25 years of New Media Studies: Mapping the field, reimagining the tools
Team Members
Facilitators: Gabriel Pereira, Marc Tuters, Sabine Niederer, Carlo De Gaetano, Lonneke van der Velden, Riccardo Ventura
Participants: Ray Dolitsay, Hanna Lauvli, Lisabeth Matyash Leonsins, Mariana Fernandez Mora, David Schogt, Anvee Tara, Jiahui Xing, Angxiao Xu
Contents
Summary of Key Findings
This project maps the evolving landscape of New Media Studies over the past 25 years by combining semantic clustering, topic modelling, and narrative synthesis—developed through a locally-run small language model. Drawing inspiration from handbooks like Keywords for Studying Media, Culture & Information and Critical Terms for Media Studies, alongside an interest in AI-assisted methods for topic modelling, we inductively constructed a field guide from 28,624 articles, identifying key conceptual formations and their changing prominence over time. We were particularly interested in mapping not just stable concepts, but dynamic thematic patterns and cultural formations—what we provisionally refer to as “vibes.”From early concerns with technological determinism and internet history to the rising dominance of AI and platform governance, the field has continually remediated its own epistemic infrastructures. Rather than simply tracking content, we approached this as a “vibe-mapping” exercise—mapping the shifting trajectories that structure New Media scholarship through its semantic meaning.
One striking insight is the dramatic recent surge in work on artificial intelligence—especially in 2023–2024—highlighting a shifting centre of gravity in the field. Yet to focus solely on AI would risk presentism. The longer view reveals New Media Studies as a field of mediation in multiple senses: methodologically hybrid, temporally layered, and infrastructurally reflexive. Recurring threads such as surveillance & privacy, mobile media, and remix culture echo across decades, while emergent concerns—like digital memory, gender queerness, and hate speech—point to new paradigms of engagement.
The project also reflects critically on its own methods, questioning what it means to prototype scholarly tools with “small AI.” By working with locally-run LLMs for vector embedding, we seek to reimagine academic infrastructures not as extractive or commercial, but as collaborative, sustainable, and epistemically generative. This methodological commitment parallels the conceptual goal of the project: to co-develop scholarly infrastructures that are attuned to the language, logics, and values of the field itself. In doing so, Vibe-Mapping New Media contributes both a historiographic synthesis and a speculative gesture: a bottom-up field guide, shaped by the resonances that circulate through—and constitute—the field itself.
1. Introduction
This project set out to explore a dataset of publications in the field of “new media” to develop an encyclopaedia of concepts (or a book/reader of key terms or another similar interface), including references for further research—potentially resulting in a novel kind of field-defining reference work, not unlike a handbook but generated inductively via citation and semantic mapping techniques.
This work builds on earlier meta-analytical approaches to mapping scientific domains, such as co-word and co-citation analysis (Callon et al. 1986; Callon, Courtial, and Laville 1991), applying these methods to the field of New Media in a novel, LLM-assisted context. But the work is also driven by a wish to create our own interfaces for doing research, based on the specific questions and needs of our field. What if these tools followed our values and interests? What if these tools could be locally-run, as opposed to owned and operated by large tech conglomerates? What if LLMs could be used in a way that wasn't so polluting?
Therefore, in parallel to developing a small AI tool for navigating New Media scholarship, the project also aims to reflect critically on the discourse surrounding ‘small’ or ‘minor’ AI. What imaginaries, metaphors, and problem framings guide this emerging field? What values are embedded in these alternatives—and how might they reshape our understanding of AI’s role in research? These reflections inform both our design and our critique, and are elaborated in the section titled "Small AI".
This report makes three key contributions. First, it introduces a novel hybrid methodology that combines expert-curated taxonomies with inductive topic modeling to surface both established and emergent conceptual structures in New Media Studies. Second, it offers a concrete implementation of this method using open-source, small-scale LLM infrastructure—demonstrating a viable alternative to commercial AI tools. Third, it reflects critically on the epistemological and infrastructural assumptions embedded in both deductive and inductive approaches, contributing to wider debates about reflexive research methods, field formation, and the politics of knowledge organization.
2. Initial datasets
The Vibe-Mapping New Media project explores the use of small, locally-run language models to inductively map the conceptual structure of New Media Studies.
2.1 The data-set
Baseline Corpus Construction for the Vibe-Mapping New Media Project





We constructed a baseline corpus for New Media Studies through a multi-step process combining expert curation and LLM-assisted taxonomy generation. We extracted key concepts using handbooks, and curated online glossaries. The result was a field-specific conceptual taxonomy designed to support our vibe-oriented exploratory semantic mapping.
We scraped online lists and glossaries (e.g., Wikipedia’s digital media glossaries, AI ethics vocabularies, participatory design sites) to capture current and emerging terms. Lists were collected via snowballing (eg. known glossaries, calls for glossaries and references from those glossaries to inspirational lists) and prompting ChatGPT for glossaries of key terms in New Media and Digital Culture. After review, the following list of urls was selected
-
https://textaural.com/keywords/
-
https://datasociety.net/library/keywords-of-the-datafied-state/
-
https://policyreview.info/glossary/introducing-decentralised-technosocial-systems
-
https://purdue.edu/critical-data-studies/collaborative-glossary/about-glossary.php
-
https://ainowinstitute.org/collection/a-new-ai-lexicon/page/2
-
https://open.oregonstate.education/new-media-futures/back-matter/glossary/
-
https://uw.pressbooks.pub/mediacriticalapproaches/back-matter/glossary/
-
https://drstephenrobertson.com/glossary/
-
https://folgerpedia.folger.edu/Glossary_of_digital_humanities_terms
-
https://dsg.northeastern.edu/dsg-glossary/
-
https://digitalfuturesociety.com/glossary-page/
-
https://culturalpolitics.net/index/digital_cultures/glossary
-
https://www.bloomsbury.com/uk/posthuman-glossary-9781350030244/
For our corpus of handbooks we selected Keywords for Studying Media, Culture & Information, Critical Terms for Media Studies, The SAGE Handbook of Media Studies, Uncertain Archives, as well as lists
-
Coyer, K., & Dowmunt, T. (Eds.). (Year unknown). The alternative media handbook. Publisher.
-
Dewdney, A., & Ride, P. (Eds.). (Year unknown). The digital media handbook. Publisher.
-
Flew, T., Holt, J., & Thomas, J. (Eds.). (2023). The SAGE handbook of the digital media economy. SAGE Publications .
-
Gane, N., & Beer, D. (Eds.). (Year unknown). The key concepts new media. Publisher.
-
Hjorth, L., & Khoo, O. (Eds.). (Year unknown). Routledge handbook of new media in Asia. Publisher.
-
Kennerly, M., Frederick, S., & Abel, (Eds.). (Year unknown). Information keywords. Publisher.
-
Lister, M., Dovey, J., Giddings, S., & [Incomplete]. (Year unknown). New media: A critical introduction (2nd ed.). Publisher.
-
Lievrouw, L., & Livingstone, S. (Eds.). (2006). Handbook of new media: Social shaping and consequences of ICTs. Sage.
-
Mitchell, W. J. T., & Hansen, M. B. N. (Eds.). (2010). Critical terms for media studies. University of Chicago Press.
-
Ott, B. L. (Year unknown). Critical media studies: An introduction. Publisher.
-
Ouellette, L., & Gray, J. (Eds.). (Year unknown). Keywords for media studies. Publisher.
-
Peters, B. (Ed.). (Year unknown). Digital keywords. Publisher.
-
Rohlinger, D. A., & Sobieraj, S. (Eds.). (Year unknown). The Oxford handbook of digital media socio. Publisher.
-
Thylstrup, N., et al. (Eds.). (Year unknown). Uncertain archives. Publisher.
-
Trepte, S., & Masur, P. K. (Eds.). (Year unknown). The Routledge handbook of privacy and society. Publisher.
-
Whittaker, J. (Ed.). (Year unknown). The cyberspace handbook. Publisher.
Primary Corpus for Vibe Mapping
Our primary corpus consisted of 28,624 publication records (titles, abstracts, metadata) drawn from 35 scholarly journals associated with New Media Studies. These included venues from a varied set of disciplines and topics across media theory, digital culture, science & technology studies, and communication studies. We collectively decided on which journals best fit with a broad understanding of “new media studies”. A key limitation emerged here: we worked exclusively with English-language journals, thus biasing the data set towards Europe and the USA, thus reinforcing the problematic reification of English as ‘lingua franca’ (see Suzina 2021).
This dataset was retrieved using the VibeCollector tool. The tool uses different sources to gather the data: CrossRef, SemanticScholar, and OpenAlex (in this order of preference). For articles without date or abstract, a different source was used to enrich the data. Some journals could not be included because they were not indexed by the data sources or did not have an ISSN number.
Final data-set:
-
The full data-set organized by article (ISSN as file name): https://github.com/gabrielopereira/VibeMappingDMI/tree/main/fullfetcheddata
-
Data-set used in our research, spanning 2000-2024: https://github.com/gabrielopereira/VibeMappingDMI/tree/main/dynamic_topic_results_without2025
2.2 Data cleaning
We followed a 5-step program to clean the data-set dynamic_topic_results_without2025Please note: when running these scripts, make sure the file titles are updated correctly and correspond to the file title you’re running it on (all scripts here: https://github.com/gabrielopereira/VibeMappingDMI/tree/main)
-
Remove XML tags
To remove the XML-tags that journals often use, we ran the below Python script: remove_jats_tags.py
-
Separate Book Reviews from the main dataset
We then separated book reviews from the data-set by running Extract_book_reviews.py (it separates the book reviews into a separate csv file)
-
Separate Editorials from the main dataset
To split and remove editorials from the data-set we ran: split_editorials.py (this one also creates separate csv files).
-
Re-create full data set: 25 years of New Media (2000 - 2024). Divided year by year
After cleaning, we removed years before 2000 and the year 2025 (considering it's an ongoing year with still incomplete records).
-
Creating topic keywords for analysis
For creating the keywords for each topic, BERTopic was used to remove stopwords. We used the collection of stopwords from the CountVectorizer library (in English) and a minimum presence in 3 of the topic's documents (thus removing infrequent keywords from surfacing). We enabled longer keywords, up to 3 words long (e.g. so “algorithmic surveillance” could be a word). We also used BERTopic's c-TF-IDF function, which refined keywords according to their relative importance to each year (evolutionary) and topic (global). -
(Optional) Verification step: counting objects
To count the amount of objects per data-set and thereby verify the effectivity of previously described data-cleaning (across devices), we used a python script called count_objects.py
2.3 Model exploration
We explored the different hyperparameters of the model to test out how they shape the outputs. For this, we used a Google Colab and a local Jupyter Lab (https://jupyter.org/try-jupyter/lab/). Following BERTopic best practices guidelines the following hyperparameters were tested and adjusted:n_neighbors=n
n_components=n
min_cluster_size=n
top_n_words=n
Final code used to run BERTopic: https://github.com/gabrielopereira/VibeMappingDMI/blob/main/dynamictopic.py
See an example of model exploration in the attachments.3. Research Questions
Departing from our baseline analysis, our core questions were:
-
What key concepts define the field of New Media Studies today?
-
Can we construct a bottom-up conceptual map using both hand-curated and LLM-assisted techniques?
-
How do these methods compare to traditional top-down handbooks or expert taxonomies?
4. Methodology
4.1 Deductive
Our methodology for creating the baseline began by analysing influential handbooks and lists of keywords. From these texts, we extracted 500 conceptual terms, normalising and deduplicating them. We prompted LLMs with seed terms to generate concept expansions, particularly in thematic clusters. All terms were organised into a hierarchical structure across thematic categories (e.g., Media Temporalities, Aesthetics & Experience, Knowledge & Epistemology, Posthuman & Speculative). This resulted in an expanded conceptual taxonomy of the field. This mapping emphasized the conceptual vocabularies, critical orientations, and emergent sensibilities that define the reflexive and theoretical dimensions of the field. It highlighted how New Media Studies articulates concerns around power, representation, affect, and infrastructural design, often through neologisms, poetic metaphors, and speculative framings.4.2 Inductive
To inductively “vibe map” 25 years (2000–2024) of New Media Studies, we used BERTopic semantic topic modelling with vector embeddings. Titles and abstracts were combined and embedded using the small model Snowflake/snowflake-arctic-embed-s to capture the semantic meaning of each publication. BERTopic uses UMAP for dimensionality reduction and HDBSCAN for clustering.We tested different hyperparameters across four benchmark years (2005, 2010, 2018, 2024) to evaluate stability and conceptual shifts. The outcome was the clustering of semantically similar articles, each represented by a set of keywords, refined through stopword removal using c-TF-IDF. Outliers were connected to their most probable topic so all articles had a topic.
BERTopic then subdivides documents in each topic by year, allowing to see the evolution of the keywords used.
After inductively mapping the field across the years, we fed all the spreadsheets for all the topics into an LLM (ChatGPT -4o). The model was prompted to: (1) extract the 10 most frequently occurring non-common terms from the title_abstract fields, (2) compress those into a short list of representative keywords, and (3) suggest descriptive titles for each topic.
| topic | top_keywords | compressed_keywords | final_matched_concept |
| 0 | ['ai', 'human', 'artificial', 'intelligence', 'social', 'systems', 'algorithmic', 'data', 'algorithms', 'machine'] | ai human artificial intelligence | Artificial Intelligence |
| 1 | ['game', 'games', 'play', 'video', 'gaming', 'players', 'player', 'media', 'digital', 'new'] | game games play video gaming | Game Studies |
| 2 | ['television', 'media', 'article', 'tv', 'public', 'new', 'cultural', 'service', 'series', 'social'] | television media article tv | Television & Public Media Cultures |
| 3 | ['surveillance', 'social', 'paper', 'data', 'article', 'cctv', 'studies', 'public', 'new', 'technologies'] | surveillance social paper data | Surveillance & Data Governance |
We then verified all the topic titles manually guided by domain expertise and the deductive field mapping. We found the topics, in general, were coherent. However, we removed 8 topics that were unrelated to new media (e.g. corrigendums). In another step we fed a spreadsheet with all the title_abstracts per individual topic into the LLM. In many cases this seemed to provide good labels that we fine-tuned manually.
Building upon this initial baseline research, we then analyzed the relative frequency of publications per topic over the past 25 years. This temporal analysis allowed us to identify key shifts, continuities, and emerging patterns within the field, and informed a series of interpretive “vibe stories” that narrativize these conceptual developments.
5. Findings
5.1 Baseline
The final taxonomy comprises two interlocking layers: one deductive and one inductive. The deductive layer includes approximately 500 discrete entities extracted from over 30 canonical handbooks in the field. These concepts—ranging from "interface politics" to "cultural techniques"—provided a structured baseline from which we could evaluate the contours of the field. Together, these layers offer a dynamic and situated vocabulary for the field—attuned both to institutional memory and to evolving cultural and technological conditions.
Algorithm: algorithm, algorithmic bias, algorithmic governance, algorithmic moralism, algorithmic racism, algo-informatic bodies, automated suspicion, computational opacity, computational parallax, content moderation politics, machine unlearning, Archive: annotated archival description (ead), archive, archival data, haunted archives, metadata, descriptive metadata, digital editions, digital exhibits, digital object, digital preservation, digitextuality, file formats, handle, institutional repository (ir), permanent url, Data: big data, big data swindling, data, data broker, data cleaning, data colonialism, data curation, data extraction, data hauntology, data management, data mining, data modeling, data publics, data profiling, data sovereignty, data visualization, database, dataveillance, missing data, raw data, Digital Identity: anonymity, default identity, digital ids, digital identity, identity, identity infrastructures, identity tourism, name disambiguation, profile, synthetic subjectivity, user, user-centric technology, user complicity, Infrastructure: affordance, affordances of social media, api, application programming interface (api), apparatus, apparatgeist, architecture, cascading style sheets (css), command-line interface (cli), content management system, controlled vocabulary, digital repository, digital scholarship commons (dsc), interface, infrastructure, institutions, repository, sensorial infrastructure, software, structured data, style sheet, interoperability, network protocols, Platform: aca-fan, affinity portals, api, application programming interface (api), blog, blogebrity, counterpublic platforms, platform, platform capitalism, platform governance, platform realism, social networking sites (snss), user interface, comment sections, alt-tech platforms, Surveillance: algorithmic governmentality, ambient authoritarianism, dataveillance, disinhibition, epistemic injustice, gendered interfaces, identity infrastructures, intersectional surveillance, panoptic, privacy by design, privacy enhancing technologies, surveillance, surveillance capitalism, technopolitical imaginaries, predictive policing, behavioral tracking, Affect & Embodiment: affect, affective arrangement, affective economy, affective infrastructures, affective networks, affective publics, affective turn, aesthetics, authenticity, embodiment, empathy, glitch feminism, haunted media, mediated intimacy, posthuman bodies, queer temporality, sensorial infrastructure, situated knowledge, symbolic interactionism, mood, vibes, Politics & Governance: activism, bias, carcerality, censorship, civil law, critical legal studies, cultural imperialism, data justice, disembodiment, dissent, epistemic injustice, exclusion, freedom of speech, hegemony, human rights, indigenous data sovereignty, liberal democracy, political ecology, power, precarity, privilege, public administration, public interest, public interest technology, reparative media, resonant misinformation, surveillance capitalism, tactical media, technopolitical imaginaries, toxic technoculture, authoritarian populism, infrastructural critique, Cultural & Media Theory: (in)justice, aca-fan, art, art in the anthropocene, audience, audience commodity, audience fragmentation, blog, community, cosmopolitan, cosmopolitics, cultural studies, infotainment, media effects, media literacy, mediation, memes, myths, narrative, participatory culture, passive audience, phenomenology, pleasures, plot, posthumanism, prosumer, scopic regimes, semiotics, slow media, smart, social good, story, structuralism, virtual community, virtuality, cultural analytics, media materialism, Technology & Design: 3d models, analog, analog nostalgia, analog technology, application programming interface (api), artificial intelligence, artificial scarcity, blockchain scenes, cascading style sheets (css), command-line interface (cli), computational opacity, computational parallax, content management system, controlled vocabulary, data visualization, digital publishing, empathic computing, game gaze, gamification, hardware-software-wetware, interface anxiety, interoperability, json, leet, machine learning, materiality, platform realism, speculative infrastructures, speculative visualization, technological determinism, technological mysticism, technology for social inclusion, text analysis, text encoding, text mining, topic modeling, virtual reality, visualization, wearable computers, xml, user-centered design, HCI, UX/UI, Media Temporalities: queer temporality, slow media, digital exhaustion, viral, real-time, latency, liveness, archival time, Aesthetics & Experience: glitch feminism, ambient noise, haunted media, post-truth affect, mediated intimacy, immersive aesthetics, techno-sublime, Knowledge & Epistemology: epistemic injustice, opacity politics, unthought media, post-truth affect, information disorder, platform epistemology, computational hermeneutics, Posthuman & Speculative: machinic desire, posthuman bodies, synthetic subjectivity, cosmic pessimism, technological mysticism, human–machine symbiosis, speculative realism, neurodiverse design, Platform Politics & Governance: memetic warfare, content moderation politics, user complicity, resonant misinformation, disinhibition, comment moderation, algorithmic nudging, Digital Economies: platform capitalism, surveillance capitalism, data colonialism, precarity, monetisation, gig economy, digital labor, creator economy, Security & Conflict: conspiracy, ambient authoritarianism, toxic technoculture, automated suspicion, digital conflict, cyberwarfare, information operations, adversarial media, trolling, polarization dynamics
5.2 Inductive
The inductive layer was derived from the topic model trained on a curated corpus of 28,624 articles spanning 25 years of New Media Studies (2000-2024). This method surfaced latent semantic clusters that revealed both enduring research themes and surprising emergent concerns. The vocabulary uncovered here shows internal coherence—demonstrating clear associations among the titles and abstracts with keywords such as "memes," "right," and "online," or between "influencers," "Instagram," and "selfie"—as well as distinctive temporal patterns. Several emergent fields included concepts absent from canonical works, such as "quantified self," "TikTok cultures," and "toxic technoculture," validating the relevance of our hybrid expert–machine approach. The inductive approach resulted in 75 topics, but after our analysis, we decided to remove some that related to irrelevant clusters (e.g. “Editorials” or “Correction” were grouped in their own topics, indicating some still survived our initial data cleaning). Ultimately, we reached 67 topics that were validated through manual analysis of the articles present in them. These revealed a landscape composed of programmatic clusters around topics of matter for the field. In order of prominence, those topics were labelled as:
