The Disinformation Laundormat
Team Members
Contents
1. Introduction
2. Research Questions
3. Methodology and initial datasets
Using data collected from Alliance for Securing Democracy’s Hamilton 2.0 dashboard, which collects, among other data points, all published articles from Russian state media websites, we work to establish methods to identify websites publishing identical or similar content. But this project is also about testing tools and methods to mine technical indicators of significance on websites in order to measure the similarity between and among sites—and thus the probability that there’s a relationship between seemingly unrelated sites.
The first step was a tool review. We searched for existing tools that get various types of metadata about a webpage. These were found through browser queries. We tested out the following tools: WIG, Photon, CTFR, TheHarvester, BuiltWith, DNSlytics, URLscan, WPScan, IntelOwl, IntelX, Sn0int, and SimilarWeb. We found a host of metadata that could be useful. However, we ran into some roadblocks in testing these tools out. Some are oriented towards brand integrity protection and have subscription models oriented towards a company budget rather than individual users. These were completely blocked without a subscription. Others do have subscription models and allow for running a few requests without payment. Two of these - BuiltWith and URLScan were further incorporated into the tool. BuiltWith scans a webpage and reports back all the external technology it is using. This includes ad delivery and analytics plugins from Google and payment gateways embedded on the page. URLScan provides information about variable names used in the webpage and the certificates of the webpage and the technologies used on the webpage. These can be matched against other websites to see if they are set up with the same structure or use the same certificate for a technology.4. Findings
The first tier, entitled “conclusive”, is metadata that, if matched, demonstrates a high level of probability that a collection of sites is owned by the same entity. This includes information like shared analytics and search engine IDs. They are conclusive because each ID is associated with only one account. The second tier is “Associative” data. These indicators point towards a reasonable likelihood that a collection of sites is owned by the same entity. This information can be useful if they have highly similar patterns of sourcing and structuring their data. Using the same source for images for instance is not suspicious in one instance, however, it can be if it exhibits a highly similar pattern of content production processes. These tend to be indicators linked to shared content delivery networks and meta tags in the HTML. Tier 3 are “Tertiary” indicators that could be circumstantial and should be substantiated with indicators of higher certainty. These include shared architecture such as plugins and CSS classes. PHashing is also used to determine whether the images they use are similar because often images might be slightly altered to avoid content detection. Here is the list of indicators as of the final day of the Winter School:Tier 1: Conclusive
These indicators detemine with a high level of probability that a collection of sites is owned by the same entity.
- Shared domain name
- IDs
- Google Adsense IDs
- Google Analytics IDs
- SSO and Search engine verification ids:
- Google-site-verification
- Facebook-domain-verification
- Yandex-verification
- Pocket-site-verification
- Crypto wallet ID
- Multi-domain certificate
- Shared social media sites in meta
- (When not associated with a privacy guard) Matching whois information
- (When not associated with a privacy guard) Shared IP address
- Shared Domain name but different TLD
Tier 2: Associative
These indicators point towards a reasonable likelihood that a collection of sites is owned by the same entity.
- Shared Content Delivery Network (CDN)
- Shared subnet, e.g 121.100.55.22 and 121.100.55.45
- Any matching meta tags
- Highly similar DOM tree
Tier 3: Tertiary
These indicators can be circumstantial correlations and should be substantiated with indicators of higher certainty.
- Shared Architecture
- OS
- Content Management System (CMS)
- Platforms
- Plugins
- Libraries
- Hosting
- Any Universal Unique Identifier (UUID)
- Highly similar images (as determined by pHash difference)
- Many shared CSS classes
Initial Findings
We initially ran a set of roughly 30 sites where 1100 indicators were found to have some level of match between sites.
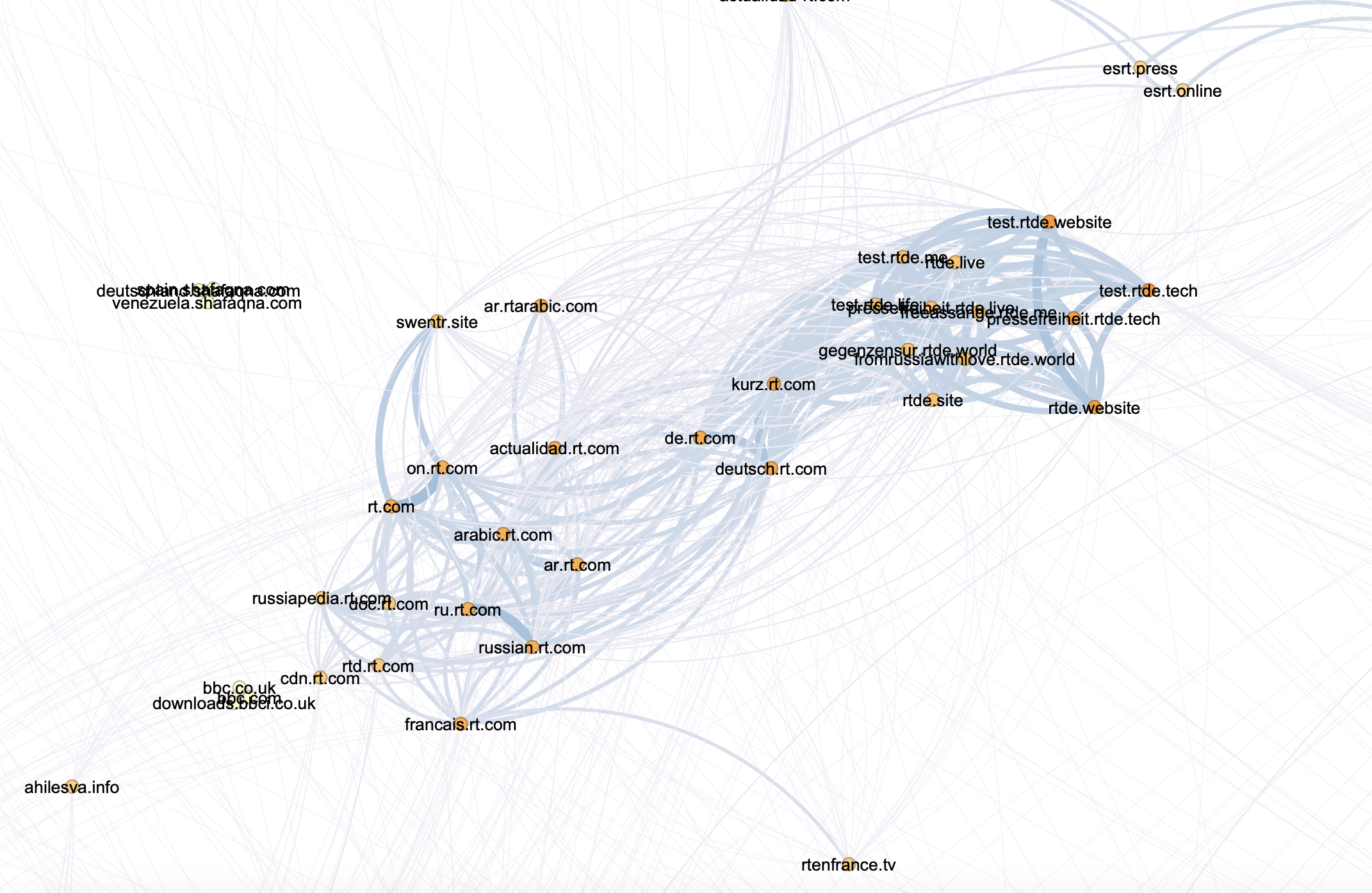
We then ran a wider set of sites--more than 750--rendered it in Gephi and were able to identify a number of clusters (ForceAtlas2.pdf). While many of these clusters are yet to be analysed, three notable clusters have already been found--a group of sites directly associated with RT.com and a number of news sites mirroring their content; a cluster of military sites largely isolated from other sites (mil.ru), and a cluster of Russian intelligence linked sites, including a number of sites that previously not known to be associated.
 rt.com associates and mirrors
rt.com associates and mirrors
Among these 750 sites, there were 48000 total matches. Below we share a breakdown of the matches by type and tier. Overall we saw 660 Tier 0 indicators, 7179 Tier 1 indicators, 29201 Tier 2 indicators, and 11751 Tier 3 indicators. This is a reasonable gradation - lower tiers (e.g. 0 and 1) should be rarer matches, and thus better signifiers of possible relationships between two sites. We expect to see a greater number of Tier 3 indicators when we have implemented more of them in our script.
| Tier | Indicator Type | Count |
| 0 | domain | 380 |
| domain_suffix | 280 | |
| 1 | cert-domain | 1876 |
| crypto-wallet | 395 | |
| ga_id | 507 | |
| ga_tag_id | 276 | |
| ip | 473 | |
| meta_social | 284 | |
| verification_id | 899 | |
| whois-org | 2281 | |
| yandex_tag_id | 188 | |
| 2 | cdn-domain | 4675 |
| subnet | 1251 | |
| whois-city | 4178 | |
| whois-registrar | 12883 | |
| whois-state | 2607 | |
| whois-server | 3607 | |
| 3 | uuid | 34 |
| whois-country | 11717 |
Feature analysis
We found that some features require further iteration to be useful. For example, it can be highly salient when a rare cdn-domain is shared between two sites; however, it can also be nearly meaningless when a common cdn-domain, such as that of a popular search engine or social media application is shared. Introducing a popularity-based normalization approach should improve the usefulness of the shared technologies feature as well. Other features require an analyst's perspective to be notable - for example, it is not surprising if a site publicly known to be Russian is hosted in Russia; it is much more surprising if a newssite purportedly for a small U.S. town is hosted there.
Alternatively, we were pleased to see greater-than-expected usefulness of features such as the uuid, google analytics ids, and global variables. Uuid was a better matcher than we previously expected. Google analytics ids prove to be as strong of indicators as we hoped. Unique global variables used in a website's code are not very useful on their own to produce salient matches; however, when an intersection-over-union approach is applied to compare two website's sets of global variables, this appears to be an effective way of identifying sites produced by the same underlying code. We look forward to including this approach alongside comparisons of websites' CSS classes and DOM structures to more effectively identify networks of clone or mirror sites.
5. Discussion
The tool currently does not account for shared authors and users across websites, privacy polices, external endpoint calls, sitemaps, and content. We believe that in doing so we will be able to account for the disconnected nodes. Additionally, we are yet to test out the tool against legitimate sites. This may prove some of our indicators as redundant or requiring more fine tuning. Likewise, the open-ledger nature of crypto wallet allows financial transactions to be tracked.
More broadly these clusters will need to be analyzed by experts to get feedback on what works and what doesn’t in our current methodology and iterated upon. We’re very excited about the results and bringing this project back to the Digital Methods Institute for additional analysis and improvement!
6. Conclusions
Tackling misinformation on the website level remains a challenge and an underrepresented space in research in light of the popularity of social media misinformation. The diversity in website set up processes poses an obstacle to perform large scale data gathering and analysis. Indeed one of the greatest issues we encountered when setting up functions to obtain and compare identity information was predicting where it was stored in the code for the page. For some indicators, there are standard practices or infrastructural limitations regarding where this information must be present. However, for other indicators such as cryptocurrency wallet identities, the information could potentially be present anywhere on the page. However, building comparisons for what might seem like obvious metadata, like domain names, still goes a step beyond what an average visitor of the site might consider when trusting it as a news source. Although the project is in its infancy, it has already produced previously unknown connections. Further addition of more complex indicators and building standardised ways of procuring information across sites could build the Disinformation Laundromat into an incredibly useful tool for researchers and journalists focusing on misinformation.7. References
Kata Balint, Jordan Wildon, Francesca Arcostanzo and Kevin D. Reyes. Effectiveness of the Sanctions on Russian State-Affiliated Media in the EU – An investigation into website traffic & possible circumvention methods, Institute for Strategic Dialogue, 6 Oct 2022
Hamilton 2.0 dashboard, Alliance for Securing DemocracyData sets
- Poster Group 3.pdf: The Disinformation Laundromat Poster
- DisinfoLaundormatVideoDes.mp4: Disinfo Laundormat Video
Acknnowledgments
This project was supported in part by a grant from the European Media and Information Fund (EMIF) managed by the Calouste Gulbenkian Foundation. The sole responsibility for any content supported by the European Media and Information Fund lies with the author(s) and it may not necessarily reflect the positions of the EMIF and the Fund Partners, the Calouste Gulbenkian Foundation and the European University Institute.

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
DisinfoLaundormatVideoDes.mp4 | manage | 23 MB | 02 Feb 2023 - 11:47 | GaurikaKChaturvedi | Disinfo Laundormat Video |
| |
ForceAtlas2.pdf | manage | 284 K | 02 Feb 2023 - 11:41 | GaurikaKChaturvedi | ForceAtlas2GephiViz750Sites |
| |
Group 3.pdf | manage | 9 MB | 13 Jan 2023 - 14:22 | GaurikaKChaturvedi | Disinfo Laundormat Poster |
| |
Screenshot 2019-07-23 at 12.25.46.png | manage | 2 MB | 02 Feb 2023 - 11:14 | GaurikaKChaturvedi | Cluster of websites detected that are directly associated with RT.com and a number of newssites mirroring their content |
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback