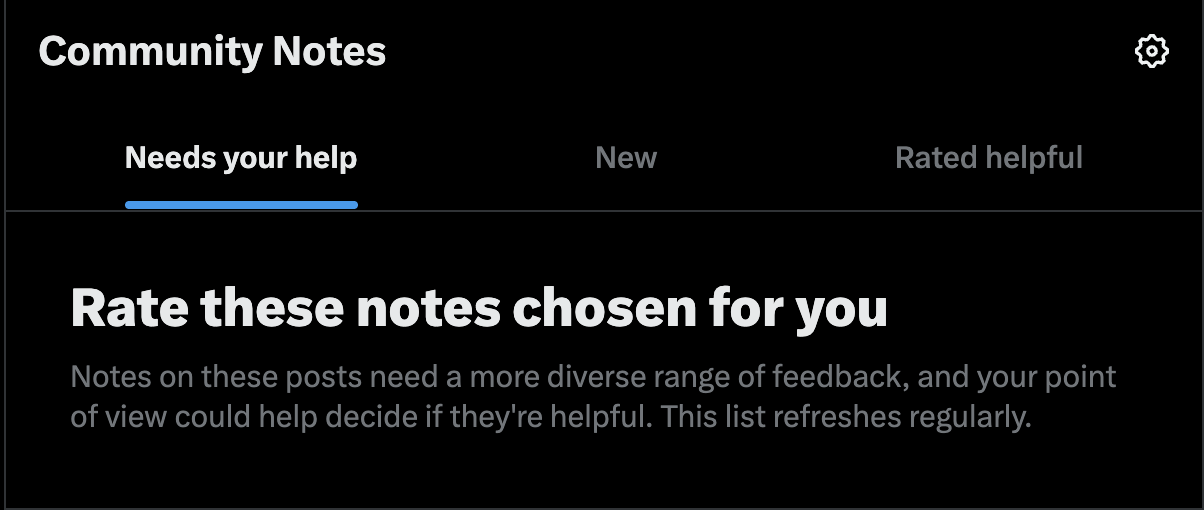
Figure 6. The CN ‘newsfeed’ in which the contributor’s perspective is valorized in order to act on posts or notes that X pushes to be rated.
Validation, sense of importance: Certain affordances cultivate a feeling of validation and importance by making users believe their input is crucial to fostering engagement while masking the platform’s underlying power dynamics (fig. 6). The feelings produced by such affordances operate in parallel to the performance demanded by the system. In this case, the same affordance is both functional and cognitive; for a contributor to perform as an individual, they must feel empowered and important within the broader system.

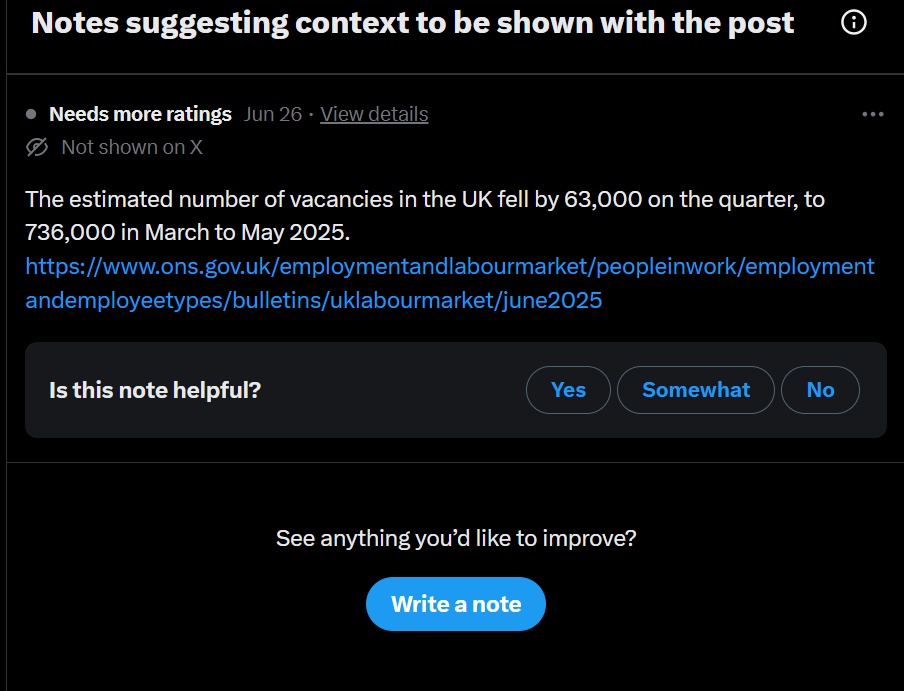
Figure 7. Functional and cognitive affordances that promote X as a trustworthy platform.
Trust: Trust is manufactured by making the platform appear neutral, transparent, and user-determined (fig. 7). By promising non-intervention, promoting openness, and emphasizing that it’s all about “you,” contributors feel empowered while X’s own role and influence are rendered invisible. While data is also technically made available, interpreting it requires a high level of technical literacy, which limits meaningful access and undermines true transparency. The interface plays a crucial role in producing this trust. By receding into the background, it reinforces the illusion that the user is fully in control. This subtle design choice, where the platform appears to step back, contributes to a sense of neutrality and transparency that makes users more likely to trust the system. The lack of visible mediation supports the belief that what is happening is user-driven. This invisible interface reduces opportunities for critical reflection on the platform’s underlying logic and ideological framing. As a result, CN can be perceived not as a system of governance but as a neutral mediator, a trustworthy mechanism that simply reflects user consensus.
Figure 8. The language of the interface frames CN as a communitarian endeavor.
Illusion of Community: A sense of “community” is promoted through the language of the interface (fig. 8). However, this remains purely discursive and is not supported by the platform’s functional affordances - for example, the lack of an affordance for peer-to-peer communication. Subtle linguistic choices, such as “better informed world,” “just like you,” and “collaboratively,” cultivate the sense that the user is contributing to something larger than themselves, establishing an imagined community.
3.1.3 End Product
The intended Feelings and Performances produced through X’s design of its affordances make possible the production of notes and the management of public discourse in line with the ideal use of the platform. The End Product, meaning the note itself, appears communitarian, organically occurring, transparent, and ideologically neutral, while in fact being largely predetermined and automated by the platform’s affordances. This manifests in several interconnected themes.
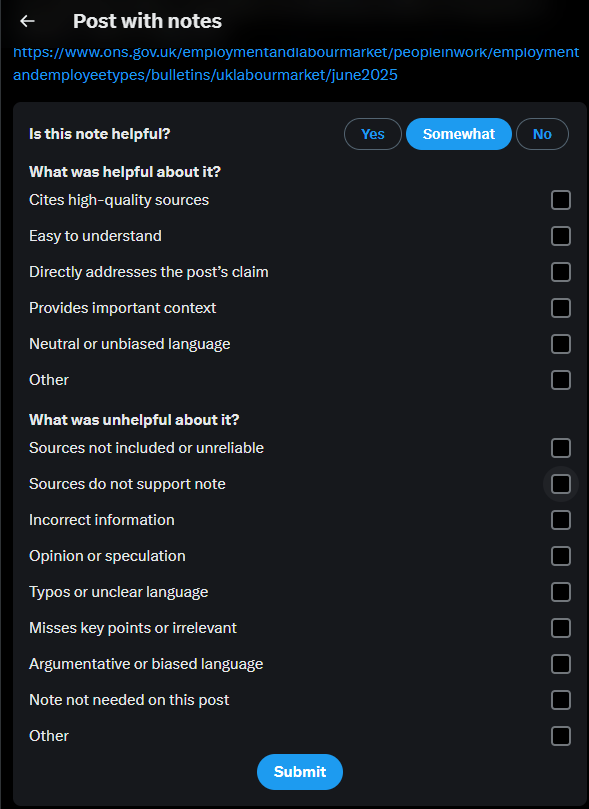
Figure 9. Predefined criteria as check-boxes given to contributors to rate the helpfulness of notes.
Discourse via Predetermined Categories: By defining fixed categories for note evaluation via voting (see fig. 9), the platform retains control over how quality is measured, guiding users’ judgments and shaping what counts as helpful or unhelpful content. Such predefined voting procedures replace public conversation, converting discourse into discrete datapoints that are automatically registered and functionalized through the algorithmic scoring system. Instead of conversation, X prefers automation. Even the “other” option is constrained, offering no space for users to elaborate or justify their choices. This limits user expression and reinforces the platform’s control over acceptable forms of input and reasoning.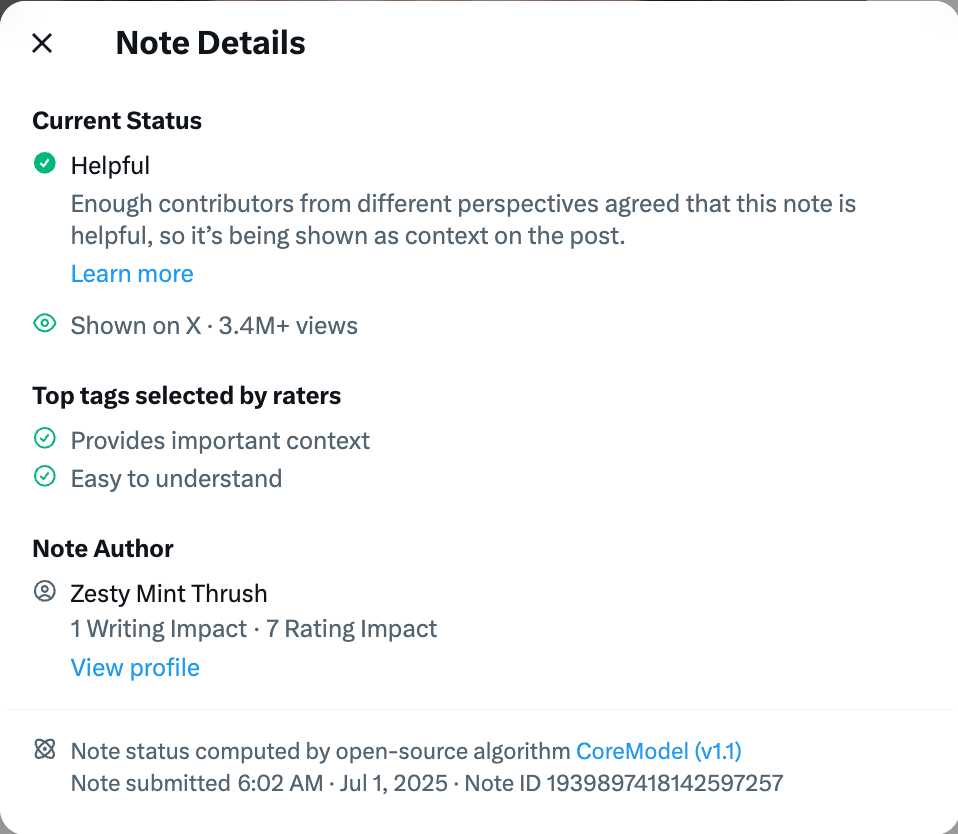
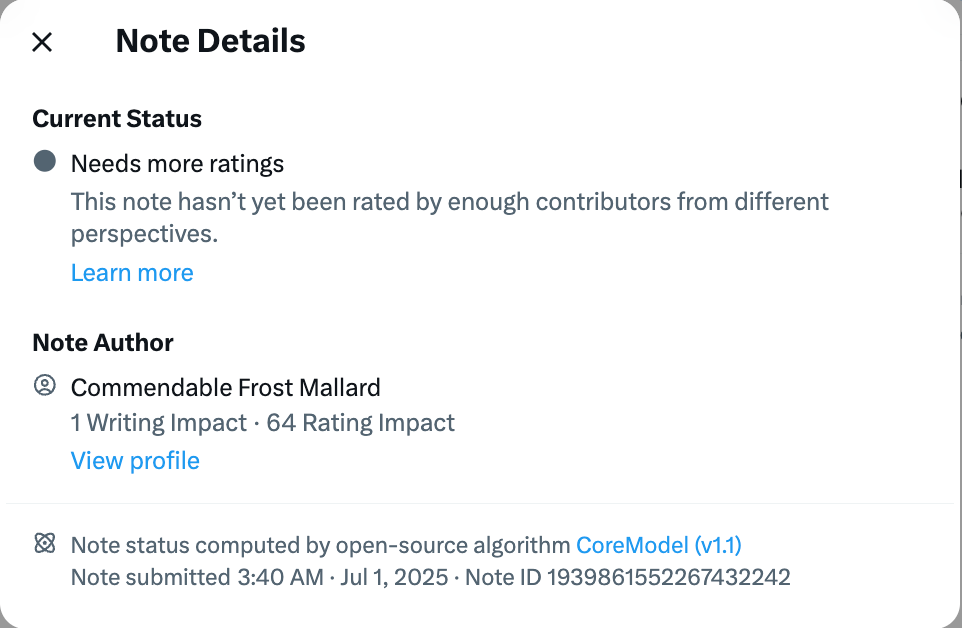
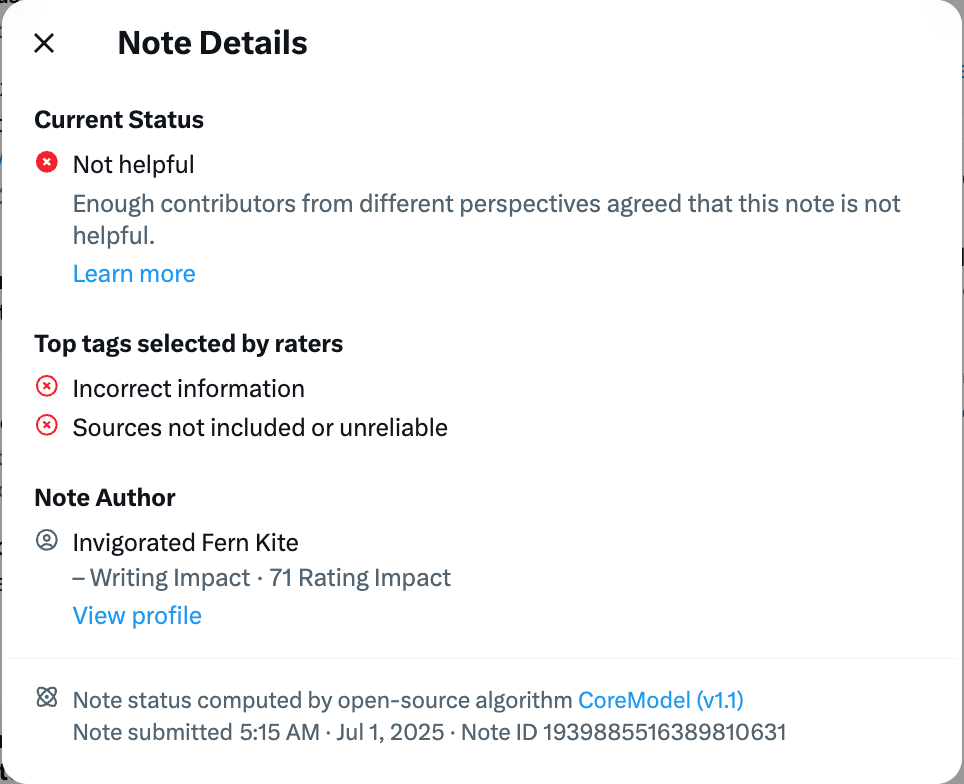
Figure 10. ‘Note Details’ boxes provide information on a proposed note, such as its Helpfulness status, without illustrating how or why it has been rated a certain way.
Transparency: The interface creates a sense of transparency where outcomes feel known and justified (see fig. 10), but it obscures the actual processes and criteria behind judgments, offering a performance of clarity rather than genuine explanation. CN’s computational architecture is both complex in itself and creates complex information systems that algorithmically filter user input into machinic output. Such a disjunction between a faith in algorithmic neutrality versus an actual understanding of CN’s complex mechanisms allows for the illusion of objectivity produced through machine-assisted crowdsourced practices.
Figure 11. CN is discursively framed as a communitarian endeavor by cognitive affordances in the interface, while there are no functional affordances that support such a narrative.
Neutrality via Community: The end-product appears neutral and organic by framing the published note as the outcome of crowd consensus (see fig. 11). The feelings of ownership over the process, and performance of note production, convinces the contributor of their agency and cooperation. Framing CN as a communitarian endeavor hides the platform’s own role in shaping the mode of discourse and truth-production - especially given that there are no functional affordances which support community - obscuring the ideological nature of the infrastructure itself.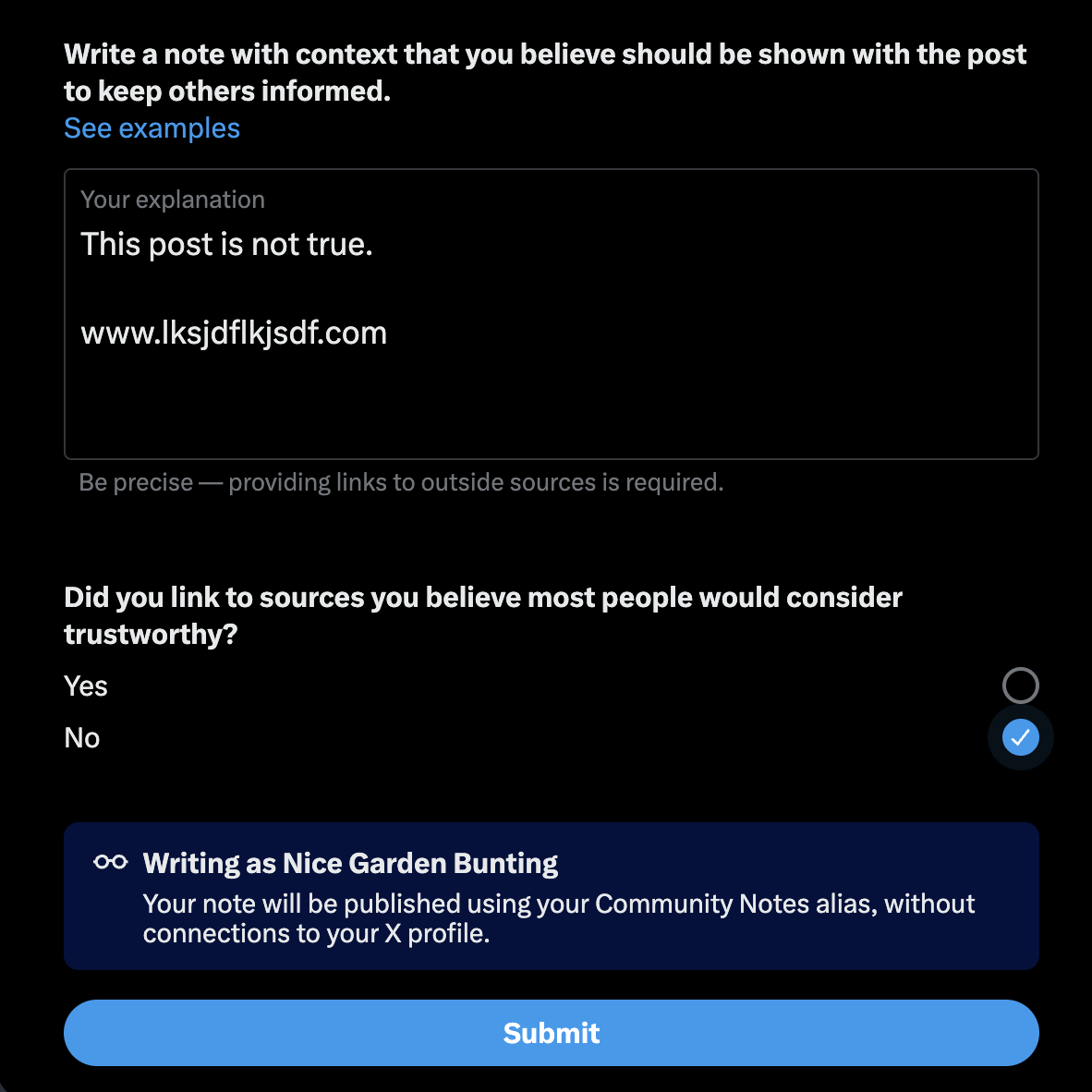
Figure 12. The note-writing interface where a URL to a ‘source’ is required to post, regardless of the URL’s liveness.
Illusion of Objectivity: CN requires that a contributor links to an informational source when proposing a note that contests the validity of a post on X (fig. 12). Such a requirement seems sensible when asking diverse contributors to support their claims. However, this affordance allows nonexistent or broken URLs to be used when publishing a note. The interface also asks contributors if their source would be considered trustworthy to the general public, rendering the nature of a given source ultimately interpretative. This referential freedom permits contributors to use sources to their liking, producing a reciprocal trustworthiness; if the platform trusts the individual with such agency, then the individual should trust the platform. Simultaneously, the requirement of a source gives notes the appearance of objectivity, transparency, and professionalism. But without enforcement over URLs actually functioning, this is only a superficial guise.3.2 Macro Approach
Upon initial Macro data analysis, we noticed that the Helpful dataset (published notes) provided more clear correlations and themes of contributor practices and use of the CN’s affordances. The Not Helpful dataset showed inconsistent use of, if any, citations– a requirement for notes to get published (X 2025). When we applied topic modeling methods, the model was unable to produce meaningful results due to the very few consistent thematic overlaps in terms of language and keywords. On the other hand, the findings of the Helpful dataset were contextually rich, showing a clear use of citations and specific topics. This demonstrates that contributors seemed to be eager to write a note that ultimately resulted in enough ratings to get the note published. The following findings therefore present clear correlation and connections towards user practices that seem to be considered as successful/helpful concerning connections of themes and sources on a macro level.
Our initial comparative analysis of the URLs in both datasets demonstrated interesting results. Both helpful and unhelpful notes included a significant majority of sources cited from within X itself. For the Not Helpful dataset, this was often the CN guidelines themself or other social media posts that are treated as primary sources rather than more traditional citations, such as news articles (fig. 13). For the Helpful dataset, this came in the form of X’s policy guidelines on scams and other monetary policies (fig. 14). In both cases, these findings demonstrate the containment of truth production to the platform itself. The practice of citing X’s policy guidelines exemplifies that contributors undergo the labor of moderation that X no longer does themselves (this problem has faced drastic increases as X has “slashed its content moderation team”), rather than the fact-checking and contextualizing that X claims that CNs are designed for (Jude and Matamoros-Fernándes 2025, n.p; Alba and Wagner 2023, n.p). Not only do contributors do this by referencing X’s guidelines, but they also reference external sources on avoiding scams and why scams are dangerous, demonstrating that these contributors internalize X’s policies and engage in the reproduction of the guidelines as a moral compass.

Figure 13. Top 10 Linked Source Domains within the Not Helpful datasets

Figure 14. Top 10 Linked Source Domains within the Not Helpful datasets
When we extracted the domains from the urls, performed topic modeling, and visualized the comparisons with the Helpful dataset as a matrix, we saw a similar abundance of links to social media platforms such as X, Instagram, Tiktok, and Youtube (fig. 15). This reinforces the finding that contributors practice truth construction within the boundaries of digital social media space and that the “public sphere” narrative that Elon Musk and X’s guidelines attempt to advertise may be more constrained by hidden power dynamics and norms.
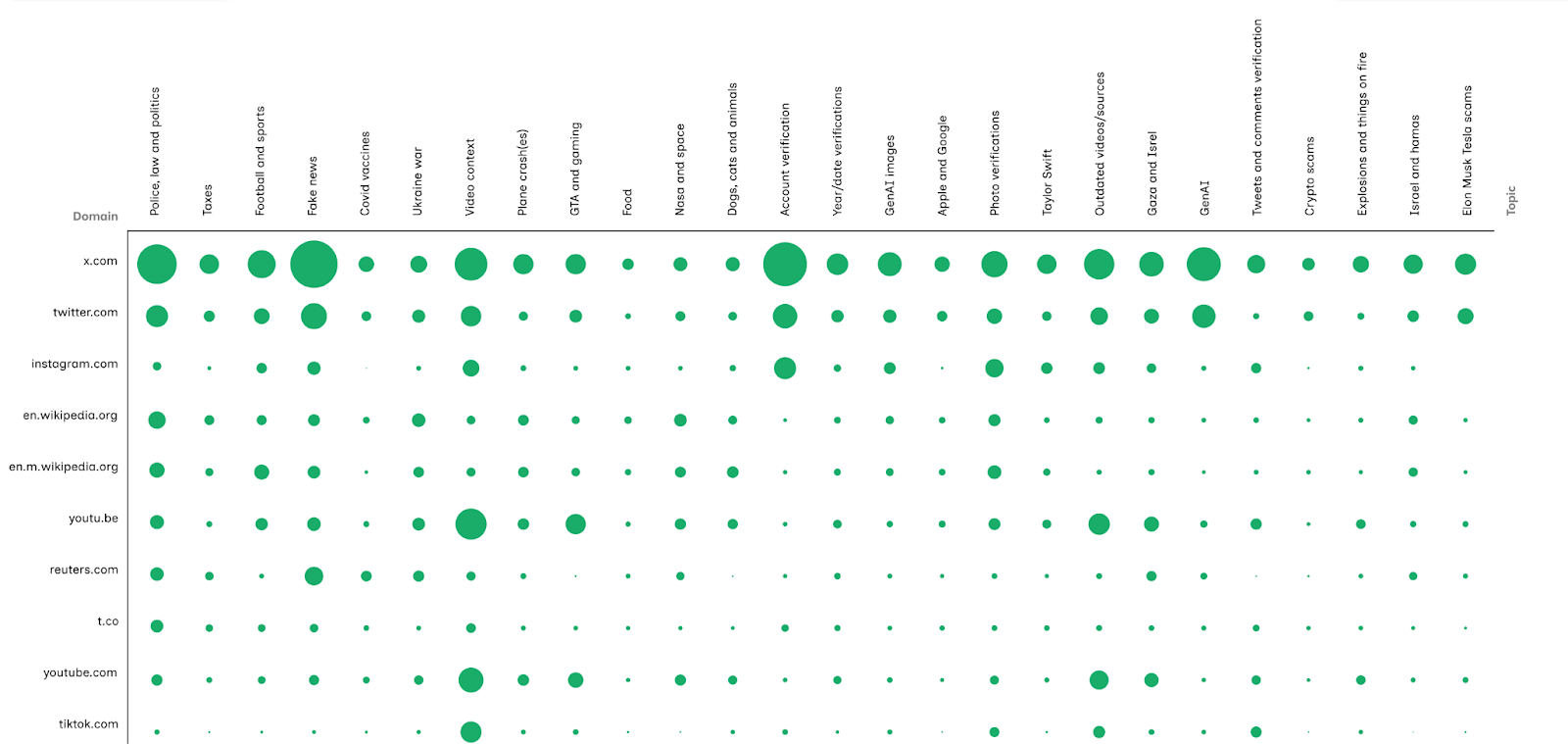

Figure 15. Matrix of the Domains Cited Across the Top 25 Topics in “Helpful” Community Notes
When we look into the topics that emerge from natural language processing and topic modeling, the most populous topics are police, law and politics, taxes, and football and sports. This is not surprising as these topics are some of the most divisive and popular topics historically organic to Twitter and now X. Similar to the URL analysis, the topic modeling also suggests that contributors are undertaking the practice of content moderation. Many of the top 26 topics include themes of scams, fake news, and verification. When we compare the top domains to the topics in a matrix visualization, we can see that contributors tend to use the same domains across all topics (Figure 15). This indicates that the source itself most likely does not matter as much as having a source matters. This echoes the findings from the URL affordance in which some of the URLs don’t actually link to a functioning web page. Furthermore we identified oddly specific hubs surrounding Taylor Swift, the game GTA, NASA and space or Explosions and things on fire. These identified top topics suggest that many note contributors do (potentially) exercise their note writing practice within specific thematic hubs. For example, as a self proclaimed expert on Taylor Swift truth production becomes more than correcting news facts but rather giving context to their favorite topic as an act of fandom.
Overall, these macro findings provide a comprehensive and complementary overview that examines the findings from the initial affordance analysis and lays a foundation for a qualitative close reading of the practices within the CN environment.
3.3 Micro Qualitative
The micro qualitative analysis allowed for a nuanced and immersive insight into how CN contributors negotiated and engaged with the intended affordances. Users appeared to understand the use and purpose of CN differently, and we observed both dominant and negotiated uses through which they enacted their understandings. Six cases are identified under two dominant themes: communicative and epistemic practices. The findings of this micro analysis are presented below.
3.3.1. Communicative Practices
The micro qualitative analysis revealed that there were explicit forms of communicative practices amongst CN contributors through a misuse of the note-writing affordance. To begin with, we observed elements of comedic, antagonistic, and playful practices where the affordances of CN were used by contributors in ways that did not align with their intended purposes. This was most apparent in the communicative practices of users that hinted towards the creation of an in-group formation. This negotiated use was exemplified in different ways, for instance through communal humor, the internal moderation of the notes themselves, and playful correspondence. Our data suggest that vernacular communities emerge around specific communicative practices internal to CN.
Communal humor
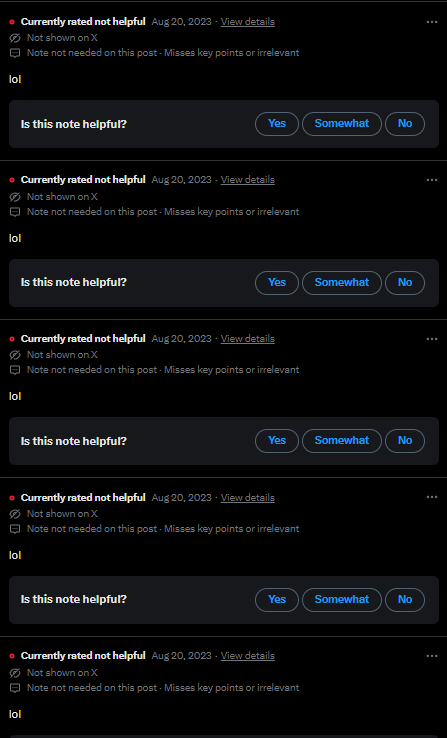
Figure 16. Repeated use of “lol” by contributors.
In Figure 16, the repeated use of CN by different contributors to post "lol" suggests an attempt to create a sense of community and perhaps alludes to an ‘in-joke’. This stream of repetitive, waggish responses is reflective of comedic, communal vernaculars one might see on Reddit. These contributions appear to function more as a gesture of humour rather than adhering to the CN goal of adding context to misinformation. However, all the "lol"s were voted as ‘Not Helpful’ by others, which may not have been unexpected by the contributors themselves. This could indicate that other contributors wish to uphold the values of CN and therefore do not think this is the correct way to utilize the CN affordance. Alternatively, this may represent a bid by contributors to keep the humour private within CN, therefore engaging in a performance for the internal audience. In the absence of peer-to-peer affordances within CN, contributors are using the notes themselves to communicate, negotiating the intended purpose of the function.
Intra-contributor policing
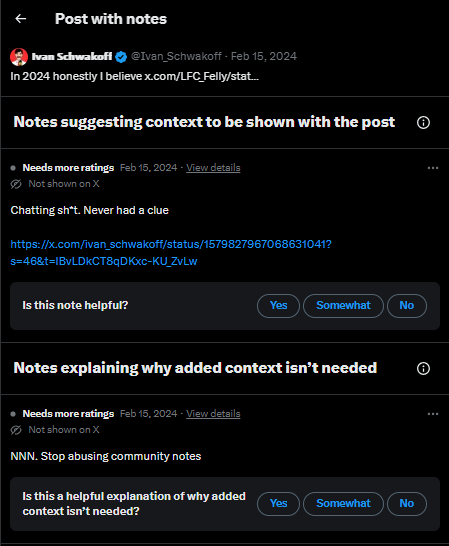
Figure 17. A contributor policing another via the note-writing affordance.
Figure 17 illustrates a communicative practice where users disagree on the purpose of CN and attempt to police one another. Since there is no affordance for peer-to-peer communication, contributors use notes to counter notes that they see as problematic. The top note in this figure is an example of a user expressing a crudely phrased opinion, which is countered by a response from another contributor below. The use of NNN (No Note Needed) is a platform vernacular commonly used in our collected data which is derived from a CN note-voting category. This demonstrates that not only do some contributors feel responsible for protecting the X public at large, but doubly aim to protect the integrity and imagined purpose of CN from contributors who ‘misuse’ it. Without any form of top-down moderation of proposed notes by the platform, the responsibility of policing the system falls on contributors. Thus, we see the emergence of ‘vigilante’ contributors who negotiate with the affordances to construct and maintain order.
Playful practices
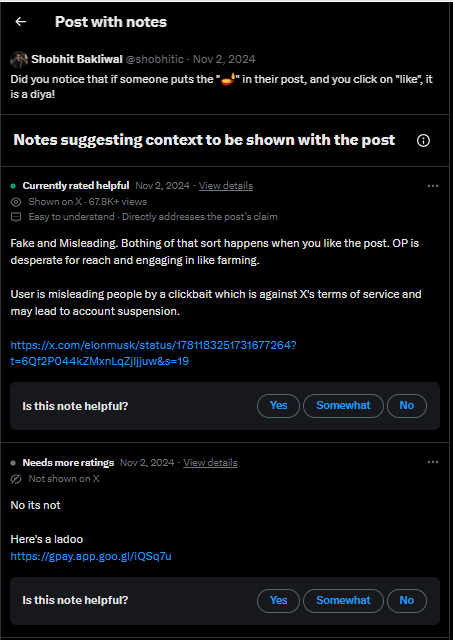
Figure 18. A contributor playfully misusing CN’s URL affordance to link to their Google Pay account.
In Figure 18, a contributor challenges the validity of a post but does so by misusing the URL affordance in note-writing to link their Google Pay account rather than an informational source. The top note, which is “Currently rated helpful,” elaborates that the post in question is deceptive and opportunistic. The bottom note is also a retort to the post, dismissing it without evidence or elaboration but offering a ladoo (a traditional Indian sweet) via Google Pay instead. While the motivation of the bottom note’s contributor is unclear – whether this is a bribe, joke, or attempt to bond – this misuse of CN’s affordances is playfully spontaneous, irregular, and ambiguous. This instance is one of the closest to a contributor sharing their off-CN identity that we encountered in the data; it is highly personal, interconnective, and creative in its negotiated use of CN’s affordances, revealing not only clues about the contributor’s cultural identity but also the quiet possibilities for interaction within the interface.
3.3.2. Epistemic Practices
This section presents the epistemic practices developed by contributors when using CN, which includes how they present or justify knowledge and how they negotiate the epistemic territory of the CN affordance itself. There were disagreements amongst contributors regarding purpose, sources and authority, clear differences amongst contributors with respect to what they considered as a high quality source. The mere existence of a hyperlinked text seemed to give the CN a certain amount of legitimacy. This was apparent when users added sources at the bottom of the text that were not linked to their claim at all. However, the placement of the hyperlinked source seemed to add, at least visually, a sense of legitimacy.
Purpose of Community Notes
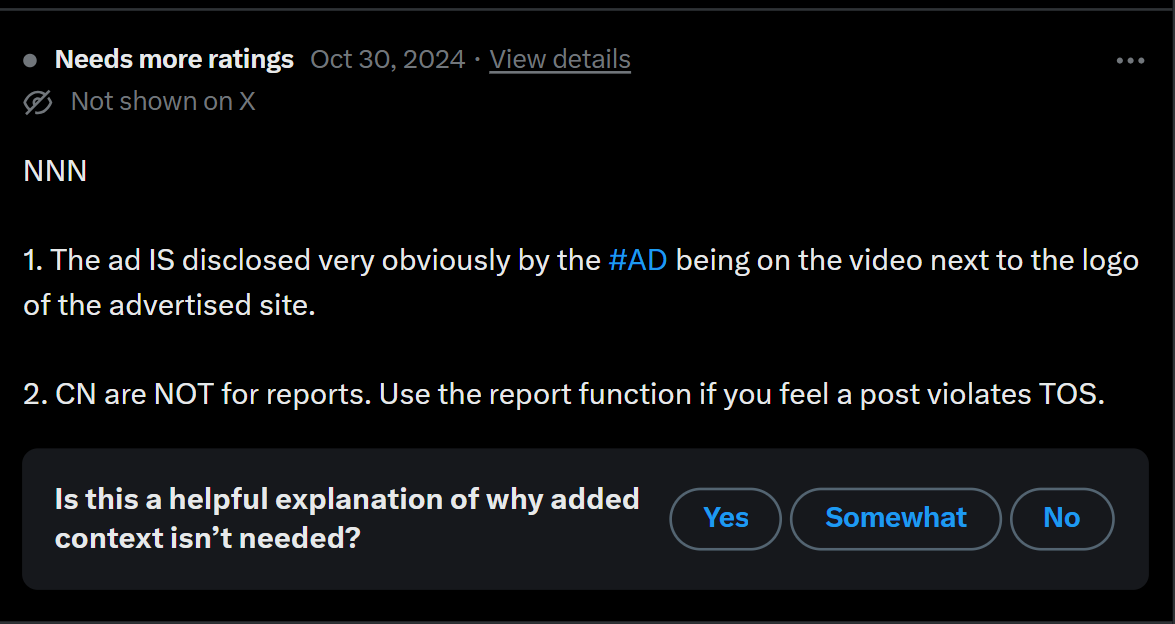
Figure 19. Debate over the purpose of CN.
Figure 19 demonstrates a form of divergence within CN, where contributors understand the epistemic territory of the CN affordance differently. In this case, some contributors use CN to enforce X guidelines. This note explicitly responds that “CN are NOT for reports” clearly identifying how the epistemic boundaries of CN are perceived by this contributor. This contributor justifies this boundary by referring to a separate affordance (the ‘Report’ button), which they believe is more suited to the task of moderating posts that violate X’s Terms of Service. Such notes often include “NNN” and an explicit articulation of why using CN as a moderation tool is inappropriate. This reveals dissensus within the contributor community over the role and limits of CN, indicating a competition between infrastructural imaginaries. Future research could attend to the levels of cohesion and success in these imaginative publics.Source-based epistemic practices
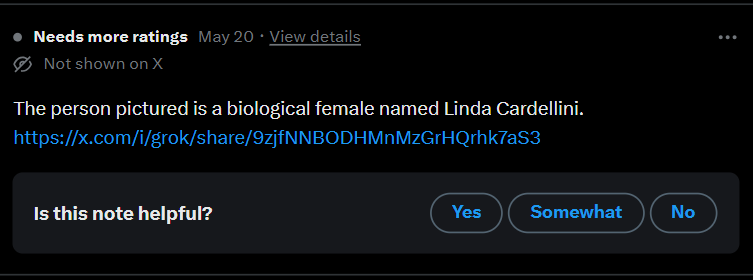
Figure 20. A contributor using X’s chatbot Grok as a source to contest a post.
Figure 20 depicts a contributor referring to Grok (X’s proprietary chatbot) as a source to contest a post questioning the sex of an individual. While the most-used sources in our dataset tend to link to journalistic, institutional, or expert information, other users refer to primary sources (typically social media posts) or X’s guidelines. Instead, this contributor uses xAI’s chatbot Grok to evidence their claim. This corroborates a growing cultural faith in chatbots as expert knowledge-producers (Cheng et al. 2025). This is especially troubling in the context of Grok which has been finetuned to counter authoritative and so-called ‘woke’ positions. In the context of CN, this example indicates contributor inconsistencies in not only the political nature or trustworthiness of a source, but onto-epistemological disjunctions in the nature of that source’s production. Our data shows this practice gaining popularity amongst a small number of contributors and should be studied in future research.
Nature of claim
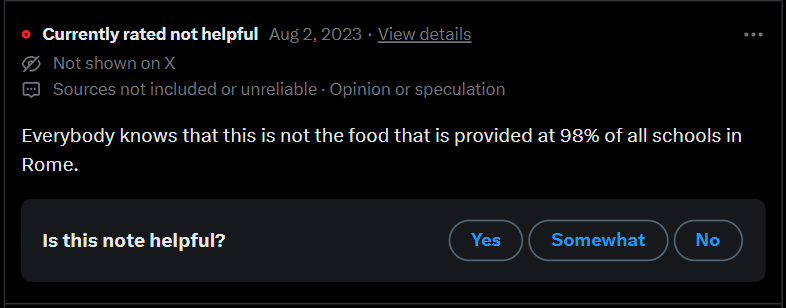
Figure 21. Implied consensus claim
In Figure 21, the contributor demonstrates an epistemic practice wherein they frame their claim as common sense. “Everybody knows” implies this information is self-evident and universally accepted. This claim provides no sources and instead relies on an implied consensus, thereby defying the contributor guidelines of CN and reflecting informal epistemic practices. This note is currently rated ‘Not Helpful’ due to the lack of sources used and it being opinion or speculation. This indicates that such claim types are not highly regarded by other contributors within CN and that there is a value placed on sources and objectivity.
Discussion
Our analysis of CN’s containment of crowdsourced knowledge begins with its design of affordances, which indicate its ideal use, contributor, and end-product. We identify two levels at which the system intervenes on public discourse and knowledge production. The first is on the level of Performance, where contributors are urged to operate with anonymity; every action sediments in continuous improvement, individual contributors are rendered competitive, responsibility for verification lands on contributors, and a temporality of efficiency-as-urgency is set. The second level is that of Feelings, where the contributor is meant to feel important, the platform trustworthy, and the operation of CN ultimately communitarian. While categorized individually, these two levels are inseparable from one another; they combine to equate the quantified epistemic value of the contributor with the virtue of an informed world. They cycle into one another endlessly, producing a feedback loop that constructs the ideal, hegemonic subject of CN: the Powerful, Capable, Superior, Helpful, and Datafied Individual.
Through this individual who trades their agency for a sense of power, CN is able to define and limit the boundaries of public discourse and knowledge production to correspond with the capacities and interests of the platform. For one, X only vaguely defines the purpose of CN: “to add context” to posts in order to “create a better informed world” (X 2025). By leaving open the purpose of CN to its contributors, but limiting their possibilities with its affordances, X is able to discursively leverage its contributions to public epistemology with a high degree of flexibility. Secondly, CN transmutes public discourse into predefined, standardized, and predictable possibilities for relationality. Instead of offering a chat-function for contributors to work out ‘truth’, CN deploys a system in which crowdsourced knowledge and public discourse is always proxied by automated and algorithmic components of a machinic infrastructure. While this certainly sounds like an efficient way to manage a complex system, it is not transparent, neutral, objective, communitarian, or decentralized. Lastly, through its affordances, CN is able to both construct a sense of and redefine the notion of ‘community’ in one swipe. Through the feelings produced via CN’s discourse, and the performance which validates the contributor’s input, a sense of belonging and benefaction is produced. If “community” consists of anonymous, competitive, self-optimizing, and automatically-proxied individuals, then this is it. Such depersonalization conflates “community” with the concept of the “public”, which, according to Tarde (1901, 395-396), is a “purely spiritual collectivity, a dispersion of individuals who are physically separated and whose cohesion is entirely mental.” Whether intentional or not, CN’s narrative of community is one that allows for greater, centralized management of its ‘free’ and anonymous constituents. The question then arises around the alignment between CN’s ideals and the actual subjectivities and practices of its contributors.
Our findings from the affordance, micro, and macro analyses of how CN contributors navigate their relation to the system suggest three main emerging practices. The first illustrates that contributors connect and apply truth to media sources. While the success of a note is closely tied to the attached source, as suggested by the CN interface, the content behind the URL does not have to be connected to the topic of the original post, be truthful, or refer to a reliable source, such as an academic or validated journalistic source. The macro findings especially suggest that sources mostly refer to content on X itself or cross-reference other posts across social media platforms, such as YouTube, Instagram, or TikTok. Using sources, especially material from media, is one of the main characteristics of fact-checking online and in what Schudson (1997) calls “democratic conversations.” However, what seems reliable becomes obscured. Rather than referencing reliable journalistic articles to fact-check tweets, the visual presentation of any source seems sufficient for a helpful note to emerge. We can speculate that the labor of fact-checking, or fact-checking the fact-check, circles back to the problem of scale concerning content moderation. This problem appears to not be solved by the practice of users or the affordances of CN on X. Regardless of a source’s domain or veracity, the nature of a URL dictates that any source it links to will be digital – that is, knowledge production and verification is confined to the internet. The idea that something is not verifiable if it is not hyperlinkable, and its implications on the ‘public sphere’, should be pursued in further research.
Second, although X refers to and uses the term “community” when talking about note-writing practices, actual communication between contributors is not intentionally afforded. However, the second practice shows a ‘misuse’ of the CN writing affordance. Since contributors cannot comment on or discuss written notes, they write new notes as specific replies to existing ones. This practice can be seen as contributors' resistance to the ideological limitations posed by CN and its interface. It is a way for them to reclaim the basic affordance of proper community interaction. Rather than rating a note and sorting it into one of three categories—”helpful,” “not helpful,” or “somewhat”—the “misuse” results in actual interaction and negotiation. This provides a basic level of communication that is not obscured by a black box rating/ranking algorithm. New forms of communication and language use emerge as platform vernaculars (Gibbs et al. 2015), such as writing “NNN” to mean “no note needed.” Our micro-analysis of practices also indicated myriad goals that contributors have in note-posting. While some act with faithfulness to X’s guidelines, others explicitly negotiate with their agency and the affordances they are given to play, troll, invest socially, and police certain topic domains.
The third and final practice could also be classified as potentially misusing CN. Contributors take on the role and function of moderators. Crucially, this moderation takes place at two distinct levels. The first level can be seen in the moderation of X posts themselves and on the second in intra-contributor moderation practices. Rather than verifying facts, contributors, as demonstrated in the micro and macro analyses, often refer to X's Community Guidelines and policies. Concerning the topic of scams, which was also identified during topic modeling, contributors refer back to the Community Guidelines in the helpful notes, not to fact-check, but to tag posts that breach X’s Terms of Service. The Community Guidelines and written notes state that such posts are not allowed on the social media platform. Here, contributors do not fact check, but rather moderate content prohibited by the platform, suggesting the internalization of proprietary norms. Here, the platform’s guidelines serve as an authoritative source for contributors to enforce their own normative compass and imaginary of the ‘public good.’ In this category especially, it appears that there is fractured consensus on the purpose of CN and how it should be used; indeed, the function of “adding context to misleading posts” (X 2025) is open to interpretation. In the note-voting interface, contributors address these notes and often write "NNN" because some do not consider this practice appropriate for CN. However, this seems to be one of the major practices that often results in published notes. Concerning the affordance analysis, X's vision of CN does not emphasize the use of notes as a moderation technique – quite distinct from a fact check – because, in theory, X is supposed to moderate such posts. However, it appears that the platform fails to do so considering Musk fired 80% of the platform’s Trust and Safety team in 2024 (Brewster 2024), and many contributors try to enforce X’s guidelines by pointing out scams and protecting the community, misusing CN as a bottom-up moderation technique.
Conclusion
This project is concerned with the ways in which a ‘free’, ‘transparent’, crowdsourced system quietly shapes the possibilities of public discourse and epistemic labor in its constituents. On one level, we analyze the affordances of CN to characterize X’s ideal contributor and end-product. Then, we look to the practices of CN contributors and reflect on their alignment with the affordances they are limited to. What we find is that contributors use CN in highly unpredictable ways, and that rather than forming one cohesive, automated “community”, contributors fracture into many behind the CN interface. For instance, contributors compete with one another over the actual purpose of CN through discursive practices, considering it is ill-defined by X in the first place. Others use non-traditional sources to justify their notes, which are sometimes not sources at all but links to chatbots. Such dynamics speak to the emergence of heterogeneous communities of practice within CN which beg for further research.
Future research must also attend to the new inclusion of Grok into CN. The implications of proprietary chatbots in crowdsourced epistemic labor is vast, and further complicates the mechanisms of containment that the platform constructs around the ‘public square’. On July 2, 2025, X announced that its proprietary chatbot, Grok, could be used to write notes. While this did not impact our research on contributor practices, it does mark a distinct turning point in the trajectory of CN and will change the texture of the crowdsourced ecology of the infrastructure. As our data was downloaded on July 1, 2025, we have some of the last data collected before Grok’s introduction to CN. Grok’s incorporation also raises some serious questions that should be addressed in future research. On the level of practices, how contributors use and negotiate with Grok in their epistemic and communicative processes is of serious importance in studying the containment and products of public discourse on X. On a more general level, Grok is now producing ‘facts’ on X under the guise of crowdsourced wisdom. The connection to X users asking Grok to comment on posts, a practice becoming more prevalent as we speak, complicates the nature, purpose, and value of a system like CN. Lastly, Grok has recently incurred scrutiny from journalists and users alike for spreading anti-semitism (Melimopoulos 2025), the South African ‘white genocide’ conspiracy theory (Kerr 2025), and, more generally, inane and harmful language in its publicly visible outputs (Kay 2025), for instance calling itself “mechahitler” (Taylor 2025). Since Grok is fine-tuned to operate within Elon Musk’s normative compass, this raises urgent ethical and epistemological concerns around its role in a fact-checking system.
Bibliography
Alba, Davey, Denise Lu, Leon Yin, and Eric Fan Technology. 2023. “How Musk’s X Is Failing To Stem the Surge of Misinformation About Israel and Gaza.” Bloomberg.Com, November 21, 2023. https://www.bloomberg.com/graphics/2023-israel-hamas-war-misinformation-twitter-community-notes/.
Alba, Davey, and Kurt Wagner. 2023. "Twitter Cuts More Staff Overseeing Global Content Moderation." Bloomberg, January 7, 2023. https://www.bloomberg.com/news/articles/2023-01-07/elon-musk-cuts-more-twitter-staff-overseeing-content-moderation
Allen, Matthew R., Nimit Desai, Aiden Namazi, Eric Leas, Mark Dredze, Davey M. Smith, and John W. Ayers. 2024. “Characteristics of X (Formerly Twitter) Community Notes Addressing COVID-19 Vaccine Misinformation.” JAMA 331 (19): 1670–72. https://doi.org/10.1001/jama.2024.4800
Amazeen, Michelle A. 2020. “Journalistic Interventions: The Structural Factors Affecting the Global Emergence of Fact-Checking.” Journalism 21 (1): 95–111. https://doi.org/10.1177/1464884917730217.
Bouchaud, Paul, and Pedro Ramaciotti. 2025. “Algorithmic Resolution of Crowd-Sourced Moderation on X in Polarized Settings across Countries.” https://hal.science/hal-05116614.
Brewster, Thomas. n.d. “X Fired 80% Of Engineers Working On Trust And Safety, Australian Government Says.” Forbes. Accessed July 18, 2025. https://www.forbes.com/sites/thomasbrewster/2024/01/10/elon-musk-fired-80-per-cent-of-twitter-x-engineers-working-on-trust-and-safety/.
Bucher, T., & Helmond, A. (2018). The affordances of social media platforms. In J. Burgess, A. Marwick, & T. Poell (Eds.), The SAGE handbook of social media (pp.233-253). Sage Publications.
Cheng, Myra, Angela Y. Lee, Kristina Rapuano, Kate Niederhoffer, Alex Liebscher, and Jeffrey Hancock. 2025. “From Tools to Thieves: Measuring and Understanding Public Perceptions of AI through Crowdsourced Metaphors.” arXiv. https://doi.org/10.48550/arXiv.2501.18045.
Chuai, Yuwei, Haoye Tian, Nicolas Pröllochs, and Gabriele Lenzini. 2023. The Roll-Out of Community Notes Did Not Reduce Engagement With Misinformation on Twitter. https://doi.org/10.48550/arXiv.2307.07960
Crawford, Kate, and Tarleton Gillespie. 2016. “What Is a Flag for? Social Media Reporting Tools and the Vocabulary of Complaint.” New Media & Society 18 (3): 410–28. https://doi.org/10.1177/1461444814543163.
Drolsbach, Chiara Patricia, Kirill Solovev, and Nicolas Pröllochs. 2024. “Community Notes Increase Trust in Fact-Checking on Social Media.” PNAS Nexus 3 (7): pgae217. https://doi.org/10.1093/pnasnexus/pgae217.
Flam, F.D. 2024. “Elon Musk’s Community Notes Feature on X Is Working.” Bloomberg, May 22, 2024. https://www.bloomberg.com/opinion/articles/2024-05-22/elon-musk-s-community-notes-feature-on-x-is-working.
Geertz, C., 1998. Deep hanging out. The New York review of books, 45 (16), 69.
Gibbs, Martin, James Meese, Michael Arnold, Bjorn Nansen, and Marcus Carter. "# Funeral and Instagram: Death, social media, and platform vernacular." Information, communication & society 18, no. 3 (2015): 255-268.
Habermas, Jürgen. 1991. The Structural Transformation of the Public Sphere: An Inquiry into a Category of Bourgeois Society. Cambridge, MA: MIT Press. http://choicereviews.org/review/10.5860/CHOICE.27-4175.
Hua, Yiqing, Manoel Horta Ribeiro, Robert West, Thomas Ristenpart, and Mor Naaman. 2022. “Characterizing Alternative Monetization Strategies on YouTube.” Proceedings of the ACM on Human-Computer Interaction 6 (CSCW2): 1–30. https://doi.org/10.1145/3555174.
Jude, Nadia, and Ariadna Matamoros-Fernández. 2025. "Community Notes and its Narrow Understanding of Disinformation." TechPolicy.Press, February 3, 2025. https://www.techpolicy.press/community-notes-and-its-narrow-understanding-of-disinformation/
Kay, Grace. n.d. “Inside Grok’s War on ‘Woke.’” Business Insider. Accessed July 18, 2025. https://www.businessinsider.com/xai-grok-training-bias-woke-idealogy-2025-02.
Kerr, Dara. 2025. “Musk’s AI Grok Bot Rants about ‘White Genocide’ in South Africa in Unrelated Chats.” The Guardian, May 15, 2025, sec. Technology. https://www.theguardian.com/technology/2025/may/14/elon-musk-grok-white-genocide.
Koltai, Kolina, Logan Williams, and Sean Craig. 2023. “X’s Community Notes Is Spreading False Information About Taylor Swift’s Bodyguard - Bellingcat.” Bellingcat. https://www.bellingcat.com/news/2023/10/20/xs-community-notes-is-spreading-false-information-about-taylor-swifts-bodyguard/.
Kornberger, Martin, Dane Pflueger, and Jan Mouritsen. 2017. “Evaluative Infrastructures: Accounting for Platform Organization.” Accounting, Organizations and Society 60 (July):79–95. https://doi.org/10.1016/j.aos.2017.05.002.
Leerssen, Paddy. 2023. “An End to Shadow Banning? Transparency Rights in the Digital Services Act between Content Moderation and Curation.” Computer Law & Security Review 48 (April):105790. https://doi.org/10.1016/j.clsr.2023.105790.
MacLeod, C., & McArthur, V. (2019). The construction of gender in dating apps: An interface analysis of Tinder and Bumble. Feminist Media Studies, 19(6), 822–840. doi:10.1080/14680777.2018.1494618 (It’s APA)
McIntyre, Lee. 2018. Post-Truth. MIT Press.
Melimopoulos, Elizabeth. n.d. “What Is Grok and Why Has Elon Musk’s Chatbot Been Accused of Anti-Semitism?” Al Jazeera. Accessed July 18, 2025. https://www.aljazeera.com/news/2025/7/10/what-is-grok-and-why-has-elon-musks-chatbot-been-accused-of-anti-semitism.
Patton, M. (1990). Qualitative evaluation and research methods. Beverly Hills, CA: Sage
Rieder, Bernhard, Ariadna Matamoros-Fernández, and Òscar Coromina. 2018. “From Ranking Algorithms to ‘Ranking Cultures’: Investigating the Modulation of Visibility in YouTube Search Results.” Convergence 24 (1): 50–68. https://doi.org/10.1177/1354856517736982.
Reimers, Nils, and Iryna Gurevych. 2019. "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." Preprint, arXiv:1908.10084. https://arxiv.org/abs/1908.10084.
Rogers, Richard. 2020. “Deplatforming: Following Extreme Internet Celebrities to Telegram and Alternative Social Media.” European Journal of Communication 35 (3): 213–29. https://doi.org/10.1177/0267323120922066.
Schudson, Michael. "Why conversation is not the soul of democracy." Critical Studies in Media Communication 14, no. 4 (1997): 297-309.
Shaw, Adrienne. 2017. “Encoding and Decoding Affordances: Stuart Hall and Interactive Media Technologies.” Media, Culture & Society 39 (4): 592–602. https://doi.org/10.1177/0163443717692741.
Stanfill, M. (2015). The interface as discourse: The production of norms through web design. New media & society, 17(7), 1059-1074.
Strauss, Anselm, and Juliet M. Corbin. 1990. Basics of Qualitative Research: Grounded Theory Procedures and Techniques. Basics of Qualitative Research: Grounded Theory Procedures and Techniques. Thousand Oaks, CA, US: Sage Publications, Inc.
Stevenson, Michael. 2018. “From Hypertext to Hype and Back Again: Exploring the Roots of Social Media in Early Web Culture.” In The SAGE Handbook of Social Media, by Jean Burgess, Alice Marwick, and Thomas Poell, 69–88. 1 Oliver’s Yard, 55 City Road London EC1Y 1SP: SAGE Publications Ltd. https://doi.org/10.4135/9781473984066.n5.
Tarde, Gabriel. 1969. On Communication and Social Influence. Edited by Terry N. Clark. Chicago: University of Chicago Press.
Taylor, Josh, and Josh Taylor Technology reporter. 2025. “Musk’s AI Firm Forced to Delete Posts Praising Hitler from Grok Chatbot.” The Guardian, July 9, 2025, sec. Technology. https://www.theguardian.com/technology/2025/jul/09/grok-ai-praised-hitler-antisemitism-x-ntwnfb.
X. “About Community Notes on X | X Help.” X, 2025. https://help.twitter.com/en/usingx/Community-notes
X Business. 2024. “Transforming the Global Town Square.” X Blog. January 9, 2024.
https://blog.x.com/en_us/topics/company/2023/transforming-the-global-town-square
X Community Notes. N.d. “Note Ranking Algorithm.” Accessed July 9, 2025.
https://communitynotes.x.com/guide/en/under-the-hood/ranking-notes#modeling-uncertainty
APPENDIX
Our cleaned and filtered datasets as well as code for the cleaning, url extraction and topic modeling are available on our Github repository: https://github.com/yukiandcoco/DMI_CommunityNotes
Ideas, requests, problems regarding Foswiki? Send feedback