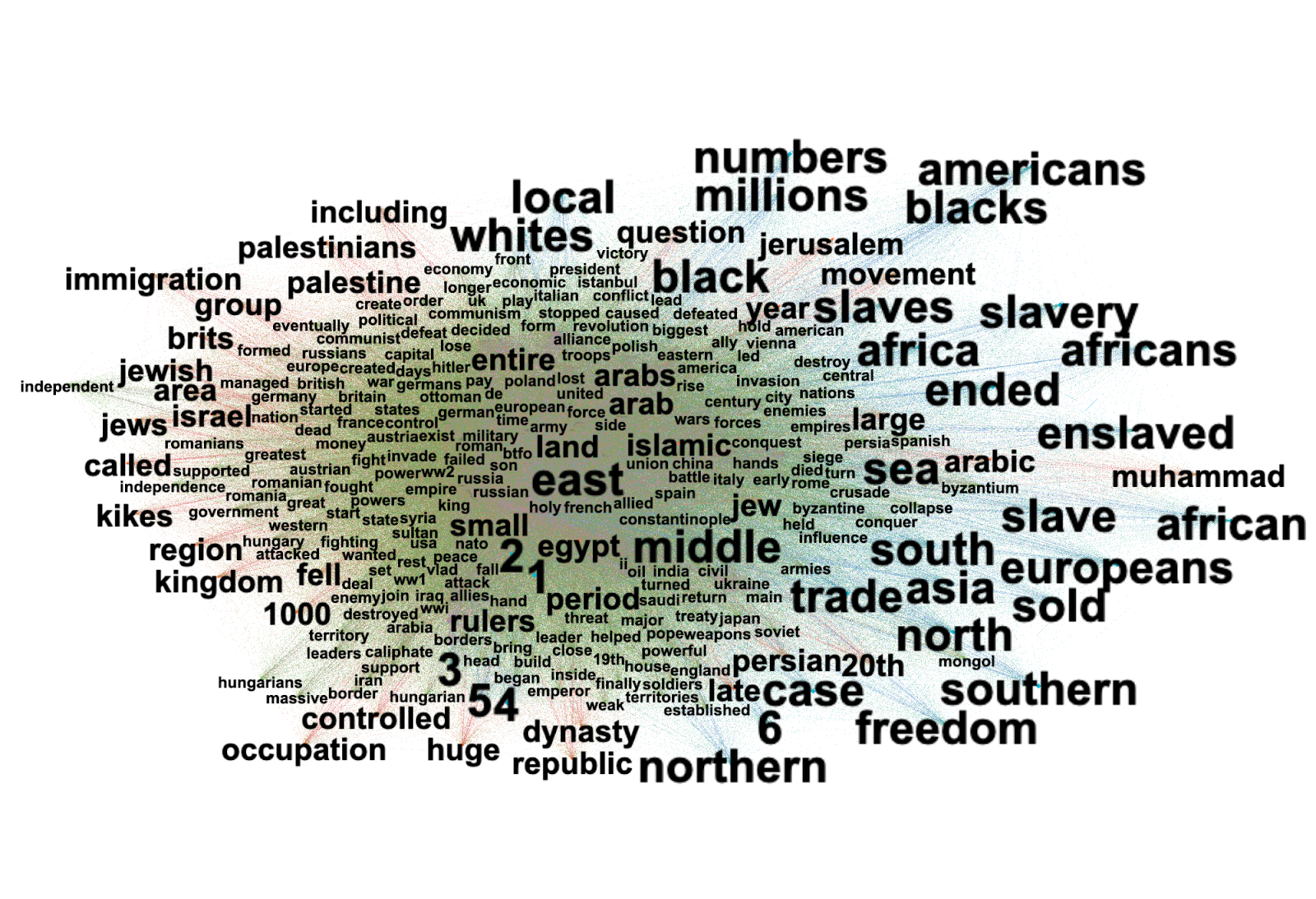
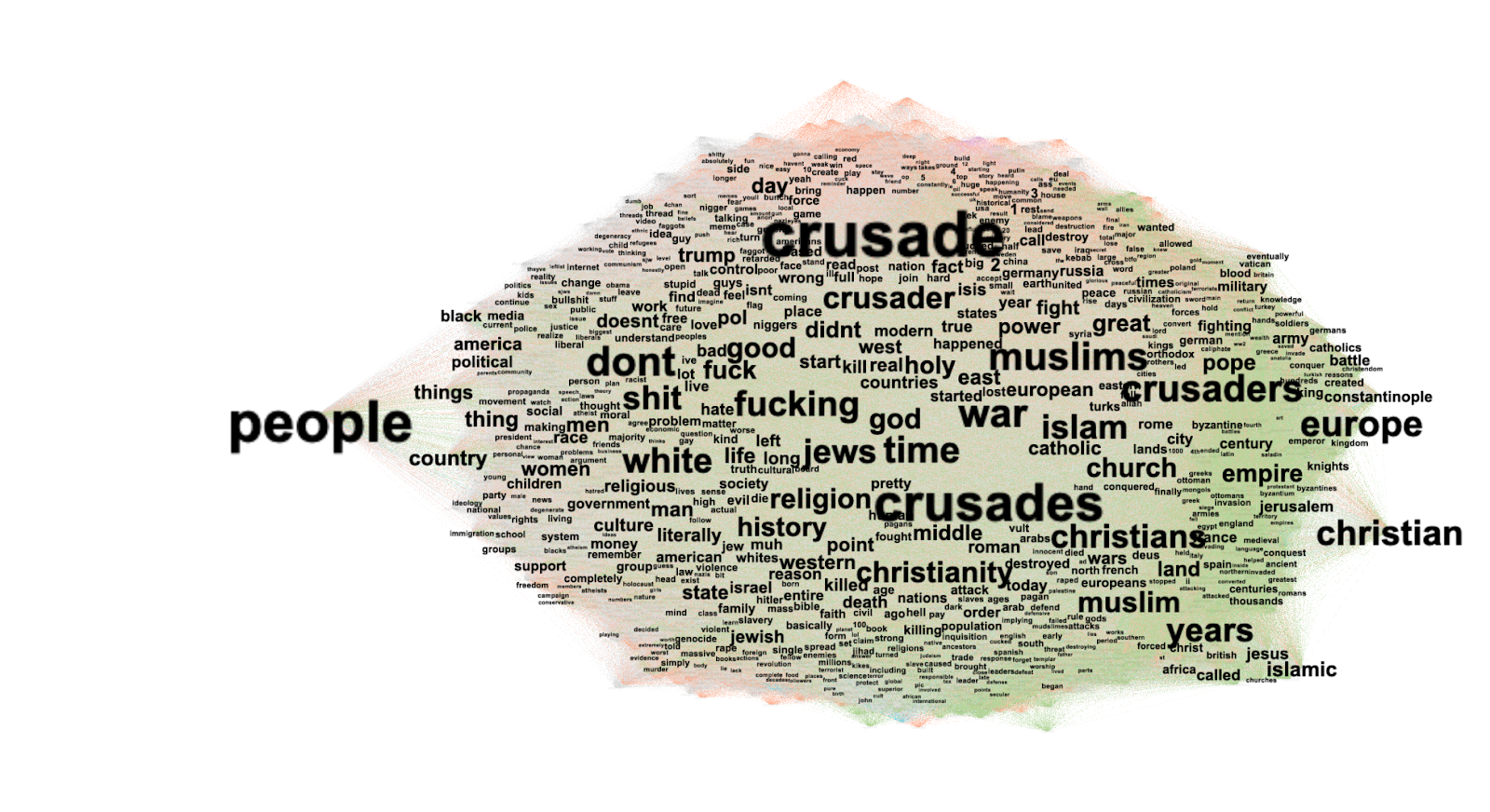
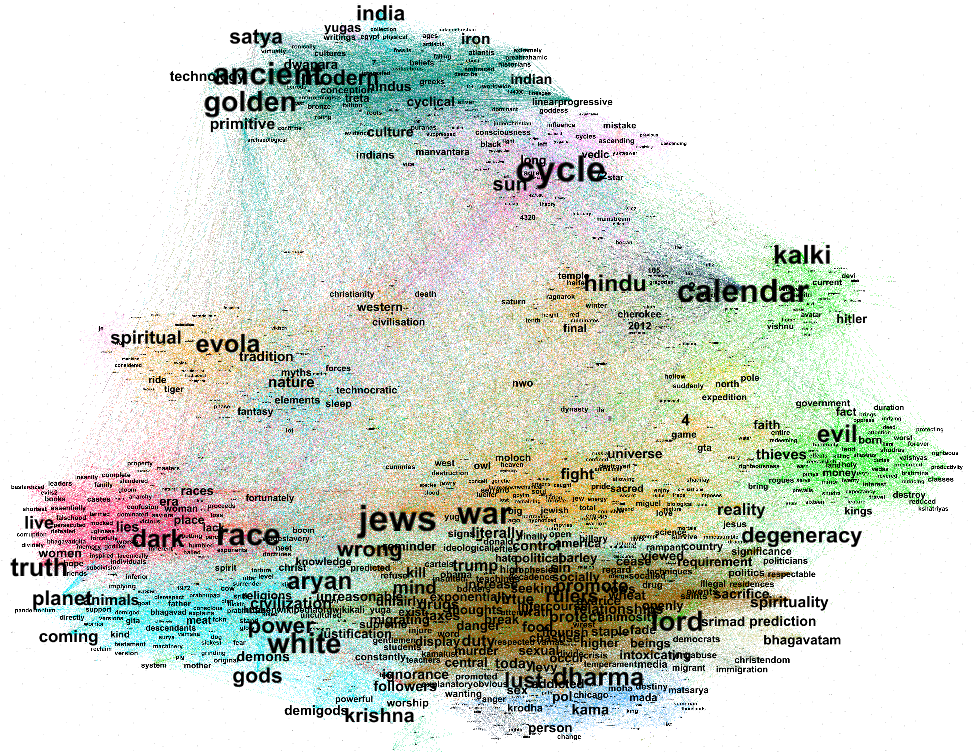
Artificial Intelligence, Game Studies, Television & Public Media Cultures, Surveillance & Data Governance, Big Data, Mobile Media & Digital Music, Mobile & Locative Media, Chinese Media Studies, News Personalization & Algorithms, Social Media Protest, Digital Aesthetics & Media Forms, Performance & Identity, Internet History, Gender, Queerness & Digital Labor, Open Source Movement, Digital Divides, Data Privacy , Media Power & Political Communication, Influencer Studies, Meme Studies, Internet Governance & Political Control, Civic Participation & Online Politics, Digital Archives, Civic Participation & Online Politics, Platform Politics & Power, Information Operations, Performing the Self: Identity, Interaction, and Expression on Social Media, Digital Memory & Commemoration, Digital Youth & Civic Engagement, Evolving News Habits and Media Trust, Feminist Technoscience Studies, Digital Learning & Higher Education, Peer Production & Online Knowledge, Misinformation & Fact-Checking, Platform Governance, Cultural & Media Theory, Information Operations, Arab Spring, Advertising, Dating, Digital Archives, Security & Conflict, Content Moderation Politics, Authoritarian Populism, Global Media Orders, Digital Ids, Born Digital, New/Digital Media, Conditions Of Possibility, Virtual Reality, Technological Determinism, Mainstreaming Of Porn, Public Interest Technology, Communication, Biometrics & Facial Recognition, Behavioral Tracking, Data Curation, Mainstreaming Of Porn, Hate Speech, Data Curation, Toxic Technoculture, Digital Pandemic Studies, Design & Interaction, Interface Anxiety, Digital Feminism
These topics often reflected areas of concentrated publication activity, regional or national research priorities, and the institutionalization of specific subfields. They were more descriptive than conceptual, often clustered after recognizably academic research programs or methodological foci.

For our analysis, we used an interactive Plotly graph generated by BERTopic. This allowed us to manually compare and investigate different topics and their trends over time, as well as see how keywords evolved over each year. We

To support in developing the stories, we manually investigated some of the titles and abstracts of articles using spreadsheets with the publications of each topic over the years. This enabled grounding our analysis and identifying some inconsistencies.
5.3 Some stories surfaced from the topics
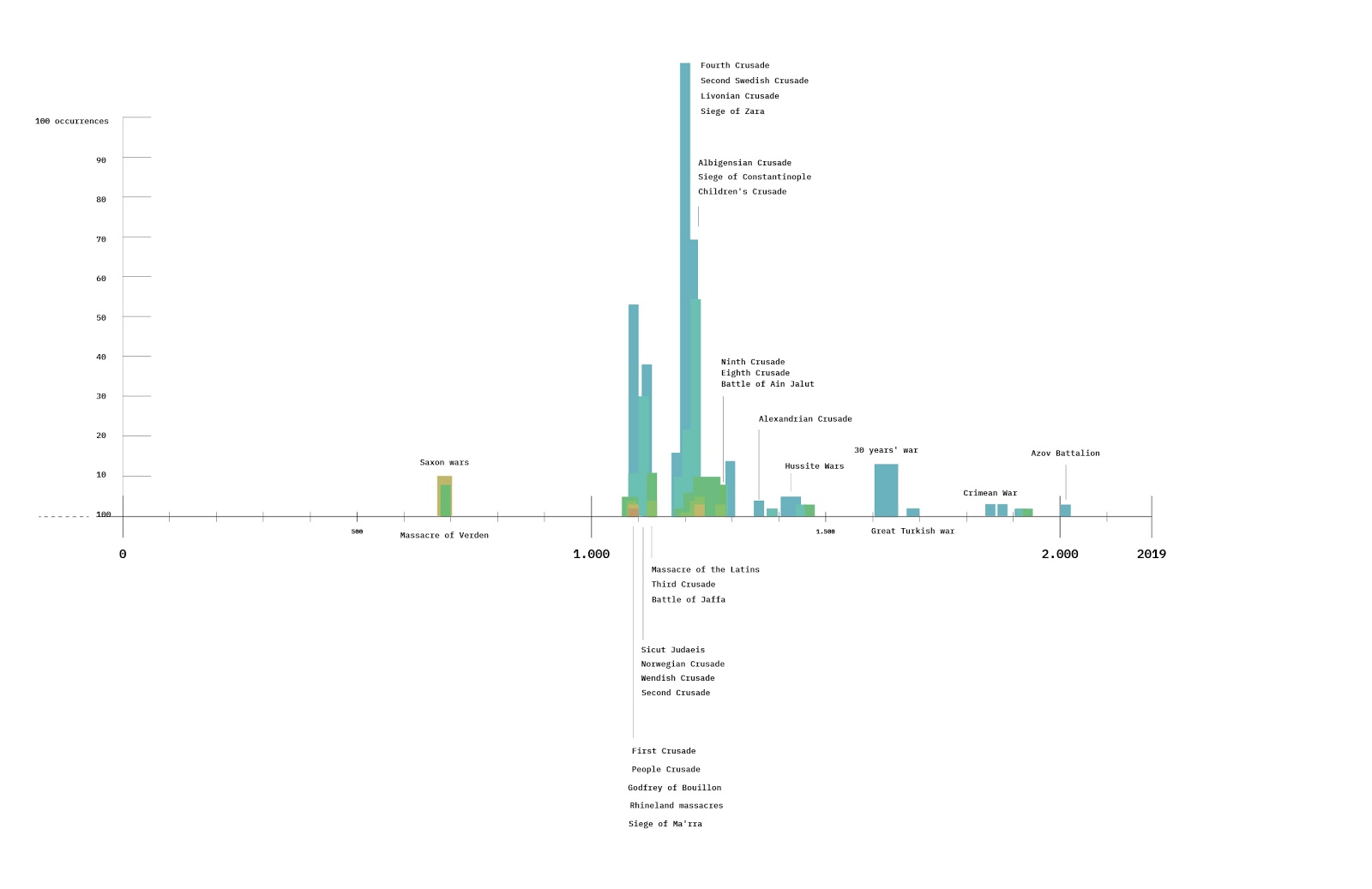
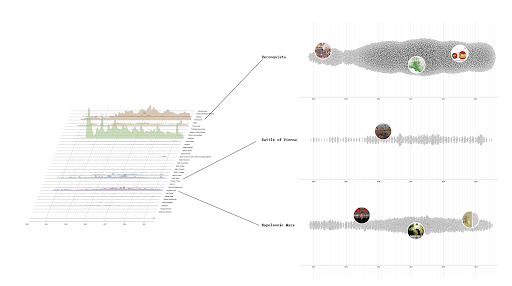
Artificial Intelligence
Topic 0
Artificial Intelligence emerged in early discourse as a speculative and philosophical concern, tied to questions of agency, ethics, and the “conditions of possibility” for artificial life. Interest remained modest until a marked resurgence around 2020. From 2021 onward, article volume surged—peaking dramatically in 2024—reflecting AI’s mainstreaming and intensified critical scrutiny. The focus shifted from foundational questions to urgent debates around power, regulation, accountability, and machine autonomy. This arc marks AI’s journey from fringe theory to infrastructural reality, prompting renewed ethical, political, and design-oriented inquiry across the media and communication field.
Open-Source and Digital Commons
Topics 16, 44
Between 2010 and 2015, research on open-source software and digital libraries imagined the Internet as a cultural and technological commons. Scholars emphasized free software, collaborative development, public access, and the preservation of archival memory. By the late 2010s, these topics declined. Did openness, decentralization, and participation, once central to the digital future, become a background infrastructure or residual imagery in a platform-dominated present? This shift in scholarly attention may reflect a deeper reorientation in digital culture itself.
Platforms, Social Media, and the Rise of TikTok
Topics 11, 27, 29, 38
As openness declined, platforms emerged as engines of visibility, optimization, and control. Early research on social media, e.g. related to Facebook (11) and Twitter (29), focused on personal networks and public discourse. By the mid-2010s, scholars turned to platforms as governance systems (Topic 27). TikTok ’s rise (Topic 38) marked a shift toward short-form video, performance-based visibility, and affective labour. Across these trajectories, we see a temporal and conceptual shift: from relational connection to platforms and from networks of people to streams of content. Being online increasingly means being seen, curated, and calculated.
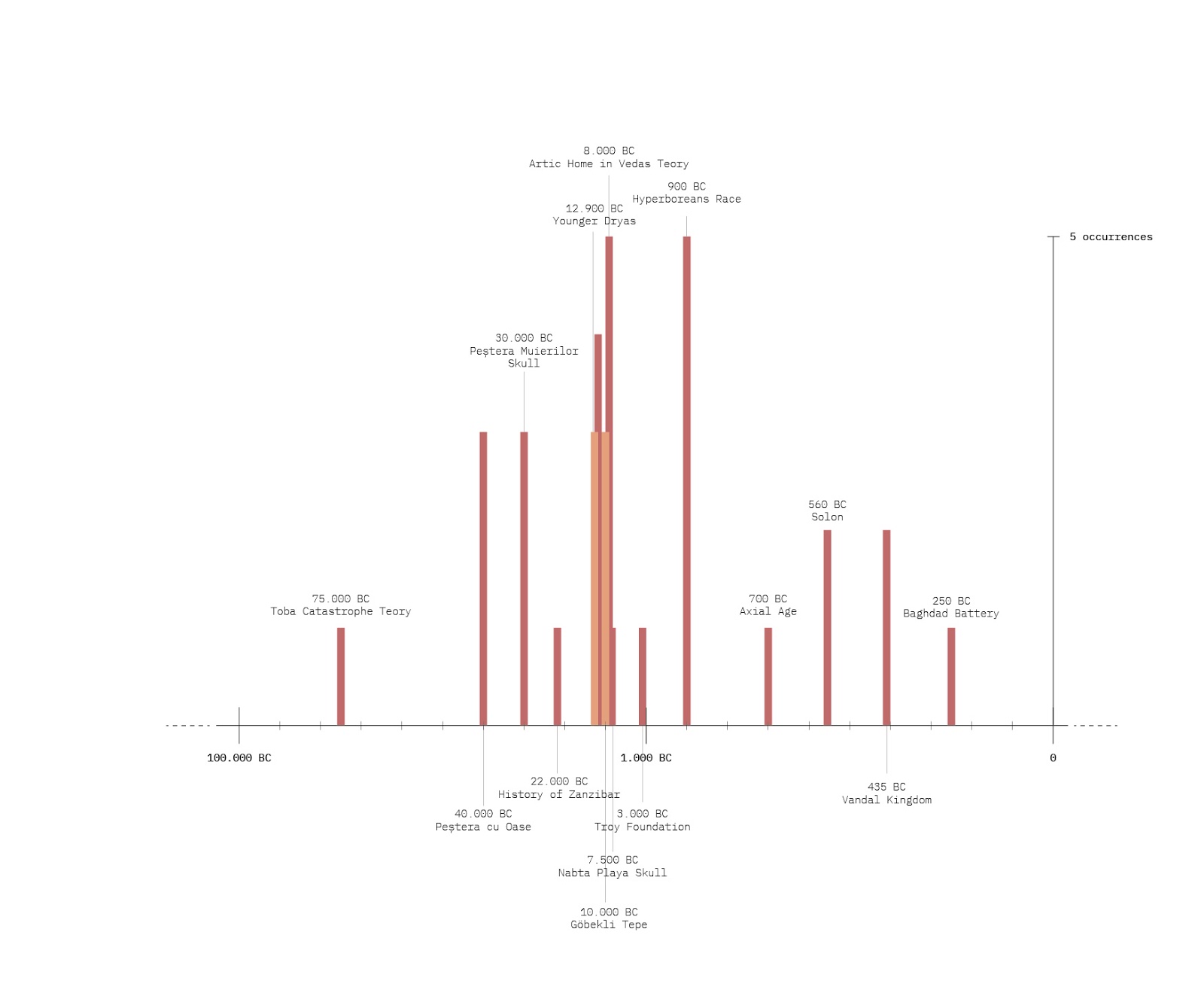
Surveillance and Privacy
Topics 3, 60
In the early aughts, a lot of the debate on Surveillance & Privacy focused on CCTV. In 2014 and 2015, the discussion began to focus on big data, Snowden's revelations, and other issues around digital data. In more recent years, Biometrics & Facial Recognition discussions emerged, signalling the rise of new forms of control through technological systems. The journal Surveillance & Society plays a key part in the debates of this topic. This also explains the blip in the year 2002: at first, we thought this could be due to the post 9/11 debates on surveillance; however upon a closer look, it seems the metadata wrongly dates articles published before 2004 as if they were all on Sep 1, 2002.
Conspiracy, Misinformation, and COVID-19
Topics 37, 28, 70, 65
Beginning in mid-2015, there was a notable rise in articles discussing bot activity and fake news on social media, especially Facebook and Twitter. This marked a shift from viewing the internet as a space of truth to recognizing its limitations and the importance of digital literacy. Between 2016–2020, articles increasingly addressed misinformation, often tied to health and vaccine concerns. The COVID-19 pandemic accelerated this trend, with a surge in discussions around conspiracy theories and disinformation spread by bots or rhetorical actors. Terms like “infodemic,” “conspiracy theory,” and “fake news” became central in New Media Studies through to 2024.
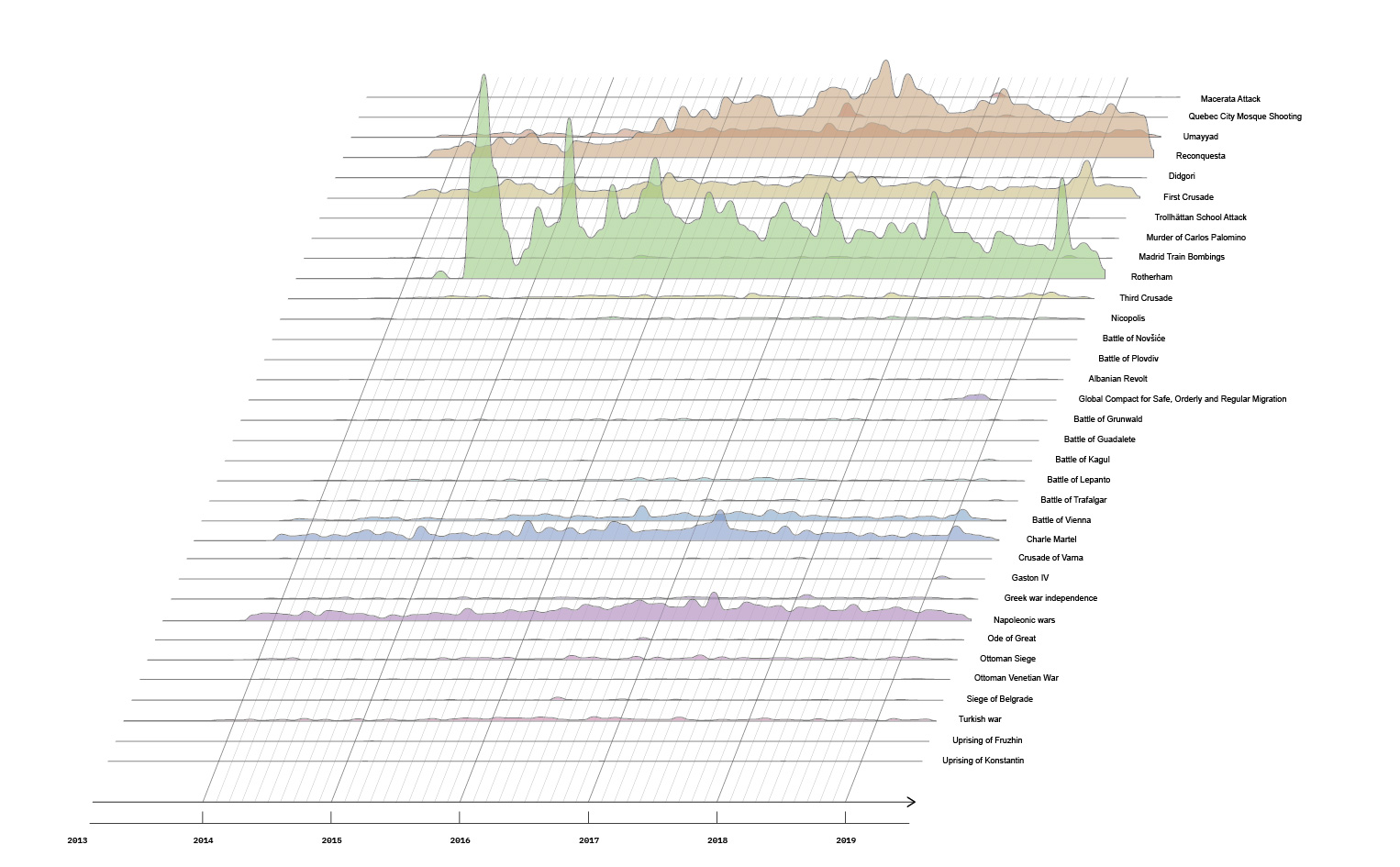
Non-Western New Media
Topics 41, 7, 39
Over the past 25 years, New Media Studies has increasingly turned its attention to non-Western contexts, with a growing body of scholarship examining developments in China, Korea, the Arab world, and other regions. A recurring theme throughout this work is the ongoing negotiation between public participation and state control. In China, media studies have evolved alongside the nation’s emergence as a global power, shifting from an early focus on BBS forums and censorship to more recent explorations of digital nationalism. In the Arab world, research has centered on satellite networks and the formation of contested publics. Korean media scholarship has charted the rise of soft power through fandom and the global spread of K-pop.
Data Tracking and Digital Connection
Topics 43, 61
The trends of self-tracking and dating apps reveal how intimacy has increasingly become a core part of digital platforms, as they merge personal data with social connection. Even before 2020, location tracking and algorithmic recommendations became central to how apps operate, shaping how people connect and navigate online spaces. Self-tracking technologies, from health apps to geolocation, quietly reshaped daily life and social interactions. The spike around 2020 reflects how the pandemic accelerated these dynamics: governments normalized large-scale data tracking and lockdowns confined social interaction to digital platforms. Together, these trends show how personal data and online connections have become inseparable in everyday life.

See also our poster for the visualization.
6. Discussion
Our hybrid methodology—pairing expert-coded deductive categories with inductively derived topic models—offered a powerful way to surface the evolving vocabularies of New Media Studies. This approach moved beyond static, canon-based typologies and opened up space for:
6.1. The inclusion of emergent “vibe” oriented meanings of scholarship.
This hybrid infrastructure does not only track trends—it invites scholars to reimagine how field boundaries are constructed, debated, and rearticulated. It allowed us to move beyond static, edited collections toward a dynamic, inductively generated vocabulary for New Media Studies. Our method offered: 1) Greater inclusion of emergent and culturally inflected terms (e.g., “throbber,” “toxic technoculture”); and 2) A field-specific vocabulary useful for further semantic modeling
The comparison between the deductive (baseline) and inductive (vector embedding) mappings revealed several important patterns:
-
Thematic Divergence: The deductive taxonomy emphasized critical theory, media aesthetics, and conceptual abstraction, whereas the inductive model surfaced empirical research clusters, often grounded in social science methodologies or policy relevance.
-
Lexical Variation: Deductive keywords leaned toward neologisms and poetic or politicized language (e.g., data hauntology, glitch feminism), while inductive topics were more formal or field-label-like (e.g., “platform governance,” “online youth engagement”).
-
Coverage Gaps: Concepts like reparative media, opacity politics, machinic enunciation, and queer temporality were richly represented in the deductive taxonomy but did not appear as distinct inductive clusters—likely due to their lower frequency, semantic dispersion, or non-standard terminology in academic abstracts.
-
Conversely, inductively salient clusters such as Chinese internet studies, digital public health, and influencer marketing were underrepresented in the deductive mapping, highlighting areas where research production has outpaced conceptual consolidation.
-
Levels of Abstraction: The deductive approach offered a meta-theoretical lens on the field, suitable for constructing a handbook or reader. The inductive mapping provided a bottom-up view of where institutional energy is currently focused, useful for understanding disciplinary momentum and identifying emergent specializations.
6.2. Reflexive insights into the assumptions embedded in both handbooks and machine learning tools.
This study made us aware of how both canonical handbooks and machine learning models carry implicit assumptions about what constitutes knowledge, relevance, and structure. Handbooks typically assume a top-down, curatorial authority, highlighting certain concepts as foundational while marginalising others. These editorial decisions are shaped by disciplinary traditions, institutional hierarchies, and geopolitical-linguistic constraints on what gets named, circulated, and legitimised.
In contrast, machine learning tools tend to prioritize semantic coherence, statistical significance, and linguistic dispersion. However, this supposed objectivity encodes biases through training corpora, vector representations, and optimization goals. Our approach aimed to surface these epistemological asymmetries, encouraging scholars to question what is excluded, flattened, or overemphasized in both human- and machine-curated knowledge systems.
6.3. A testbed for non-commercial LLM-assisted knowledge mapping, tailored to scholarly domains.
The project illuminated how we may critically engage with alternative methods to both commercial LLMs and top-down scholarly canons. It offered a sandbox for experimenting with non-commercial, reflexive models that foreground scholarly priorities while also surfacing how algorithmic assumptions shape the very contours of legibility and relevance.
There are several points of departure that could be developed further—such as applying the model to systematic or scoping literature reviews. There could be several different entry points into such an analysis, e.g. dynamic topic modelling (timeline), topological graphs, temporal clustering and more. Moreover, the results should also inspire other ways of finding and browsing scholarly work, aligned with academic priorities rather than those of Big Tech companies—see e.g. the VibeSearch tool that inspired this project.
Finally, this project was performed on an English language corpora, which must therefore be accounted for when analysing the conceptualization of the field. This introduces cultural and epistemological limitations. Further testing using different linguistic and regional datasets should be part of the next step of analysing the models variability and addressing potential cultural or epistemological blind spots.
7. Conclusion: Abductive Infrastructures for Reflexive Fields
The taxonomy and topic model presented here establish a semantic infrastructure —for example, a structured vocabulary and latent topic map— that is, for subsequent phases of this project. Together, they enable vector-based inductive mapping and methodological experimentation with small LLMs in the humanities.
More than a static map, the hybrid model functions as a generative epistemic interface. The deductive taxonomy offers conceptual depth, while the inductive model foregrounds patterns of scholarly activity. Their combination supports what Piece called “abduction”—a mode of reasoning that begins not with proof, but with plausible inference, speculation, and hypothesis generation. Abduction is particularly suited to exploratory research, where patterns must be discerned in messy or emergent terrain.
By designing tools that facilitate abductive engagement with the field, this project reframes LLMs not as black-box summarizers, but as catalysts for collective sensemaking. This approach empowers scholarly communities to define their own epistemic terrain—not only descriptively, but reflexively and propositionally, shaping the very categories and methods through which knowledge is organized, contested, and renewed.
The hybrid model thus serves as both mirror and probe: reflecting the field’s evolving contours while also enabling new ways of navigating, inhabiting, and reimagining them. It affirms the value of experimental infrastructures that are attuned to scholarly values, semantically grounded in disciplinary practice, and open to iterative co-construction—rather than extractive or externally imposed.
Looking ahead, this abductive infrastructure may serve not only as a diagnostic map of an existing field but also as a kind of exploratory means for shaping new research agendas. By enabling field-specific vocabularies to emerge from within the community rather than from external platforms or editorial gatekeeping, this approach suggests a new kind of model, beyond bibliometrics. Future work could integrate multilingual corpora, explore more dynamic interfaces (e.g. knowledge graphs or exploratory dashboards), and apply similar methods to other interdisciplinary domains where conceptual boundaries are in flux. In this sense, vibe mapping is not just a method, but a proposal for how we might attune scholarly tools to the epistemic rhythms of reflexive fields.
8. References
Callon, M., Courtial, J.-P., & Laville, F. (1991). Co-word analysis as a tool for describing the network of interactions between basic and technological research. Andersen, C. U., & Cox, G. (2023). Toward a Minor Tech. Munk, A. K., et al. (2024). What Are Algorithms Doing in the Scientific Literature? Suzina, Ana Cristina. 2021. “English as Lingua Franca. Or the Sterilisation of Scientific Work.” Media, Culture & Society 43 (1): 171–79. https://doi.org/10.1177/0163443720957906.
9. Attachments
To explore how different hyperparameters affect topic modeling results, we conducted five tests using the same dataset from 2018. The first test served as a baseline with default parameter settings. In each of the following four tests, we adjusted one key parameter at a time to observe its specific impact on the output. These parameters include n_neighbors, n_components, min_cluster_size and top_n_words, which control the clustering structure, topic representation, and dimensionality reduction within the BERTopic model. This step-by-step approach allowed for a controlled comparison of how individual settings influence the number and structure of detected topics.Model exploration
Baseline TestDataset: Year 2018
Hyperparameters:
n_neighbors=20
n_components=5
min_cluster_size=10
top_n_words=11
Output:
32 topics


Test 1 — Lowering n_neighbors to 5
In this test, I reduced the n_neighbors parameter from 20 to 5 while keeping all other settings constant. As expected, a smaller neighborhood size in the UMAP model led to more fragmented clusters. The number of detected topics increased from 32 to 43, and the Intertopic Distance Map shows a larger overall spread with less overlap between clusters. This indicates that the model now captures more fine-grained differences between documents, but possibly at the expense of producing very small or highly specific topics. Visually, the document-topic map also shows more dispersed clusters with sharper boundaries compared to the baseline.
Dataset: Year 2018
Hyperparameters:
n_neighbors=5
n_components=5
min_cluster_size=10
top_n_words=11
Output:
43 topics


In this test, I reduced the n_components parameter from 5 to 2 to observe how lowering the dimensionality of the UMAP projection affects clustering and topic formation. The number of detected topics increased from 32 to 37, suggesting that more distinct clusters emerged. Visually, the Intertopic Distance Map shows more dispersed topic bubbles, indicating a greater separation between clusters. However, lowering the dimensionality may also exaggerate certain distances or overlaps, as some structural information is inevitably lost. The document-topic map reveals that while clusters are more visually separable, the overall distribution appears slightly noisier compared to the baseline.
Dataset: Year 2018
Hyperparameters:
n_neighbors=20
n_components=2
min_cluster_size=10
top_n_words=11
Output:
37 topics


Test 3 — Increasing min_cluster_size to 12
In this test, I increased the min_cluster_size parameter from 10 to 12 to examine the effect of stricter clustering requirements. As expected, the total number of detected topics dropped significantly from 32 to 22. The Intertopic Distance Map shows fewer, but generally larger topic bubbles, with clearer separation between clusters. The document-topic map also reflects this, with fewer scattered points and more consolidated topic groups. This suggests that a higher min_cluster_size reduces noise and small, overly specific topics, resulting in a cleaner but potentially less fine-grained topic structure.
Dataset: Year 2018
Hyperparameters:
n_neighbors=20
n_components=5
min_cluster_size=12
top_n_words=11
Output:
22 topics


In this final test, I increased the top_n_words parameter from 11 to 20 to explore how expanding the number of displayed keywords affects topic structure and interpretation. As expected, this parameter change does not influence the clustering process itself, as the total number of detected topics remained similar at 33. However, the additional keywords provide more detailed topic labels, offering richer context for interpreting each cluster. Visually, both the Intertopic Distance Map and the document-topic map are consistent with previous tests, confirming that this setting mainly affects output readability rather than the underlying topic formation.
Dataset: Year 2018
Hyperparameters:
n_neighbors=20
n_components=5
min_cluster_size=10
top_n_words=20
Output:
32 topics




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback