Inside the Troll Factory: Mapping Russia’s Disinformation-Industrial Complex
Links
- Week 1 Poster
- Week 2 Poster
- Python script: analyze_initial_data.py
- Results: Initial Data Analysis Results (5/7/2025)
- This script was used during the first week to recursively explore and characterize a JSON file representing collected CVs
- CV Parsing & Analysis (Jupyter Notebook)
Team Members
Facilitator: Serge Poliakoff Design facilitator: Riccardo Ventura Technical help: Dale Wahl Team members: Claire Goeckner-Wald, Duco van de Schepop, Kate Walsh, Lea Frühwirth The project is part of the HORIZON Europe project “Social Media for Democracy" (SoMe4Dem).Contents
Summary of Key Findings
This project aimed to situate disinformation production organisations within the wider Russian labour market through the analysis of Russian curriculum vitae (CVs) available online. Contrary to previous theoretical claims that placed 'disinformation-for-hire' within the media markets of their respective countries (Grohmann & Ong, 2024), the latest Russian disinformation production organisations (such as ANO Dialog) also operate within the government and government-related company market. Additionally, this project illustrates the distribution of job roles in the social media sector among employees of entities sanctioned for disinformation and propaganda. It shows that while some entities engage in all defined social media activities, others focus only on certain types, and this distribution does not correlate with the organisation's definition according to the sanctions data. Lastly, while compiling a list of organisations sanctioned for disinformation and propaganda, this project revealed discrepancies in the definitions of 'propaganda' and 'disinformation' among the sanction makers.1. Introduction
The production of disinformation has become one of the defining features of Russian digital authoritarianism (Polyakova & Meserole, 2019). Over the last decade, Russian 'troll farms' attempted to interfere in foreign elections and affairs by spreading targeted disinformation on social media. These attempts have ranged from the 2016 U.S. presidential election to the most recent "Doppelgänger" campaign, which aimed to undermine Western support for Ukraine. In light of the recent discovery of new disinformation entities that collaborated closely with the Russian presidential administration and social media already before Russia's full-scale invasion of Ukraine in 2022 (Pamment & Tsurtsumia, 2025; Poliakoff et al., unpublished manuscript), we mapped the disinformation production ecosystem within the Russian labor market through the analysis of CVs collected from the Russian job seeking platform ‘HeadHunter’ (hh.ru). This included disinformation production organizations, social media platforms, media regulators, and media analytics companies. The first phase of this project focuses on the operations of ANO Dialog within the wider Russian labour market. Autonomous Non-Profit Organization (ANO) Dialog is a Russian organization established in 2019 by the Moscow Department of Information and Technology. After receiving funding from the Russian federal budget, it came under the control of the Russian Presidential Administration (Poliakoff, 2025). ANO Dialog expanded its operations by creating ANO Dialog Regions and Regional Control Centers in 2020 and gained control of the Russian media outlet Readovka. The stated purpose of ANO Dialog was to enhance digital communication between the government and public by monitoring public sentiment and addressing citizens' complaints. However, ANO Dialog was sanctioned by the EU, UK, and US between 2023-2024 for spreading disinformation and propaganda online. The activities of ANO Dialog have drawn international scrutiny due to its manipulation of social media platforms to promote false narratives, particularly surrounding the full-scale invasion of Ukraine in 2022 The second phase of this project has focused on the wider Russian disinformation ecosystem, tracing how disinformation is industrialized, outsourced, and integrated into the state apparatus of digital authoritarianism. While Russia's “troll farms” have become infamous symbols of information warfare, we still know surprisingly little about how they operate, who does the work, and where they sit within the country's wider political economy. The overarching aim was to reconstruct the architecture of the Russian propaganda machine using only data from CVs, tracing how disinformation is industrialized, outsourced, and integrated into the state apparatus of digital authoritarianism.2. Research Questions
Leading RQ: What can be learned about the inaccessible field site of Russia and its disinformation production ecosystem through the use of OSINT methods of CV analysis? First Phase RQs: Focus on ANO Dialog RQ1: What thematic areas of activity can be identified within ANO Dialog's operations, and how do these areas overlap across individual roles? RQ2: How is ANO Dialog situated within the Russian labour market, and which organisations demonstrate the strongest labour force connectivity with it? RQ3: How has ANO Dialog’s labour footprint evolved over time, and how does this trajectory compare with other sectors within the Russian labour market? Second Phase RQs: Focus on Wider Disinformation Ecosystem RQ4: What specific propaganda-related activities are emphasised by each of the top 14 organisations, and how strong is the association between these entities and particular types of areas of activity? RQ5: How are disinformation and propaganda organisations situated within the Russian labour market? RQ6: What are the most frequent company co-occurrences on CVs with Russian organisations sanctioned for propaganda and/or disinformation (according to OpenSanctions), and what do these patterns reveal about the consistency of the sanctioning strategy?3. Methodology and initial datasets
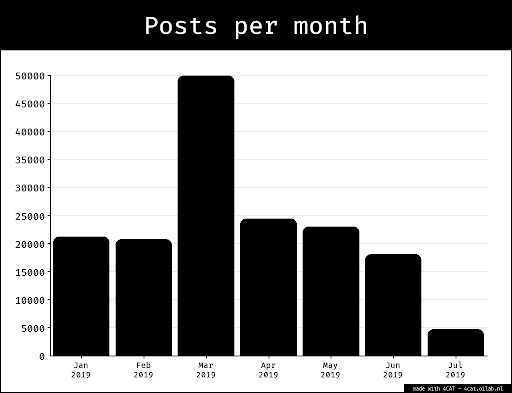
This project follows the OSINT method of CV analysis (Poliakoff & Kling, unpublished manuscript), which was developed for individual case studies of Russian disinformation production organisations. In the first phase of the project, analysis was performed on CVs related to the sanctioned company ANO Dialog. It contained 1,797 CVs of employees of ANO Dialog and its subsidiaries (named ANO Dialog Dataset in the text). Each CV is assumed to represent one user’s self-generated itemized list describing their experiences and education relevant to the Russian labour market. The CVs were scraped into a JSON structure.A Python script was used during the first week to recursively explore and characterize a JSON file representing CVs collected from HeadHunter (“ANO Dialog Dataset”). The primary goal was to synthesize the overall structure, count, uniqueness, and data type of each key in the set. The script output is shown in Table 1 in the Appendix, and in a Google Sheet.
This analysis generated several insights. First, the majority of CVs included information about prior work experience, education history, key skills, and other professional details. Some fields are almost always present, such as citizenship and gender. Other fields appear very rarely, such as uncommon languages or driving experience.
Secondly, approximately 5% of the dataset were potentially duplicated. This is suggested by the uniqueness of the path value, which represents the URL path of the CV. Duplicate CVs could interfere with data analysis by suggesting “heavier” network associations than exist in actuality. For this reason, it is necessary to deduplicate the dataset before drawing conclusions about network associations, especially as the dataset grows in size in future work.
To expand the dataset and support a broader range of analytical insights, we expanded the list of relevant search terms (Appendix, Table 0) to include a wider range of organisations that may be part of the Russian disinformation ecosystem (see Methodology section). This resulted in a dataset of 19,659 CV profiles collected on the second week of the project (“CV Dataset”). The expansion allowed for a more comprehensive mapping of disinformation and propaganda-related employment within the Russian labour market.
Data Cleaning and Normalization:
The new dataset is an ASCII-encoded NDJSON (New-line Delimited JSON) file. Our main area of interest is the "experience name” field. This field’s data appears to be unconstrained human-generated text. That is, users do not select from pre-defined, existing companies; they simply enter arbitrary text, which can contain typos, acronyms, or abbreviations. This makes large-scale equality comparisons quite difficult, and necessitates the use of fuzzy-matching algorithms to identify company names which may be similar but not identical.
The fuzzy-matching algorithm will operate largely on Russian-language text encoded with Unicode. Some Cyrillic characters can be represented multiple ways in Unicode. For example, consider the Cyrillic letter Ё. It can be represented compactly as U+0401, or as the combination of the letter E (U+0415) with an umlaut (U+0308). These should evaluate as equal because they are considered equivalent by human readers. Otherwise, the Unicode encoding could artificially depressing “match” scores generated by a fuzzy-matching algorithm. Therefore, we must normalize text input using the unicodedata.normalize function (Python Unicode Docs).
A very large number of text comparisons are necessary. We have approximately 20,000 CVs containing an average of three company names each. Each of these 60,000 company names must be compared to a list of sanctioned companies. Supposing 40 sanctioned companies, each with around 5 operating translations or aliases, we can expect around 12 million text comparisons. For that reason, the highly-optimized Python module RapidFuzz was chosen over the popular thefuzz and fuzzywuzzy modules.
The extractOne function was used (RapidFuzz - extractOne). By default, it uses the Wratio algorithm to calculate a weighted ratio based on other ratio algorithms (RapidFuzz - WRatio). A score cutoff of 80 was used.
As one of the keywords used for data collection was 'Struktura' (the name of one of the sanctioned entities), some corporations in the dataset are obliquely referred to as simply структура or “structure.” These names were eliminated from the analysis. Additional characters such as variations on single-quote, double-quote, commas, and apostrophes were standardized. For additional detail, please see the Jupyter Notebook file.
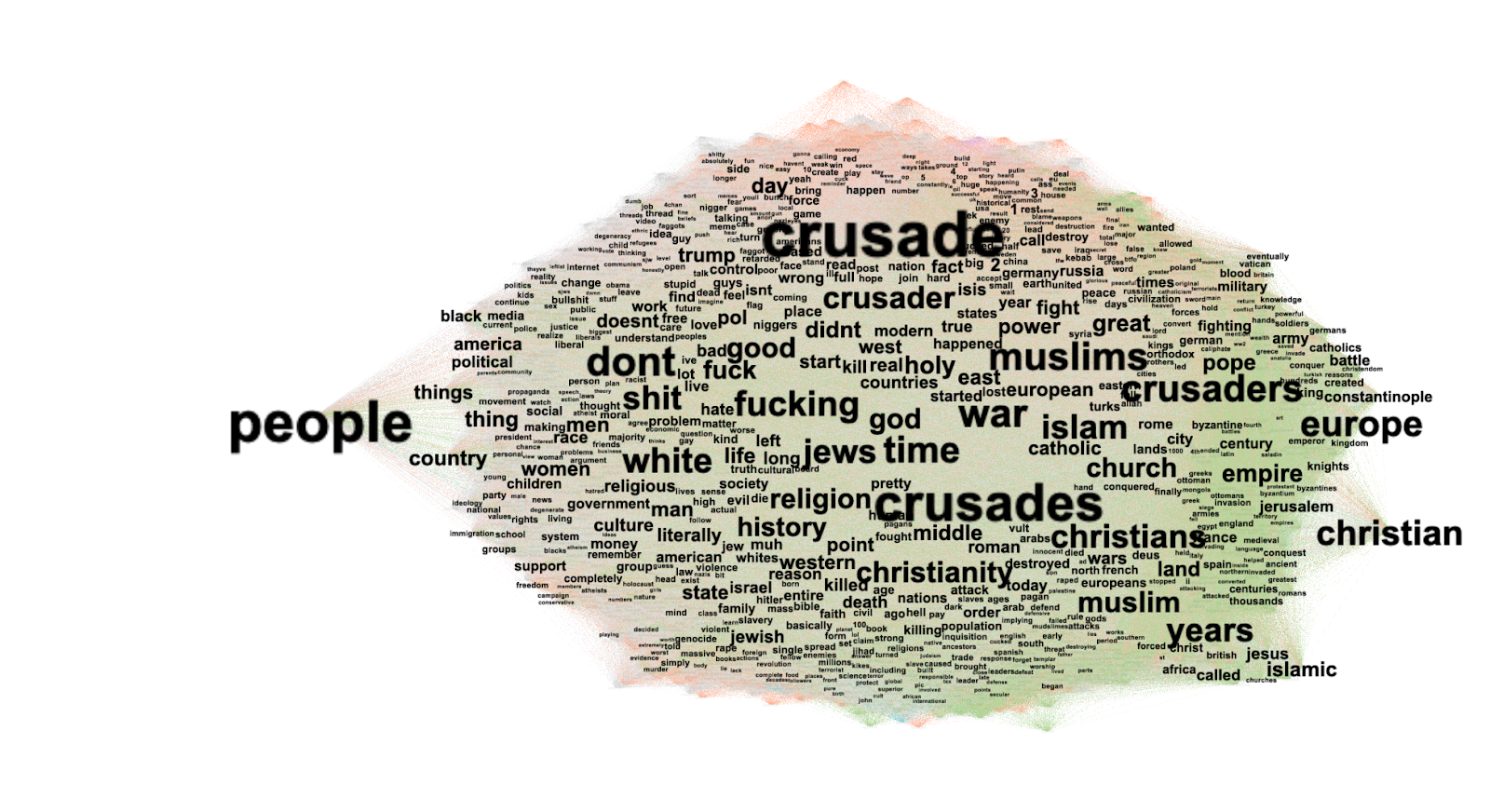
Analyzing domains, strategic focus areas, and types of professional activity:In order to identify potential operational domains and strategic focus areas of Russian information and influence operations for RQ1, we classified CVs into coherent thematic work areas by mapping individual job role descriptions. This allowed us to uncover the infrastructure and functional specialisations behind coordinated disinformation and state-backed propaganda campaigns.
The method involved defining categories of areas of activity through manual inspection of approximately 300 CVs to identify recurring themes, roles, and domain-specific language, using a keyword dictionary to consolidate patterns. Insights from this process were used to define and refine 13 final categories of activity areas, covering job functions and areas of strategic interest, including:
- Government & Public Policies,
- Environmental Sustainability,
- Healthcare & Social Work,
- Legal Affairs & Regulatory Technology,
- Economics & Finance,
- Media & Communications,
- Defense & Security,
- Technology & Digital Innovation,
- Cultural & Arts Programming,
- Education & Training,
- Urban Infrastructure & Transport,
- Scientific & Social Research,
- Civic Engagement & Public Outreach.
Each category was labeled with a short natural-language description to capture its conceptual scope. Machine learning techniques were employed to analyze the data, using the all-MiniLM-L6-v2 model from the sentence-transformers Python library to convert both the category descriptions and each CV's described area of activity into vector representations in a shared semantic space. This transformer-based model encodes the meaning of text into high-dimensional embeddings, allowing comparison of semantic similarity beyond just surface-level keywords.
To determine the types of professional activities most frequently associated with propaganda-related roles for RQ4, as reported in CVs across the top 13 entities linked to the Russian disinformation and influence ecosystem, the All-MiniLM-L6-v2 SentenceTransformer was applied to classify each CV into a broad set of general sectoral categories (e.g. Economics & Finance, Environmental Sustainability, and Administrative Work). This first-stage classification helped to isolate CVs whose areas of work were plausibly related to propaganda (e.g. Media & Communications or Civic Engagement & Public Outreach). New propaganda categories were subsequently defined to extract more specific information about areas of activities. The new categories we defined are: Social Media Moderation, Design, Scientific & Social Research, Copywriting, Government & Public Policy, Advertising, Social Media Creation, Cultural Arts Programming, Journalism, Civic Engagement & Public Outreach and Digital monitoring.
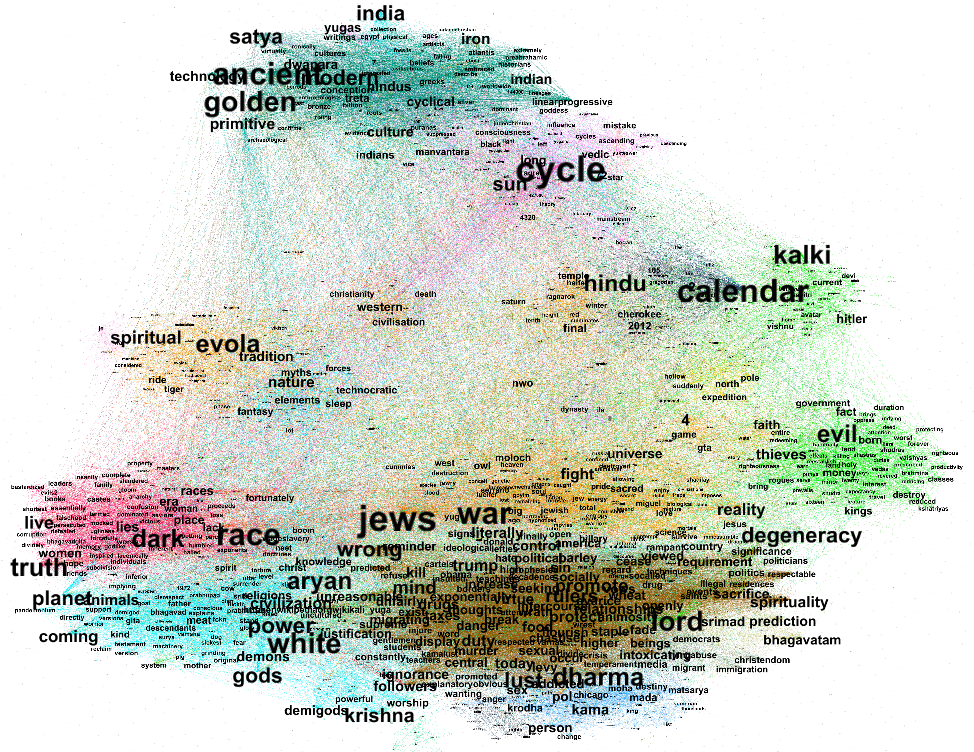
Network analysis:For RQ2 and RQ5, we constructed a network graph based on shared associations between employees and companies, coloured the nodes by industry category and adjusted their size based on company frequency in the dataset. We then used Gephi's ForceAtlas 2 to display and visualise the network. The nodes represent unique companies in the dataset and have attributes such as company name (ID), industry (colour) and frequency count in the dataset (size). The final network includes 4,697 unique companies for RQ2. For RQ5, our network analysis yielded a large-scale graph comprising 71,449 unique nodes.
Querying OpenSanctions:OpenSanctions was leveraged for information on sanctioned companies because it provides free programmatic access to simple text search across 289 data sets, including “official sanctions lists, data on politically exposed persons and entities of criminal interest” (OpenSanctions). The primary areas of interest were companies subject to sanctions based on disinformation and propaganda activities. Thus, the primary search terms were “disinformation” and “propaganda.”
OpenSanctions was queried with the default simple entity search API function (OpenSanctions API Docs - search/). The “disinformation” search term returned 18 entities; “propaganda” returned 19. Some companies appeared in both search results. After deduplication, we had a list of 35 unique sanctioned companies or “entities.”
Many OpenSanctions datasets are not in English but are still relevant to our research; Russian disinformation activities are not strictly limited to the English language. Therefore, “propaganda” and “disinformation” were translated to many languages used by governments in the EU and Americas (Appendix Table 2). Applying the expanded list of translated search terms increased the number of resulting companies from 47 entities across 2 searches (“propaganda” and “disinformation”) to 145 across 19 searches. These entities were then deduplicated to a total of 39 companies. Thus, four additional unique companies were discovered with the expanded list of search terms. This resulted in the “OpenSanctions List” of companies.
Some companies have been linked to disinformation campaigns, such as Doppelganger, but are not sanctioned. These companies are nonetheless relevant, so we used previous publications on information operations to generate a list of linked companies. The resulting information operation list consisted of 49 companies, stemming from reports on Doppelganger and Portal Kombat by VIGINUM, Qurium, the Institute for Strategic Dialogue, CORRECTIV, and the Bavarian Office for the protection of the Constitution (Germany). These leads included varying degrees of attribution, ranging from clear connections to suspected ones. This resulted in the “Information Operation List” of companies.
Finally, all unique experiences listed in all unique CVs in the CV dataset were fuzzy-matched to all companies and company aliases and translations in the OpenSanctions List and Information Operation List. This process was written to a CSV file for visualization in Gephi.
4. Findings
RQ1:
The top five most common categories are:
- Media & Communications,
- Government & Public Policy,
- Civic Engagement & Public Outreach,
- Cultural & Arts Programming,
- Scientific & Social Research.
A total of 1,128 CVs had more than 1 category.
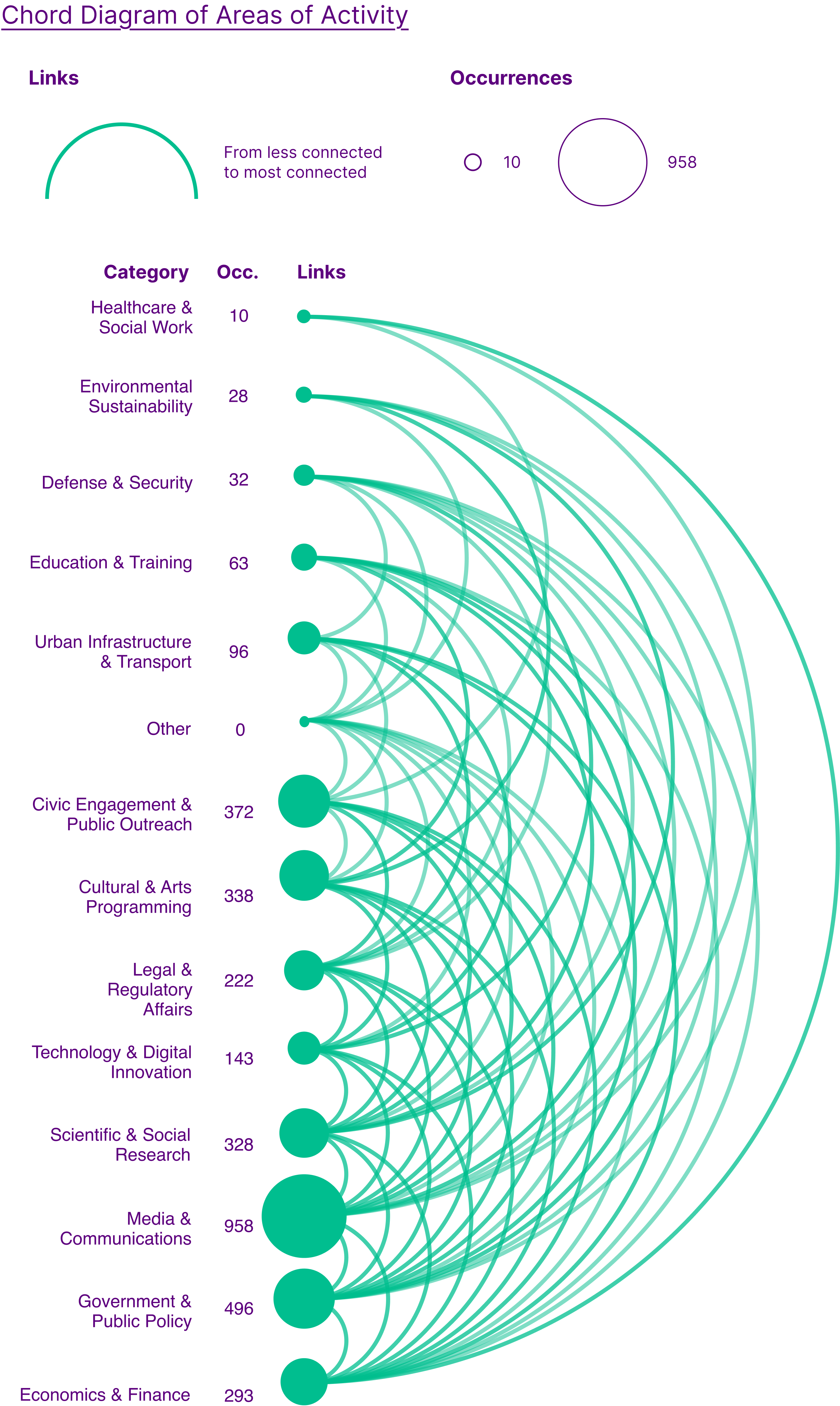
A total of 1,128 CVs had more than 1 category.
The analysis identified the top three prominent combinations of activity areas:
- The combination of 'Civic Engagement & Public Outreach,' 'Government & Public Policy,' and 'Media & Communications' ranked first, indicating a strong and frequent interconnection among these domains.
- Second in the list was 'Civic Engagement & Public Outreach,' 'Cultural & Arts Programming,' and 'Media & Communications,' reflecting a notable collaboration or overlap in these areas.
- Rounding out the top three, 'Cultural & Arts Programming' and 'Media & Communications' appeared together frequently, underscoring a significant synergy between these two fields.
 The findings indicate that ANO Dialog and ANO Dialog regions hold a central position within the network, which is expected since we looked for CVs related to ANO Dialog. The sector analysis reveals that media companies constitute 20.53% of the network, followed by technology at 10.09%, education at 10.05%, and manufacturing at 8.32%.
The findings indicate that ANO Dialog and ANO Dialog regions hold a central position within the network, which is expected since we looked for CVs related to ANO Dialog. The sector analysis reveals that media companies constitute 20.53% of the network, followed by technology at 10.09%, education at 10.05%, and manufacturing at 8.32%.
 The network analysis suggests that government companies are more densely clustered around ANO Dialog (Regions) and its affiliated entities, such as READOVKA and REGIONAL CONTROL CENTER, indicating a tighter labor force connectivity with these core organizations. In contrast, media companies appear more dispersed across the network, with a lower concentration around ANO Dialog, reflecting a broader distribution of their activities and connections. This pattern may imply that government entities have a more centralized role or stronger operational ties with ANO Dialog, while media companies engage with a wider variety of nodes, potentially indicating diverse partnerships or influence across the network.
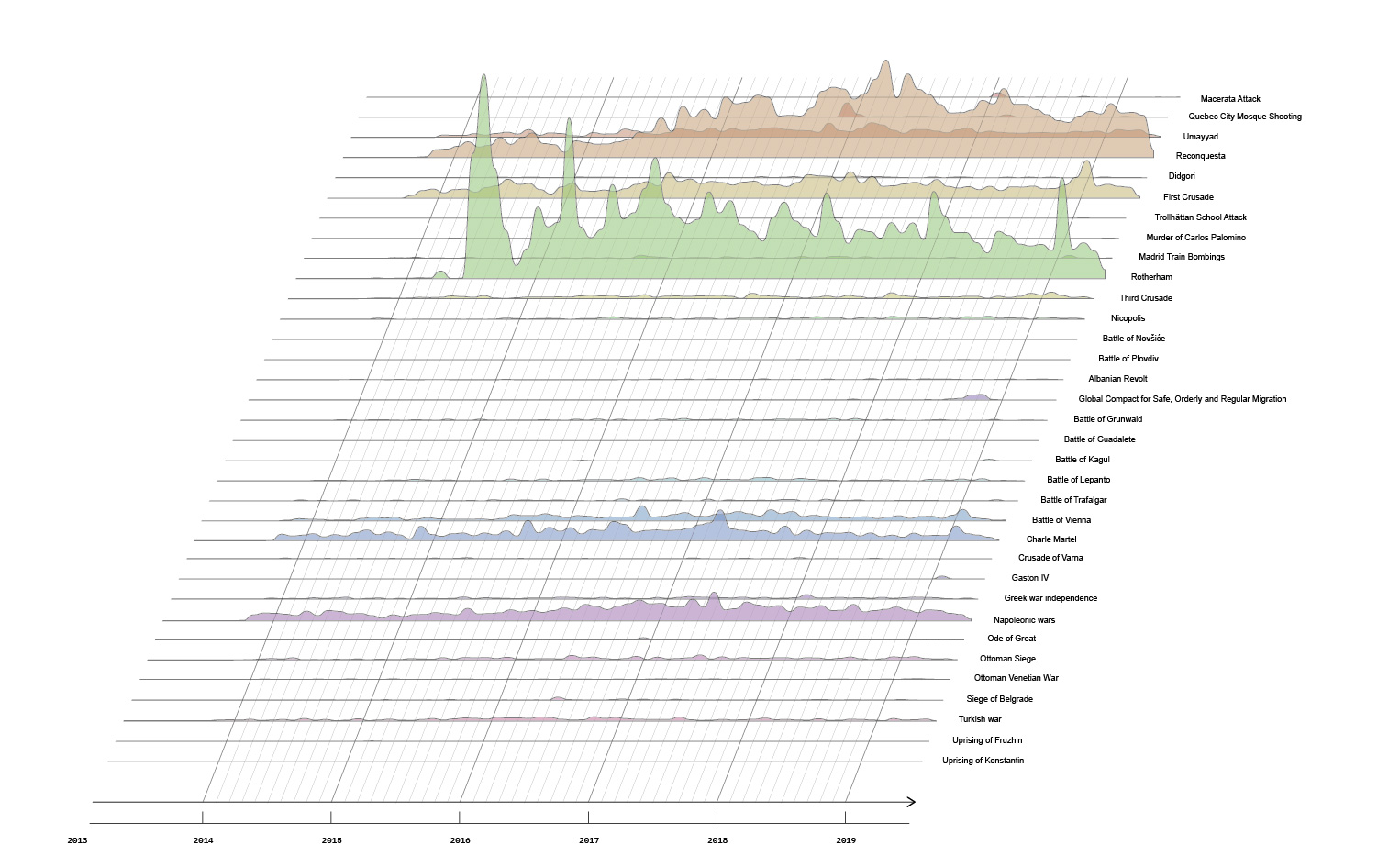
RQ3:
The findings show that ANO Dialog's headcount has remained stable and has not declined since Russia's full-scale invasion of Ukraine in 2022, with noticeable growth in headcount during this period. The data indicate a significant increase in activity after Russia injected funds into its federal budget following 2020, which also marked the start of this expansion. The Gantt chart reveals that ANO Dialog family companies, depicted in green, dominate the labor footprint over time, while other sectors like education, technology, and telecommunications show sporadic but less consistent presence
The network analysis suggests that government companies are more densely clustered around ANO Dialog (Regions) and its affiliated entities, such as READOVKA and REGIONAL CONTROL CENTER, indicating a tighter labor force connectivity with these core organizations. In contrast, media companies appear more dispersed across the network, with a lower concentration around ANO Dialog, reflecting a broader distribution of their activities and connections. This pattern may imply that government entities have a more centralized role or stronger operational ties with ANO Dialog, while media companies engage with a wider variety of nodes, potentially indicating diverse partnerships or influence across the network.
RQ3:
The findings show that ANO Dialog's headcount has remained stable and has not declined since Russia's full-scale invasion of Ukraine in 2022, with noticeable growth in headcount during this period. The data indicate a significant increase in activity after Russia injected funds into its federal budget following 2020, which also marked the start of this expansion. The Gantt chart reveals that ANO Dialog family companies, depicted in green, dominate the labor footprint over time, while other sectors like education, technology, and telecommunications show sporadic but less consistent presence
 RQ4:
We see that social media creation (591), journalism (1257), advertising (734), cultural arts and programming (491), and copywriting (492) are the most relevant categories of professional activities associated with the top 13 organizations. Journalism stands out as a dominant activity for entities like VGTRK, Medialogy, RT Russia 24, Stream TV company, and NTV TV Company. We found that Federal Television Enterprise Channel One OAO shows significant involvement in scientific and social research. Government and public policy activities are prominent for Roskomnadzor and Roskobrnadzor, while ANO Dialog excels in social media creation, reflecting the diverse strengths of these entities within the Russian disinformation and influence ecosystem.
RQ4:
We see that social media creation (591), journalism (1257), advertising (734), cultural arts and programming (491), and copywriting (492) are the most relevant categories of professional activities associated with the top 13 organizations. Journalism stands out as a dominant activity for entities like VGTRK, Medialogy, RT Russia 24, Stream TV company, and NTV TV Company. We found that Federal Television Enterprise Channel One OAO shows significant involvement in scientific and social research. Government and public policy activities are prominent for Roskomnadzor and Roskobrnadzor, while ANO Dialog excels in social media creation, reflecting the diverse strengths of these entities within the Russian disinformation and influence ecosystem.

RQ5:
Approximately 1% of companies in the dataset (39) were flagged as sanctioned entities. Despite their low numerical representation, sanctioned companies appear to be strategically nested in key labour sections, suggesting network-level embeddedness.
For example, most of the media entities that have been sanctioned for propaganda are located within the media industry market (as expected). As in the first phase of the research, ANO Dialog is close to the market of state-affiliated companies, and additional entities responsible for disseminating disinformation to foreign audiences, such as the Social Design Agency and Rossotrudnichestvo, are located in their own market cluster, which needs to be explored.

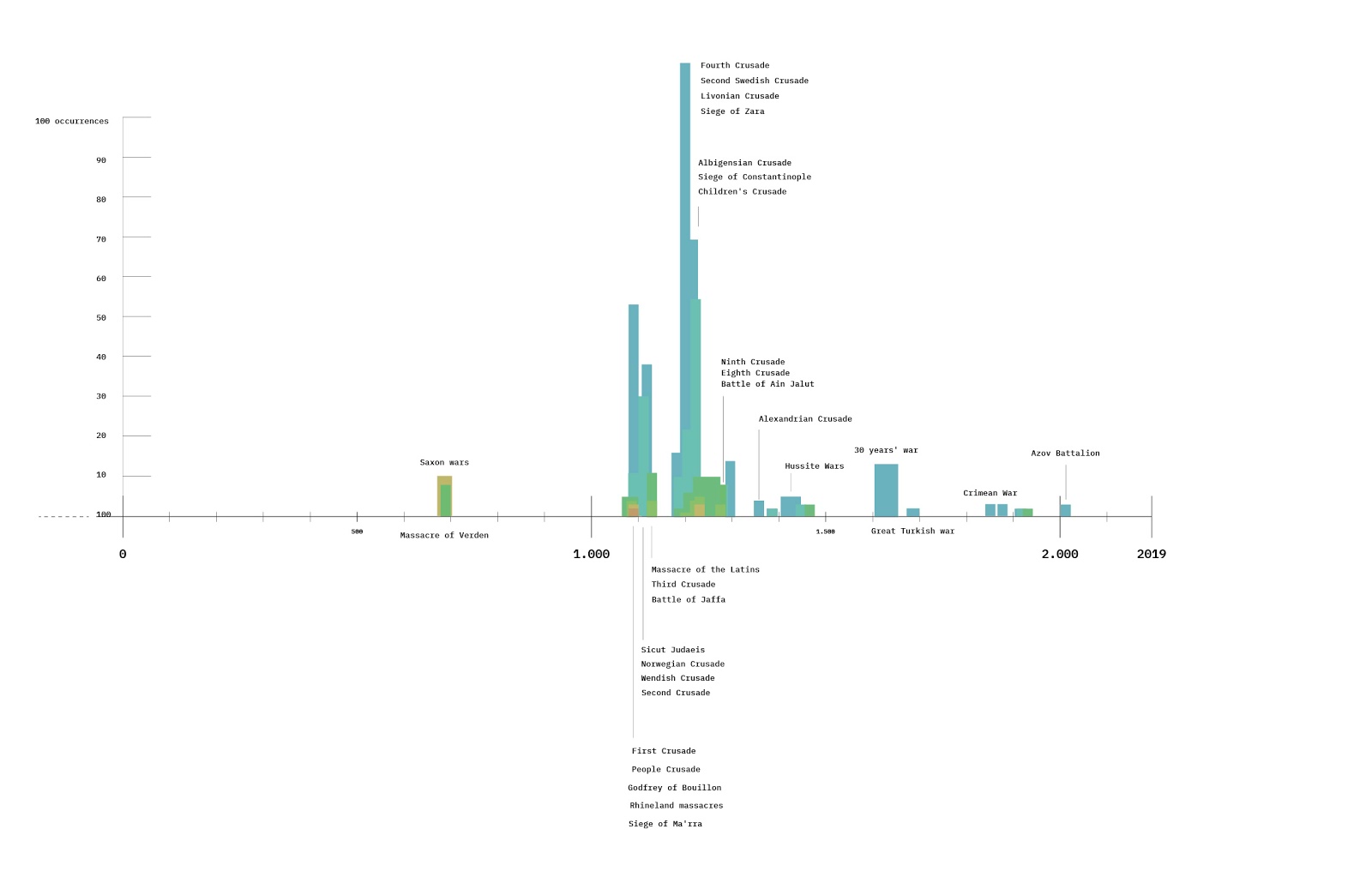
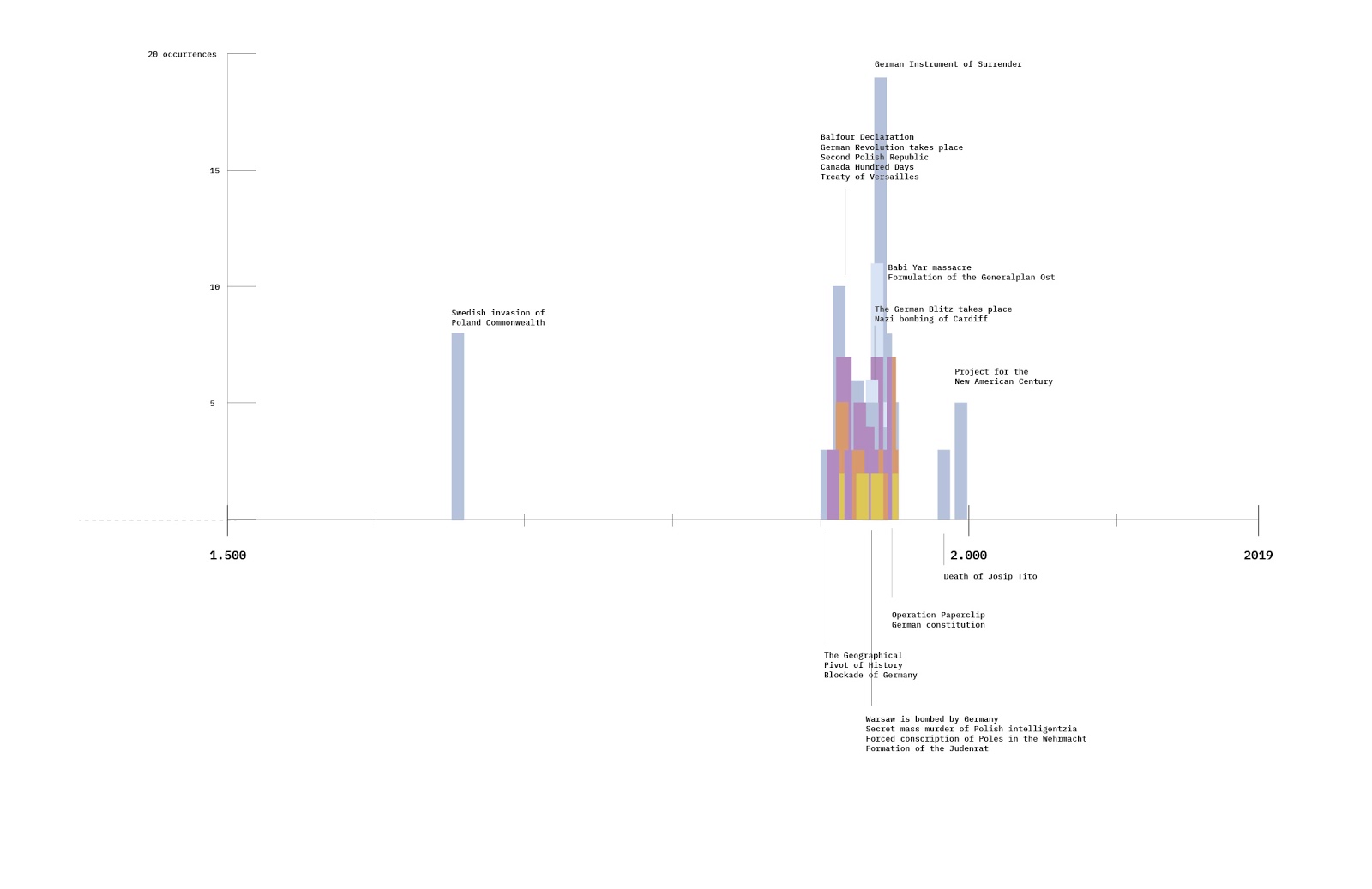
RQ6:
The graph shows the timeline of sanctions imposed on Russian organisations for disinformation, propaganda, or both. As can be seen, the first sanctions were imposed on Prigozhin’s “troll farm” in 2018. The size of the bubble represents the number of datasets the company appears in. This is used as a heuristic for relevance.

5. Discussion
While previous 'troll farms' in Russia (Poliakoff, 2025) and abroad (Grohmann & Ong, 2024) have been located in the media market, we see that the newest disinformation production organisations occupy different places in their societies' labour markets. In the case of ANO Dialog, for example, it is a market of state-affiliated companies, while in the case of the multi-company analysis, the position in the job market depends on the area of activity.
There are a number of concerns surrounding the discovery of sanctioned corporations via OpenSanctions. Firstly, we found discrepancies in the categorisation of Russian entities as relating to "disinformation" and/or “propaganda.” Both disinformation production organisations, such as ANO Dialog, which focus on manipulating public opinion, and propaganda media holdings, such as VGTRK, are sanctioned for 'propaganda and disinformation', even though the tasks their employees perform are certainly not the same - while VGTRK is mainly functioning as a traditional TV media holding, ANO Dialog is aimed to monitoring and control of the Russain social media space.
Secondly, we cannot state definitively that any company was sanctioned expressly for the reason of propaganda or disinformation. We can only state that these are companies that are sanctioned, and which are returned programmatically by the OpenSanctions API search function when queried with the given search term. OpenSanctions appears to return companies that contain the given search term in the notes field of the listing. However, this is only an educated guess; the precise mechanics are not known.
Lastly, if OpenSanctions does indeed rely on the notes field for querying, we could be missing a large number of relevant sanctioned corporations. Any corporation that did not contain the search term in its notes field would be skipped over by the API search function. Hypothetically, a dataset of companies sanctioned for disinformation could exist. The curators of said dataset may have a reason to include the word “disinformation” in every notes field, because the sanction reason is apparent from the purpose of the dataset. Future work is necessary to understand the implementation of the OpenSanctions API search function, and whether that implementation could be missing relevant results.
Nevertheless, the findings of RQ4 show that all of the sanctioned organisations are active on social media, so additional enquiry into their organisational dynamics is required.
6. Conclusions

A combination of pattern detection and OSINT is recommended to identify previously unsanctioned companies within the dataset, that may meet criteria for sanctions, while minimizing false positives:
Firstly, all companies of interest should be included in a shortlist for further inspection. Inclusion criteria are significant overlap in staff, job titles, job descriptions, employee backgrounds or employee experience with sanctioned companies or companies linked to information operations.
Secondly, company profiles should be created for all companies who are sanctioned, have been linked to information operations or are now defined as companies of interest. These profiles should include the company’s self description, their job titles, job descriptions, employee background and their previous employers. Where available, external references to the company’s activities (e.g. media coverage) and specific references from information operation research, leaked documents and sanction status should be added to complete the profile.
Thirdly, profiles of companies of interest should be assessed in two steps. Manual assessment should inquire for technical, behavioral and circumstantial evidence indicating affiliation with or activities in the field of disinformation and propaganda. Subsequently, a company of interest’s profile should be compared to those of companies that are already sanctioned or have been linked to information operations in the past.
Finally, after integrating these findings, companies of interest should be assigned a probability of sanction eligibility. Assessment should conclude with a recommendation for either dismissal, further research or screening for sanction eligibility. These results should be made available to the Council of the European Union for further inspection.
7. References
-
Grohmann, R., & Ong, J. C. (2024). Disinformation-for-hire as everyday digital labor: Introduction to the special issue. Social Media + Society, 10(1).
-
Polyakova, A., & Meserole, C. (2019, August). Exporting digital authoritarianism: The Russian and Chinese models (Democracy and Disorder Series, Policy brief).
-
Poliakoff, S., Toepfl, F., & Kling, J. J. (2025). From trolling to orchestrating public opinion: How ANO Dialog innovates the Kremlin’s digital propaganda apparatus [Unpublished Manuscript]
-
Poliakoff, S., & Kling, J. (2025). Curriculum vitae analysis as a novel method for studying disinformation production organizations [Unpublished manuscript]
-
Pamment, J., & Tsurtsumia, D. (2025, August). Beyond Operation Doppelgänger: A capability assessment of the Social Design Agency (MPF Report Series). Psychological Defence Agency.
-
Poliakoff, S. (2025, March 31). Nach dem Aufstand: der Untergang von Jewgenij Prigoschins digitalem Imperium [After the uprising: The downfall of Yevgeny Prigozhin’s digital empire]. Russland-Analysen, (454), 16–20.
Appendix
| Table 0: Expanded list of search queries | |
|---|---|
| Search term | Simple translation |
| диалог регионы | dialogue regions |
| автономная некоммерческая организация диалог | autonomous non-profit organization dialogue* |
| ано диалог | ano dialogue* |
| центр управления регионом | regional control center |
| цур | tsur |
| вконтакте | vkontakte |
| одноклассники | odnoklassniki |
| ано россия страна | ano rossiya strana* |
| агентство социального проектирования | social design agency |
| медиалогия | medialogy |
| госпаблик | gospublik |
| медиалогия инцидент | medialogy incident |
| медиалогия.инцидент | medialogy.incident |
| госуслуги | gosuslugi |
| нейрум | neurum |
| роскомнадзор | roskomnadzor |
| Решаем вместе | We decide together |
| Добродел | Dobrodel |
| Ано эиси | Ano eisi* |
| эиси | eisi |
| дит | dit |
| департамент информационных технологий | department of information technologies |
| ИРИ | IRI |
| Институт развития интернета | Institute for Internet Development |
* Autonomous Non-Profit Organization (ANO) is a legal entity similar to a non-profit NGO.
| Table 1: Output of analysis of 1898 JSON objects from data scrapped in summer 2023. | ||||
|---|---|---|---|---|
| Key | Count | # Unique | (% Unique) | Types |
| path | 1898 | 1796 | (95%) | str(1898) |
| id_hh | 1898 | 1796 | (95%) | str(1898) |
| lastUpdateDate | 1706 | 480 | (28%) | str(1706) |
| citizenship | 1890 | 8 | (0%) | str(1890) |
| workPermit | 1890 | 21 | (1%) | str(1890) |
| gender | 1890 | 4 | (0%) | str(1890) |
| city | 1890 | 181 | (10%) | str(1890) |
| selfDescription | 1538 | 1424 | (93%) | str(1538) |
| educationLevel | 1890 | 11 | (1%) | str(1890) |
| experience | 1898 | 0 | (0%) | list(1898) |
| experience.startDate | 12002 | 347 | (3%) | str(12002) |
| experience.startAge | 12002 | 1 | (0%) | str(12002) |
| experience.currentlyWorking | 3251 | 1 | (0%) | bool(3251) |
| experience.company | 12002 | 7134 | (59%) | str(12002) |
| experience.companyCity | 6849 | 2714 | (40%) | str(6849) |
| experience.companyIndustries | 12002 | 45 | (0%) | str(12002) |
| experience.companyPosition | 12002 | 5121 | (43%) | str(12002) |
| experience.companyDescription | 12002 | 9230 | (77%) | str(12002) |
| experience.endDate | 8751 | 310 | (4%) | str(8751) |
| experience.endAge | 8751 | 1 | (0%) | str(8751) |
| keySkills | 1898 | 1695 | (89%) | str(1898) |
| education | 1898 | 0 | (0%) | list(1898) |
| education.graduationYear | 5011 | 46 | (1%) | str(5011) |
| education.institution | 4992 | 1351 | (27%) | str(4992) |
| education.description | 4962 | 2511 | (51%) | str(4962) |
| additionalEducation | 1898 | 0 | (0%) | list(1898) |
| additionalEducation.graduationYear | 2934 | 31 | (1%) | str(2934) |
| additionalEducation.institution | 2934 | 1810 | (62%) | str(2934) |
| additionalEducation.description | 2934 | 1824 | (62%) | str(2934) |
| languages | 1898 | 0 | (0%) | dict(1898) |
| languages.Русский | 1858 | 2 | (0%) | str(1858) |
| languages.Английский | 1367 | 7 | (1%) | str(1367) |
| languages.Немецкий | 154 | 6 | (4%) | str(154) |
| portfolio | 1898 | 0 | (0%) | list(1898) |
| salaryLevel | 1048 | 73 | (7%) | str(1048) |
| drivingExperience | 837 | 18 | (2%) | str(837) |
| languages.Французский | 96 | 6 | (6%) | str(96) |
| languages.Russian | 8 | 1 | (12%) | str(8) |
| languages.English | 8 | 3 | (38%) | str(8) |
| languages.Spanish | 2 | 1 | (50%) | str(2) |
| languages.Turkish | 2 | 1 | (50%) | str(2) |
| languages.Итальянский | 30 | 5 | (17%) | str(30) |
| languages.Испанский | 68 | 6 | (9%) | str(68) |
| languages.Украинский | 38 | 5 | (13%) | str(38) |
| languages.Осетинский | 7 | 4 | (57%) | str(7) |
| languages.Португальский | 10 | 3 | (30%) | str(10) |
| languages.Турецкий | 17 | 6 | (35%) | str(17) |
| languages.Якутский | 4 | 3 | (75%) | str(4) |
| languages.Чешский | 4 | 2 | (50%) | str(4) |
| languages.Армянский | 5 | 4 | (80%) | str(5) |
| languages.Китайский | 32 | 6 | (19%) | str(32) |
| languages.Польский | 12 | 4 | (33%) | str(12) |
| languages.Татарский | 19 | 7 | (37%) | str(19) |
| languages.Корейский | 8 | 4 | (50%) | str(8) |
| languages.Латинский | 4 | 2 | (50%) | str(4) |
| languages.Удмуртский | 2 | 2 | (100%) | str(2) |
| languages.Румынский | 3 | 3 | (100%) | str(3) |
| languages.Иврит | 3 | 3 | (100%) | str(3) |
| languages.Карачаево-балкарский | 3 | 2 | (67%) | str(3) |
| languages.Японский | 8 | 5 | (62%) | str(8) |
| languages.Азербайджанский | 5 | 2 | (40%) | str(5) |
| languages.Финский | 3 | 3 | (100%) | str(3) |
| languages.Казахский | 1 | 1 | (100%) | str(1) |
| languages.Узбекский | 2 | 2 | (100%) | str(2) |
| languages.Литовский | 1 | 1 | (100%) | str(1) |
| languages.Персидский | 5 | 3 | (60%) | str(5) |
| languages.Арабский | 5 | 5 | (100%) | str(5) |
| languages.Башкирский | 3 | 2 | (67%) | str(3) |
| languages.Пушту | 1 | 1 | (100%) | str(1) |
| languages.French | 2 | 2 | (100%) | str(2) |
| languages.German | 1 | 1 | (100%) | str(1) |
| languages.Ингушский | 1 | 1 | (100%) | str(1) |
| languages.Монгольский | 1 | 1 | (100%) | str(1) |
| languages.Тувинский | 3 | 3 | (100%) | str(3) |
| languages.Сербский | 3 | 3 | (100%) | str(3) |
| languages.Хинди | 1 | 1 | (100%) | str(1) |
| languages.Таджикский | 2 | 2 | (100%) | str(2) |
| languages.Чеченский | 4 | 3 | (75%) | str(4) |
| languages.Болгарский | 2 | 2 | (100%) | str(2) |
| languages.Белорусский | 2 | 2 | (100%) | str(2) |
| languages.Кабардино-черкесский | 2 | 2 | (100%) | str(2) |
| languages.Хорватский | 1 | 1 | (100%) | str(1) |
| languages.Шведский | 1 | 1 | (100%) | str(1) |
| languages.Греческий | 1 | 1 | (100%) | str(1) |
| languages.Голландский | 1 | 1 | (100%) | str(1) |
| languages.Талышский | 1 | 1 | (100%) | str(1) |
| Table 2: Translations of “disinformation” and “propaganda” into languages common in OpenSanctions source datasets. | ||
|---|---|---|
| Language(s) | Translation of “disinformation” | Translation of “propaganda” |
| English, Swedish, Danish, Dutch | disinformation | propaganda |
| French | désinformation | propagande |
| Spanish | desinformación | ** |
| Portuguese | desinformação | ** |
| German | Disinformation | Propaganda |
| Italian | disinformazione | ** |
| Russian, Bulgarian | дезинформация | пропаганда |
| Polish | dezinformacja | ** |
| Hungarian | dezinformáció | ** |
| Czech | dezinformace | ** |
| Slovak | dezinformácie | ** |
| Romanian | dezinformare | ** |
| Croatian, Serbian, Slovene | dezinformacija | ** |
| Greek* | παραπληροφόρηση | προπαγάνδα |
* Note: this translation is approximate; the word παραπληροφόρηση is perhaps better translated as “misinformation.” The distinction in English is fairly important.
** Non-unique translations excluded from table for readability.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback