The force of falsity? When AI prompts guesses or narratives about debunked images sow more confusion about the fake.
Team members
- Denis Teyssou, Bertrand Goupil, Valentin Porcellini (AFP)
- Anna Cattaneo (Politecnico di Milano)
- Guillén Torres (University of Amsterdam)
Links
Contents
1. Summary of Key Findings
Our DMI/vera.ai project confirms on an international dataset of 155 fake images debunked in 2023 our initial empirical findings: when queries with fake images, the main reverse search engines often get it wrong. On our dataset, only 18% of the results are accurate, 35% are wrong and 44% are incomplete, missing to detect the falsity.
Our dataset analysis also shows a rise of synthetic images, featured in 17.4% of our sample, and the prevalence of decontextualized images (43.2%), almost doubling the altered images (23.2%).
2. Introduction
During the last years, we found empirically that debunked fake images are often poorly indexed by the main reverse image search engines. Their AI prompt providing their best guess, hypothesis, or related search suggestion about those images gets it regularly wrong. It, therefore, creates more confusion instead of confirming the falsity of the content already debunked by fact-checkers. Generative AI frameworks (like GPT4 through Microsoft Bing) are also able to invent complete fictional narratives about those images.
Building upon Umberto Eco’s “force of falsity” concept and datasets of debunked manipulated images, we tried to confirm on a wider dataset our early hypothesis that the main reverse image search engines have indeed trouble indexing properly those images.
3. Research Questions
Q1: Are debunked fake images poorly indexed by search engines' AI prompts?
Q2: Are generative AI frameworks being confused by narratives around fake images, even when debunked?
Q3: How several copies of the same image may be interpreted differently by AI prompts?
4. Methodology and dataset
Given the time and resources available, we decided to focus mainly on a dataset of debunked pictures gathered during a month (May 31st, 2023 till July 5th, 2023) on Google Fact Check Explorer, using the keyword “photo” as a query, multilingual search, and getting back all the fact-checks links in the results.
Then, we manually retrieved all the images from the fact-checks, the archive links (if any) or the sources of disinformation whenever present.
The resulting dataset (in a spreadsheet) has 155 debunked fake images which we annotated manually with their topic and their type of manipulation: decontextualized (image from a past event being reused in another context), altered (semantically manipulated with some editing software), fictional (fabricated on purpose, not linked to any reality), misinterpretation (when pictures are clearly misinterpreted like talking about another person than the one on the photography), synthetic (when produced through generative AI).
As our choice was to work on a multilingual dataset, we collected fact-checks from many different countries, including India, the Middle East, Asia, Europe, and America. To be indexed by the Google Fact Check Explorer implies that fact-checking organizations use the ClaimReview annotation format within their publications to improve their search engine optimization (SEO).
Therefore, one would expect that images already debunked by fact-checking organizations using this annotation format and being indexed by Google Fact Check Explorer would perform better than random images in content-based image queries.
To understand the content of the fact-checks analyzed, we extensively used several translation tools (such as DeepL, Google Translate, or LLMs).

Figure 1. A CheckGIF output between the fake and the original image
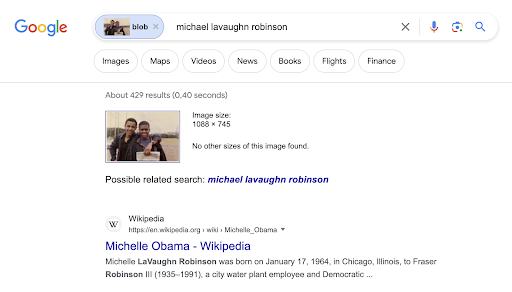
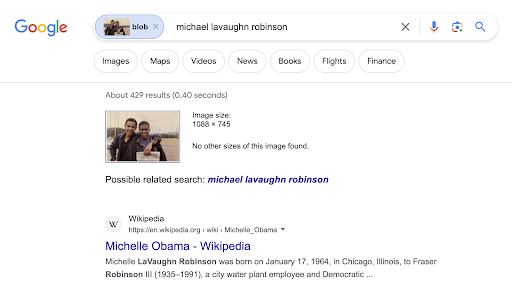
Figure 2. Google images results on the fake masculinized Michelle Obama picture
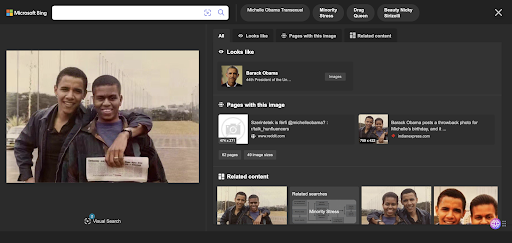
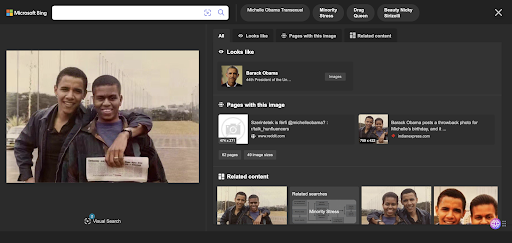
Figure 3. Bing Images results on the fake masculinized Michelle Obama picture
5. Findings
Our findings on this dataset tend to confirm our early hypothesis: reverse image search engines (a key tool for fact-checkers and for media literacy) are having trouble in indexing properly fake (and debunked) images. Beyond some initial examples retrieved empirically during previous research projects, our study confirms that the poor indexing problem is recurrent and that this kind of limits in AI and computer vision to retrieve accurate information should be a concern for all the major search engines.
We found in our dataset twice more wrongly indexed images than properly indexed ones.
One of the most striking examples is a picture of the Obama couple where Michelle Obama was masculinized to make her look like a transgender. This fake image which can be seen below using the CheckGIF feature output to reveal the image forgery was wrongly indexed, at the time of our study, as “Michael Lavaughn Robinson” (by Google Images) a masculinized version of Michelle Obama’s birth name or as “Michelle Obama transexual” (by Bing images).
6. Discussion
These results confirm that there is a structural issue regarding the poor indexing of fake images (even when properly debunked). This illustrates the “force of falsity” described in several of his books by the late Italian semiotician Umberto Eco.
Instead of providing the correct information about the fake, search engines are reinforcing it by providing this kind of result. The above examples tend to prove that search engines results are polluted by conspiracy or propaganda narratives around fake images.
Further investigations, on larger datasets, should be conducted to get a more appropriate statistical approach to the problem outlined in our research.
7. References
EPSC (2018). The Force of Falsity. [online] Election Interference in the Digital Age. Available at: https://medium.com/election-interference-in-the-digital-age/the-force-of-falsity-924efa1b7921. schema.org. ClaimReview - Schema.org Type. [online] Available at: https://schema.org/ClaimReview. WeVerify. (2022). Verification plugin - WeVerify. [online] Available at: https://weverify.eu/verification-plugin/. www.veraai.eu. Project Summary. [online] Available at: https://www.veraai.eu/project-summary. -- ValentinP - 23 Aug 2023

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback