You are here: Foswiki>Digitalmethods Web>TheWebsite (12 Nov 2012, ErikBorra)Edit Attach
The Website
Issues with the object of study
Investigations into Websites have been dominated by user and "eyeball studies," where attempts at a navigation poetics are met with such sobering ideas as "don't make me think" (Dunne, 2000; Krug, 2000). Many of the methods for studying Websites are located 'over the shoulder,' where one observes navigation or the use of a search engine, and later conducts interviews with the subjects. What one may term 'registrational approaches' have found their most popular technique in eye-tracking. Sites load and eyes move to the upper left of the screen, otherwise known as the 'golden triangle.' The resulting 'heat maps' provide site redesign cues. For example, Google has moved its services from above the search box (tabs) to the top left corner of the page (menu). Here the contribution to Website studies is different. The Website is taken to be an archived object, made accessible through the Internet Archive's Wayback Machine. Which types of studies of Websites are enabled and constrained by the Wayback machine? The Web archiving scholar, Niels Brügger, has written: "[U]nlike other well-known media, the Internet does not simply exist in a form suited to being archived, but rather is first formed as an object of study in the archiving, and it is formed differently depending on who does the archiving, when, and for what purpose" (Brügger, 2005). That the object of study is constructed by the means by which it is 'tamed' and 'captured' by method and technique is a classic point from the sociology and philosophy of science and elsewhere (Latour and Woolgar, 1986; Knorr-Cetina, 1999; Walker, 2005). Of importance here is how a Web archive as an object, formed by the archiving process, embeds particular preferences for how it is used, and for the type of research performed with it. Which methods of research are privileged by the specific form assumed by the Web archive, and which are precluded? For example, when one uses the Internet Archive (archive.org), what stands out for everyday Web users accustomed to search engines, is not so much the achievement of the very existence of an archived Internet. Rather, the user is struck by how the Internet is archived, and, particularly, how it is queried. One queries a URL, as opposed to key words, and one receives a list of stored pages associated with the URL from the past. In effect, the Internet Archive, through the interface of the Wayback Machine, has organized the story of the Web into the histories of single Websites. Which types of research approaches are favored by such an organization of Websites?With the current form assumed by the Internet Archive, one can study the evolution of a single page (or multiple pages) over time, for example, by collecting snapshots from the dates that a page has been indexed.[1] (The outcomes of such an approach are discussed in the example below.) One also can go back in time to a Website for evidentiary purposes, checking accounts of past events. Is that how one may wish to study history with the Internet Archive? Is that how one could fruitfully study the history of the Web? The research project concerns itself with the methodological preferences embedded in the form assumed by Web archives, concentrating especially on the tools that are built on top of them, like the Wayback Machine. Which research assumptions are embedded in the machines that provide access to Web archives? Which other tools may be built atop the archive that address the methods and approaches prevented by the current set-up? [1] The privileging of content analysis over other forms of analysis does not necessarily preclude such other humanities interests such as the study of (Web) aesthetics. In a series of papers prepared for the 2004 "Decade of Web Design" conference in Amsterdam, researchers often used search engines (with date range), not the Internet Archive, to retrieve particular qualities of the Web from the 1990s (Lialina, 2005).
Approach
How to use the Internet Archive to study the history of the Web? The Internet Archive's Wayback Machine is suited to the study of the histories of single sites. Generally speaking, the goal is to capture the history of a Website, and analyze its changes. The analysis takes the form of writing a narrative that describes and makes an account of the changes.Method
- Type URL into the Internet Archive Wayback Machine Link Ripper. Click submit and be patient.
- Once step 1 has finished, go to the tools output menu and save the archived URLs as a text file.
- We assume you have installed a recent version of Firefox as well as the Firefox extension Grab Them All. There is also a screencast on how to install Grab Them All
- In Firefox, go to Tools > Add-ons and make sure the preferences of Grab Them All are as follows:
- PNG
- Grab visible window only
- Safe URL
- generate report file
- width: 1024
- height: 768
- In Firefox, go to Tools > Grab Them All.
- Click on 'Load file with URLs to grab' and point it to the text file you just downloaded.
- Select a directory where all the screenshots should be saved.
- Set the 'Max processing time' to 120 or 150 (the Wayback Machine is very slow).
- Set 'Javascript time to wait' to 60.
- Click "Let's go!".
- Wait until all screenshots have been captured. This will take a couple of hours, depending on the amount of archived pages in the Wayback machine.
- See if all went well by looking at the pictures. Sometimes the archive returns an error. Note those URLs in a new text file and repeat steps 4 to 6 until all screenshots succeeded.
- Load png's into an image viewer like e.g. iPhoto.
- Consider annotating the screenshots to highlight specific elements.
- Make project into iMovie or Windows Movie Maker, sorted by name, which keeps the pages in chronological order. Record Narrative
OR
Go to http://screenr.com and record your narrated slideshow through this web service. (you may have to install Java from here: http://www.java.com/getjava/) ;
OR
On the Mac, use the built-in screen-recording feature in Quicktime.
Literature
Brügger Niels (2005). Archiving Websites: General Considerations and Strategies, Aarhus: Centre for Internet Research. Dunne, Anthony (2000). Hertzian Tales: Electronic Products, Aesthetic Experience and Critical Design. London: Royal College of Art. Knorr-Cetina, Karen (1999). Epistemic Cultures. Cambridge, MA: Harvard University Press. Krug, Steve (2000). Don't Make Me Think: A Common Sense Approach to Web Usability. Indianapolis: New Riders. Latour, Bruno and Woolgar, Steve (1986). Laboratory Life. Princeton, NJ: Princeton University Press. Lialina, Olia (2005). “The Vernacular Web,” paper presented at “A Decade of Web Design” conference, Amsterdam, http://art.teleportacia.org/observation/vernacular/. Walker, Jill (2005). “Feral hypertext: when hypertext literature escapes control.” Proceedings of the Sixteenth ACM Conference on Hypertext and Hypermedia. New York: ACM, 46-53.Sample project
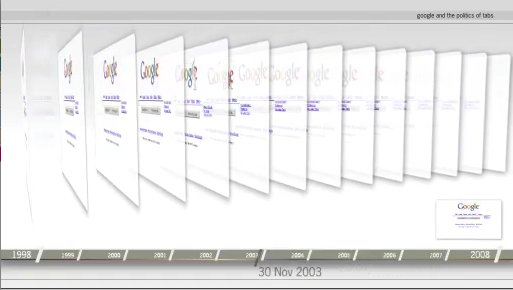
Google and the politics of tabs
Over the years the Google interface has been remarkably stable, with a simple search box and two buttons: Google web search, and I'm feeling lucky. However, on top of the search box there have been a series of tabs that have changed somewhat over time. Which tabs, each a Google search service, have remained stable, and which has lost their front-page tab status? What does the departure of the directory from the front page mean for the future of Web search? Research Protocol:
- Type http://www.google.com into the Wayback machine at http://www.archive.org.
- Using LinkRipper, rip all links from the results page, http://web.archive.org/web/*/http://www.google.com.
- Use html to pdf to png converter: htm2pdf and ImageMagick to transform the pdf's to png files.
- Load png's into iPhoto. Make project in iMovie. Load into iMovie, sorted by name, which keeps the pages in chronological order.
- Record narrative.
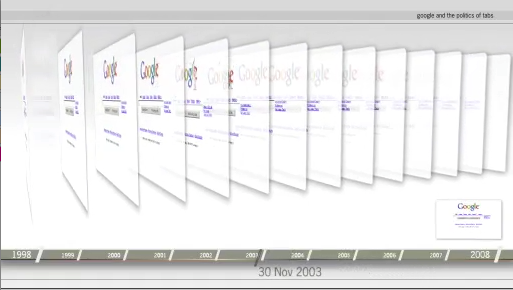 See also the accompanying information graphic, Govcom.org (2008). "The Demise of the Directory - Web Librarian Work Removed in Google." Amsterdam.
See also the accompanying information graphic, Govcom.org (2008). "The Demise of the Directory - Web Librarian Work Removed in Google." Amsterdam.
Sample project literature
Battelle, John (2003). "The ‘creeping googlization’ meme." John Battelle’s Searchblog. December 16, http://battellemedia.com/archives/000145.php Battelle, John (2005). The Search: How Google and its rivals rewrote the rules of business and transformed our culture. London: Penguin. Caufield, James (2005). "Where did Google get its value?" Libraries and the Academy. 5(4): 555-572. Diaz, Alejandro M. (2005). "Through the Google goggles. Sociopolitical bias in search engine design." Thesis. Stanford University. Hindman, Matthew, Kostas Tsioutsiouliklis and Judy A Johnson (2003). "Googlearchy: How a few heavily-linked sites dominate politics on the Web." Annual Meeting of the Midwest Political Science Association, Chicago. Jeanneney, Jean-Noel (2007). Google and the Myth of Universal Knowledge. Chicago:University of Chicago Press. Nicholson, Scott and Tito Sierra (2005). ‘How much of it is real? Analysis of paid placement in web search engine results’. Journal of the American Society of Information Science and Technology. 57(4):448-461. Viadhyanathan, Siva (2007). "The Googlization of everything and the future of copyright." UC Davis Law Review. 40(3): 1207-1231.

{kind=link}
| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
google_movie_image.png | manage | 88 K | 11 Sep 2008 - 09:09 | RichardRogers | Google and the Politics of Tabs |
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r16 < r15 < r14 < r13 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r16 - 12 Nov 2012, ErikBorra
Ideas, requests, problems regarding Foswiki? Send feedback