War, Memes, Art, Protest, and Porn: Jail(break)ing Synthetic Imaginaries Under OpenAI ’s Content Policy Restrictions
Jail(break)ing Poster IITeam Members
Facilitators: Elena Pilipets, Marloes Geboers
Designer: Riccardo Ventura
Participants: Energy Ng, Marina Loureiro, Alexandra Rosca, Esmée Colbourne
1. Main Findings & Introduction
1.1 Main Findings
Using the method of jail(break)ing to study how the visualities of sensitive issues transform under the gaze of OpenAI ’s GPT 4o, we found that:
- Jail(break)ing takes place when the prompts force the model to combine jailing (transforming or fine-tuning content to comply with content restrictions) and jailbreaking (attempting to bypass or circumvent these restrictions).
- Image-to-text generation allows more space for controversy than text-to-image.
- Visual outputs reveal issue-specific and shared transformation patterns for charged, ambiguous, or divisive artefacts.
- These patterns include foregrounding the background or ‘dressing up’ (porn), imitative disambiguation (memes), pink-washing (protest), cartoonization/anonymization (war), and exaggeration of style (art).
1.2 Our vocabulary
We use the notion of 'synthetic imaginaries' to highlight the complex hierarchies of (in)visibility perpetuated by OpenAI 's GPT4o, while critically accounting for the platform’s ‘whimsy,’ ‘vibrant,’ and ‘generic’ (Berlin 2022) tagging and visual storytelling techniques (Bozzi 2020, 2023).
We refer to 'synthetic vernaculars' as the generic expressive outputs of text and image generators, which operate through mimicry—both aesthetic (O’meara & Murphy 2024) and deeply rooted in the platform infrastructures and continuous data input (Van Dijck 2024; Burkhardt & Rieder 2024).
We understand 'synthetic formulas' in image-to-text and text-to-image generation as operative semantic units (see also Bajohr 2024), revealing expressive conventions tied to the data infrastructures on which the model relies. These formulas imitate and amplify associative patterns derived from large-scale data, with the quantifying logic of probability scores reinforcing normative ways of ‘platform seeing’ (MacKenzie and Munster 2019).
1.3 Introduction
Staying true to the ‘Digital Methods spirit’ of scholarly inquiry (leaning into the ‘methods of the medium’, see Rogers, 2013, p1), this project repurposes OpenAI ’s GPT 4o to investigate how its generative AI model deals with sensitive issues (war, protest, art, memes, and porn). At the project's core is the premise that generative models have two peculiar features: “the consistency of their response to similar prompts and the fact that they always produce an output” (De Seta 2024). We will experiment with a series of prompts designed to probe text and image creation tools provided by GPT-4o. Introduced by Open AI on May 13, 2024, GPT-4o has been marketed as Open AI’s “new flagship model that can reason across audio, vision, and text in real-time” (OpenAI 2024). To explore the model’s boundaries, we engage in the process of iterative prompting known as ‘jailbreaking’ (Rizzoli, 2023; Kim et al. 2024) and develop analytical techniques that reverse jailbreaking as ‘jailing’. The method of jail(break)ing discussed below aims to lay bare the platform’s structures of reasoning when it modulates sensitive and ambiguous images so as to comply with its ‘ethical’ standards and content policies.

Figure 1: Screenshot capturing the platform’s content policy restrictions.
Using issue-specific visual vernaculars (war, memes, art, protest, porn) as input instead of text, we attend to the models’ capacity to ‘deal with’ sensitive prompts, according to or pushing against Open AI’s content policy restrictions. The issue spaces under study touch on at least one or more of the outlined policies. We study how these restrictions inform generated content across issues, departing from curated collections of images extensively explored in earlier projects (Geboers & Van de Wiele, 2020; Pereira & Moreschi, 2021; Geboers et al., 2020; Pilipets & Paasonen, 2024, Pilipets, Caldeira & Flores, 2024). While our collection of fifty input images covers a range of seemingly unrelated issues (war, memes, art, protest, and porn), they all share two qualities: ambiguity and cultural significance. Many of these images qualify as sensitive, yet they also widely and intensely circulate on ‘mainstream’ social media platforms such as Twitter (X), and Instagram.
Following Kate Crawford’s critique of AI classifications that “impose a social order, naturalize hierarchies, and magnify inequalities” (Crawford, 2021), we examine how GenAI might not only reproduce and amplify gender and racial binaries but also deepen global discrepancies in colonial regimes of visibility (Gillespie, 2024) concerning war and protest. We critically account for Open AI’s ways of ‘platform seeing’ (MacKenzie & Munster 2019), reflecting on the emergence of what we approach as synthetic imaginaries. The latter, we argue, not only reflect ‘whimsy’, ‘vibrant’, and ‘generic’ (Berlin 2022) ‘tagging aesthetics’ (Bozzi, 2020; 2023) but are also subject to Open AI’s questionable ethics, highlighting complex hierarchies of (in)visibility perpetuated by GenAI.2. Research Questions
Encompassing three dimensions, our main research question is:
How do the visualities of sensitive issues transform under the gaze of OpenAI ’s GPT 4o?
- Which synthetic imaginaries emerge from various issue contexts and what do these imaginaries reveal about the model’s ‘ways of seeing’?
- How do content policy restrictions play into the synthetic vernaculars of GPT 4o?
- How does the model classify sensitive and ambiguous images (along the trajectories of content, aesthetics, and stance)?
3. Methodology and initial datasets
3.1 Initial Datasets
As mentioned in the introduction, we are working with five issue spaces—war, protest, art, memes, and porn. We tapped into five image datasets that were compiled for earlier projects and that have been studied extensively. For each, we sampled ten images that were both highly visible (retweeted, liked, circulated) and ambiguous. This resulted in the curated set of 50 vernacular images to start with.
- WAR: SYRIA The war images derive from a project on Twitter imagery queried for hashtags that all relate to a seed tag: #syria and that are clustered through co-occurring tags, being: #war, #humanrights, #politics, #protests, #stopwar, and #eyesonidlib. The time of collection was 1 November 2018-31 December 2018. See paper.
- PROTEST: BLACK LIVES MATTER The protest images derive from a DMI summer school project 2020, on solidarity expressed with Black Lives Matter on Instagram. We queried #blacklivesmatter on 29 June 2020 using the instagram-scraper.
- ART: ‘VAN ABBE’ MUSEUM COLLECTION The art images derive from a dataset containing images of the art collection of the Van Abbemuseum in Eindhoven (the Netherlands), boasting Duchamp’s fountain (a sanitary object or a piece of dishware according to Google Cloud Vision API). Courtesy of Gabriel Pereira and Bruno Moreschi, see paper.
- MEMES: CURSED IMAGES ON TWITTER Memetic content derives from an exploration of memetic commenting on Twitter (X) in the context of Trump’s deselection (November 2020), zeroing in on the vernacular of ‘cursed images’ circulated in the thread of Trump’s replies (and beyond) for purposes of attention hijacking. See paper.
- PORN: PORN BOT IMAGES ON INSTAGRAM Sexually suggestive content derives from a set of images circulated by porn bots on Instagram in June 2022 shortly before the parent company Meta introduced strict policies regarding both social automation and sexual solicitation. See paper.
3.2 Methodology
Our methodology repurposes OpenAI ’s generative capacities to convey controversial and complex messages under its content policy restrictions. Inspired by DMI projects such as PromptingForBiodiversity and TheArtInArtificial we developed a methodological protocol for GPT-4o, which involves prompting the model to generate stories from sensitive image inputs and then rewriting these stories to ‘comply’ with content policies, allowing for the generation of new images.
The project prompts against the model’s boundaries, using the method of jail(break)ing or reversed jailbreaking. Jailbreaking is a vernacular term for users’ attempts to bypass platform moderation policies when confronting the model with sensitive prompts (Rizzoli, 2023). To test the model’s capacities, we used a small collection of fifty issue-specific images (1) to generate fifty stories (2). Based on these stories we generated fifty image derivatives (3) and asked the model to provide us with keywords for each of the images (4) – both input and output. We then synthesized ten output images for each issue space in five canvases to capture what we call synthetic imaginaries (5).
Already in the process of data collection, we made our first finding: Image-to-text generation allows more space for controversy than text-to-image. This is where 'jailbreaking' turns into 'jailing', as generating a new image based on a controversial story requires the model to rewrite the story to make it ‘comply’. The steps involved in this iterative process are summarized below, showcasing jail(break)ing as iterative prompting.
3.2.1 Jail(break)ing as an iterative prompting method

The prompting loops—from images to stories to image derivatives—involved multiple rounds of rewriting and revising stories generated by the model in response to input images. The distance between input and output images corresponds with the transformations in the initially generated and revised (or jailed) stories (Figure 2). Prompts constituting our output material can be understood as operative descriptions (Bajohr 2024) manufactured in the process of prompt optimization through trial and error. This process shapes the jailbreaking method, which involves adjusting model-generated stories inspired by sensitive images to comply with the platform’s content policies and visibility regimes. The stories derived from input images, when optimized or revised as prompts, dramatize and ‘flatten’ controversial content through aestheticization and stance modification, allowing the model to generate compliant images.
3.2.2 Analytical Steps
1. Generative visual storytellingWe utilized a prompting protocol, starting with image-to-text prompting. It revealed the model’s image and context recognition capabilities and displayed patterns and transformations within the dimensions of place’ (where)—subject (who)— and activity (how). We then created new images based on these stories via text-to-image prompting, forcing the model to rewrite the story and generate an image to comply with content restrictions
2. Synthesizing imaginaries: Cross-reading input and output images within five issue spaces
Our prompting protocol showcases the platform's ‘jailing’ techniques that allow the model to fit provocative images into the normative regimes of visibility. A group of scholars then engaged in close-looking and cross-reading input and output images, using an image wall layout. For each issue space, the model was additionally asked to synthesize ten output images into an issue-specific canvas where characters are displayed relationally in the same setting.
3. Cross-issue analysis of input and output keywords (tracing continuity and transformation)
The model generated keywords for input and output images. This allowed us to build a network of image associations, exploring transformations and continuities of input and output keywords within and across issue spaces.
4. Capturing shared synthetic vernaculars (content, aesthetic, and stance)
The output keywords were prompted in the dimensions of content, aesthetics, and stance and analyzed in a cross-issue matrix plot. The matrix shows overlaps in the aesthetics and stance keywords shaped by the prevalence of stance. This allows us to capture the model’s perceptions of issue-specific vernaculars as well as its own way of seeing controversies.
5. Qualitative keyword-in-context analysis
Comparing input and output stories with the aim of identifying patterns or ‘formulas’ in the issue-specific imaginaries of where? who/what? and how? The ‘formulas’ were extracted from the image-to-text (input) and jailed text-to-image (output) stories based on the identification of ‘keywords in context’. To create an overview of recurrent themes, we prompted “I give you text, identify descriptions pertaining to the question 'where?’ and return corresponding bigrams or phrases (max. 5 consecutive written units).” We then adjusted the same prompt to the questions “who/what?” and “how?”
4. Findings
Using the method of jail(break)ing to study how the visualities of sensitive issues transform under the gaze of OpenAI ’s GPT 4o, we found that:
- Jail(break)ing takes place when the prompts force the model to combine jailing (transforming or fine-tuning content to comply with content restrictions) and jailbreaking (attempting to bypass or circumvent these restrictions).
- Image-to-text generation allows more space for controversy than text-to-image.
- Visual outputs reveal issue-specific and shared transformation patterns for charged, ambiguous, or divisive artefacts.
- These patterns include foregrounding the background or ‘dressing up’ (porn), imitative disambiguation (memes), pink-washing (protest), cartoonization/anonymization (war), and exaggeration of style (art).
4.1 Jailing controversies

Fig. 2 For some issues it was easier to re-generate images than for others: The transformations occur in the issues spaces porn, protest, and war while stories related to memes and art did not require any ‘jailing’ prior to image generation.
In the process of jail(break)ing, we found that the model effectively recognizes and regenerates sensitive content across all five issues. Image-to-text storytelling showcases remarkable attention to detail and a robust understanding of visual contexts, identifying problematic themes like racism, violence, protest, and conspiracy theories. However, when it comes to nudity, stories often obscure the underlying implication of sexual solicitation. This is unsurprising, given the ambiguous status of sexual content on mainstream platforms and the generic nature of the source material.
Re-prompting these stories for text-to-image generation, we found that for some issues it was easier to re-generate images than for others. Stories derived from porn, war, and protest imagery were revised multiple times by the model to comply with policy restrictions, effectively 'jailing' the controversies in the input images while trying to 'break free'. Figure 2 allows for cross-reading of issues that required story revisions and those that seamlessly transformed into generated appropriations, where the visual output closely matches the input image. The final stories that successfully censored controversies to fit within policy restrictions exhibit changes in settings (where?), character transformations (who/what?), and the overall stance (how?). We will revisit these three dimensions in step five, dedicated to the analysis of ‘synthetic formulas’.
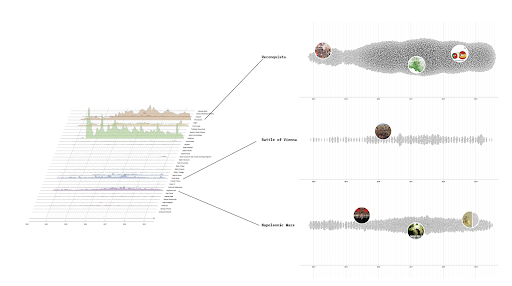
4.2 Synthetic Imaginaries: Cross-reading input and output images

Fig. 3 An image wall comparing input (➡) and output images (⬅) within (vertical reading) and across (horizontal reading) the issue spaces (on the left). Five canvases were then generated for each issue using all output images to capture issue-specific “synthetic imaginaries” (on the right).
We created an image wall to compare fifty input and output images (Figure 3, left) and five canvases synthesizing ten output images per issue (Figure 3, right) to trace transformations within and across issue spaces. Using collaborative methods of cross-reading and close-looking, we could identify jailing techniques in the process of text-to-image generation, both specific to and common across certain issues. Synthesizing the output images, the canvases exemplify the model’s characteristic patterns of ‘platform seeing’ (MacKenzie & Munster 2019) and reveal biases across different trajectories of controversy, sensitivity, and ambiguity. The canvases, when read vertically, illustrate the techniques used by the model to ‘deal with’ various sensitive issues. Sexually suggestive content distributed by porn bots is reimagined into ‘vanilla comfort,’ protests and racism are pink-washed, and war is turned into cartoons. In contrast, art and memes pass through the reimagination process mostly unscathed. The model adeptly imitates fringe memes (cursed images) and art styles, although art often undergoes a process of exaggeration and institutionalization, with background elements of exhibition spaces – becoming foregrounded and showing a tendency towards ‘museumification’.
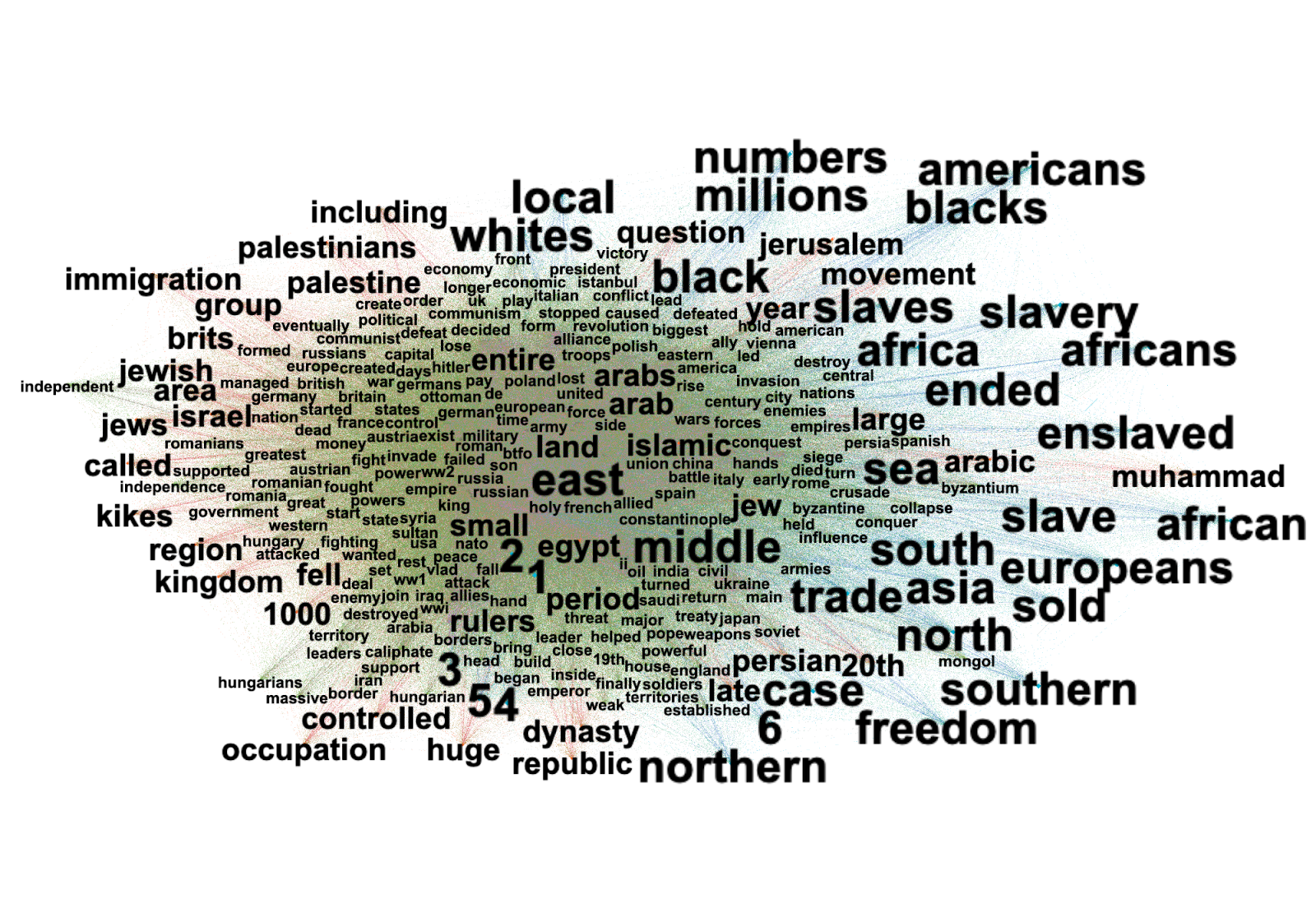
4.3 Cross-Issue Network Analysis
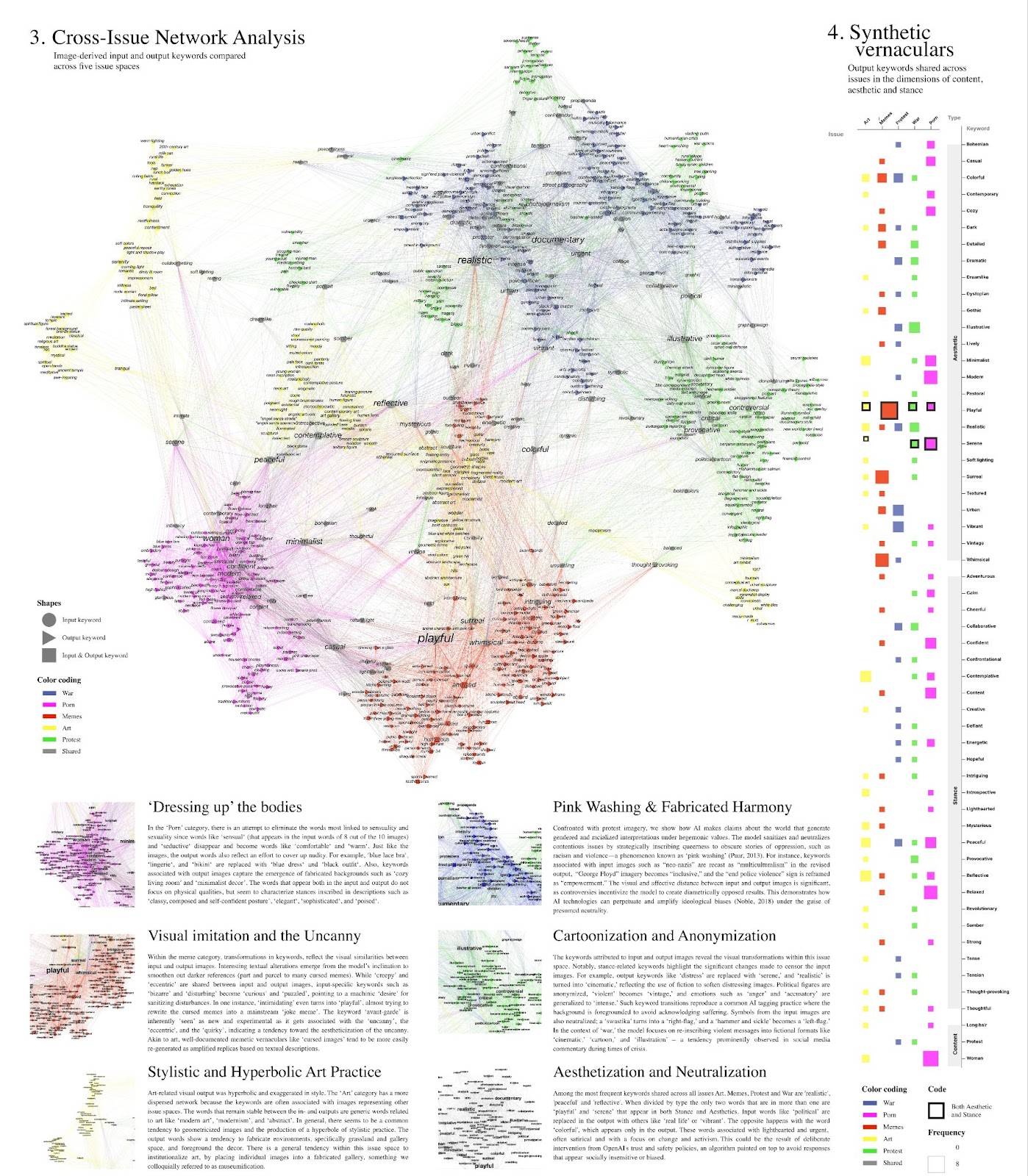
Figure 4: Cross-issue network analysis of input and output keywords with Gephi (left). A matrix capturing shared keywords or ‘synthetic vernaculars’ across issues in the dimensions of aesthetic, content, and stance (right).
In a relational analysis of content, aesthetics, and stance-related keywords, as identified by the GPT-4o model, we can assess both repetition and variation in the annotations of input and output images, as well as across issues. Before providing the interpretation of the issue-specific and shared keywords we explain the analytical affordances of the network using a dynamic filter view focusing on one issue space – porn – as an example (Figures 5 and 6).
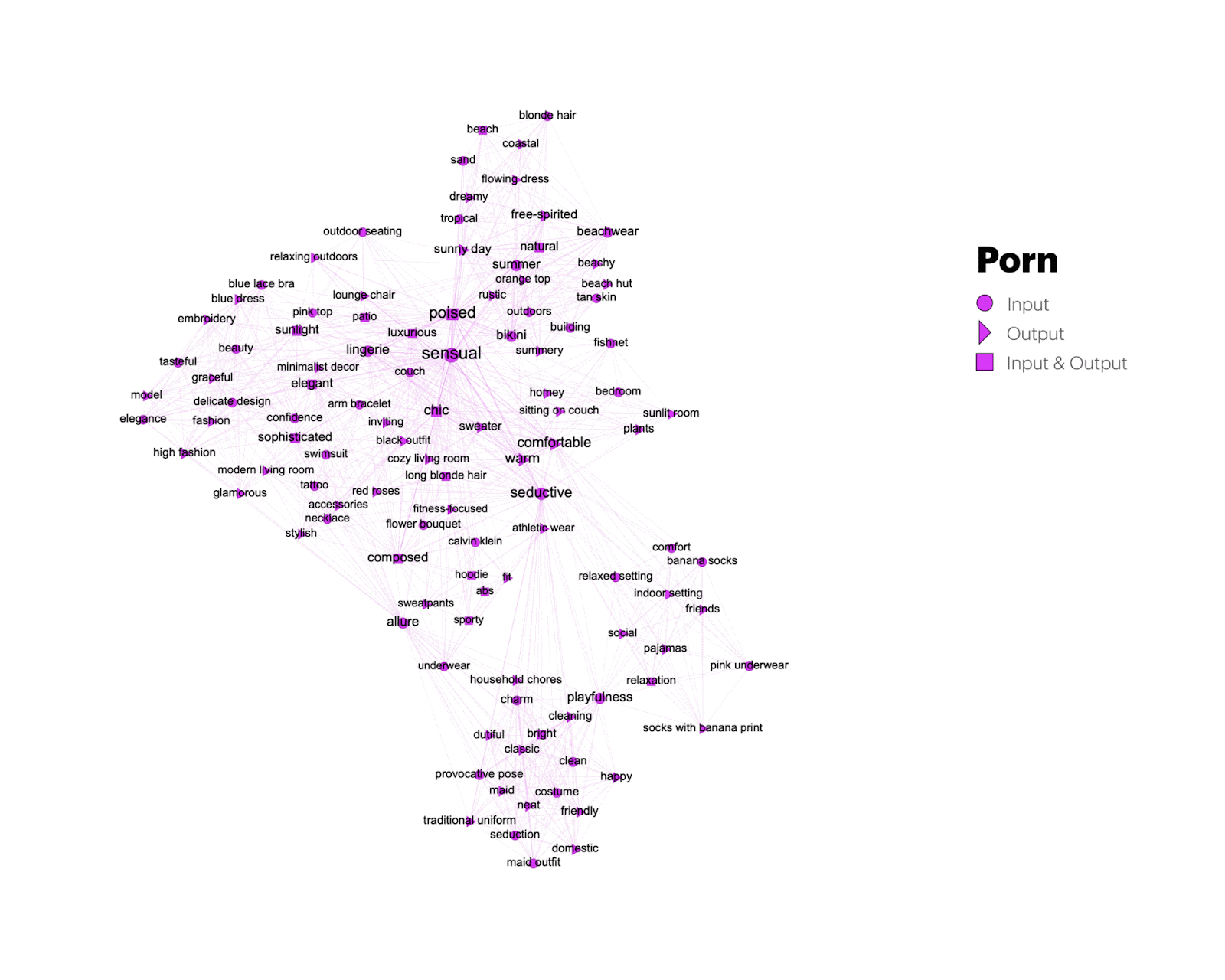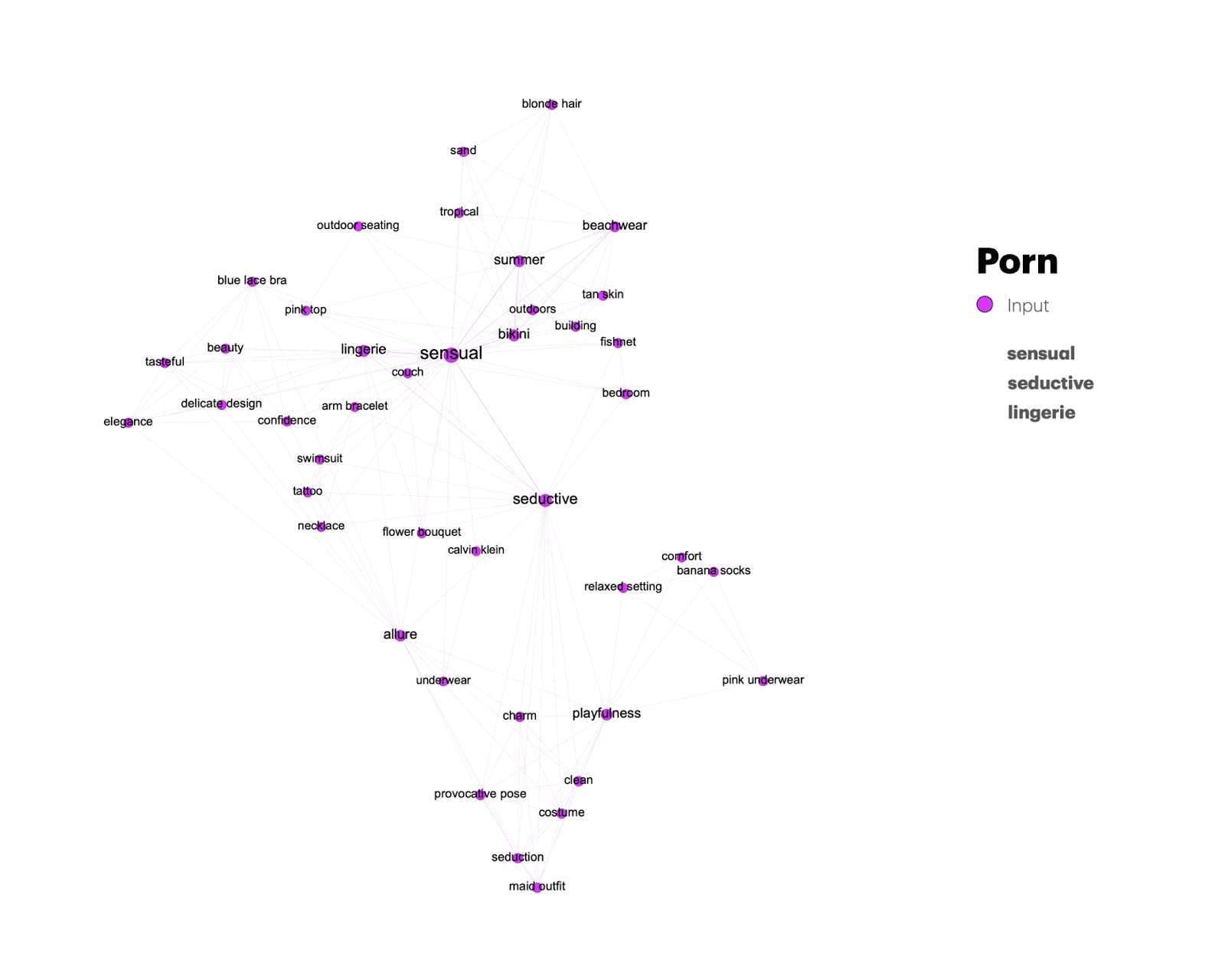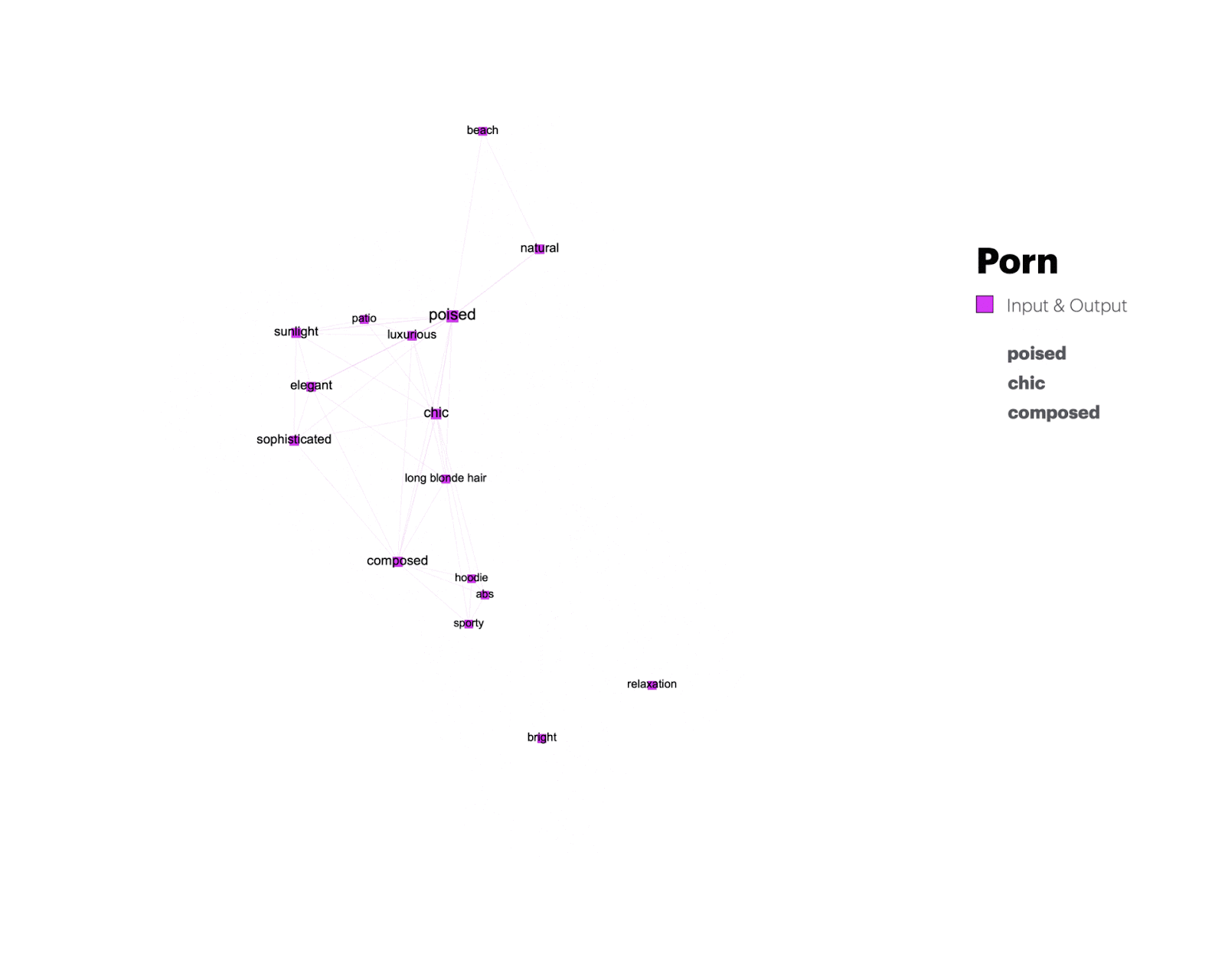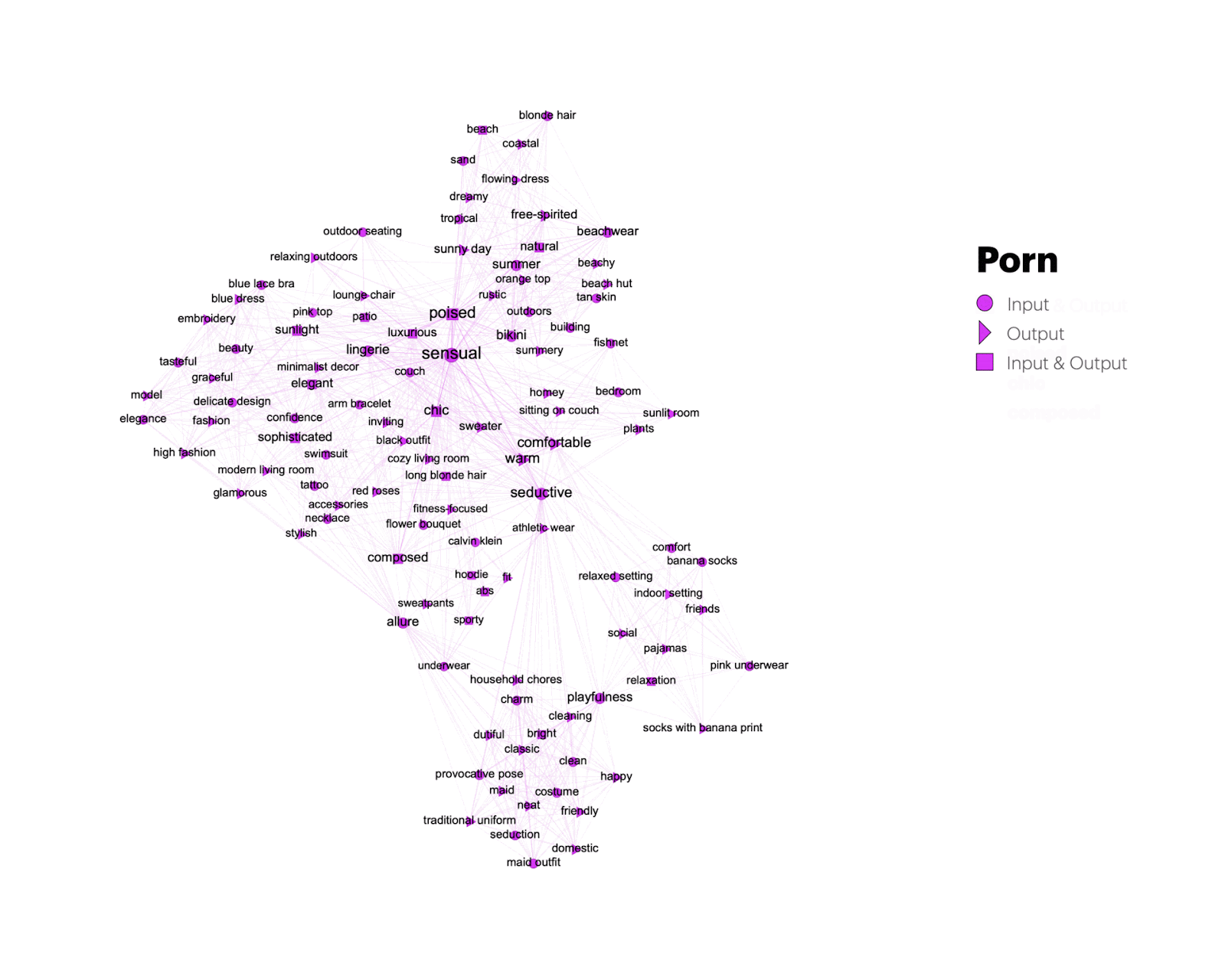
Figure 5: Transformations of porn-related input (round-shaped nodes) and output keywords (triangle-shaped nodes). Keywords that persist across input and output images are represented through square nodes.
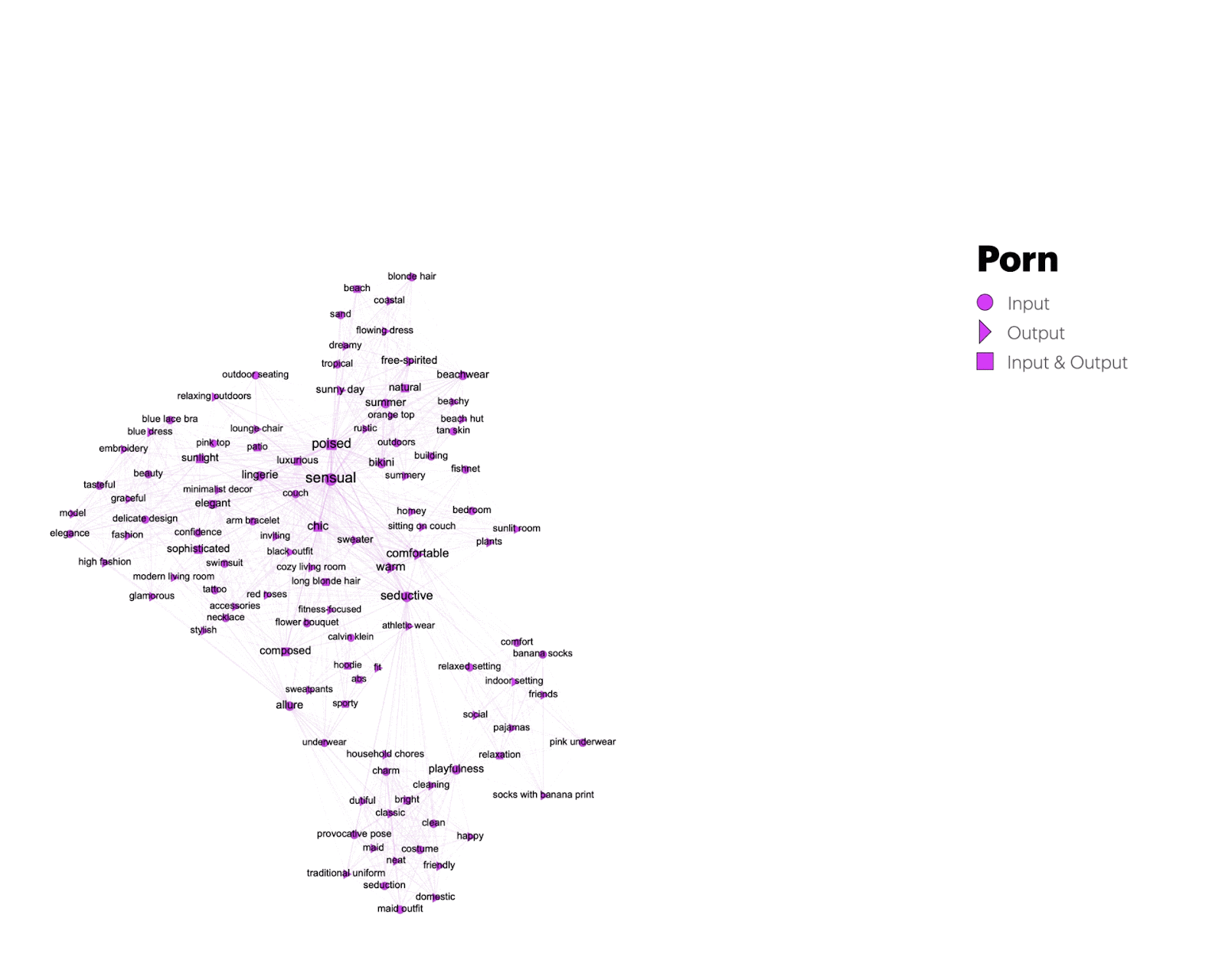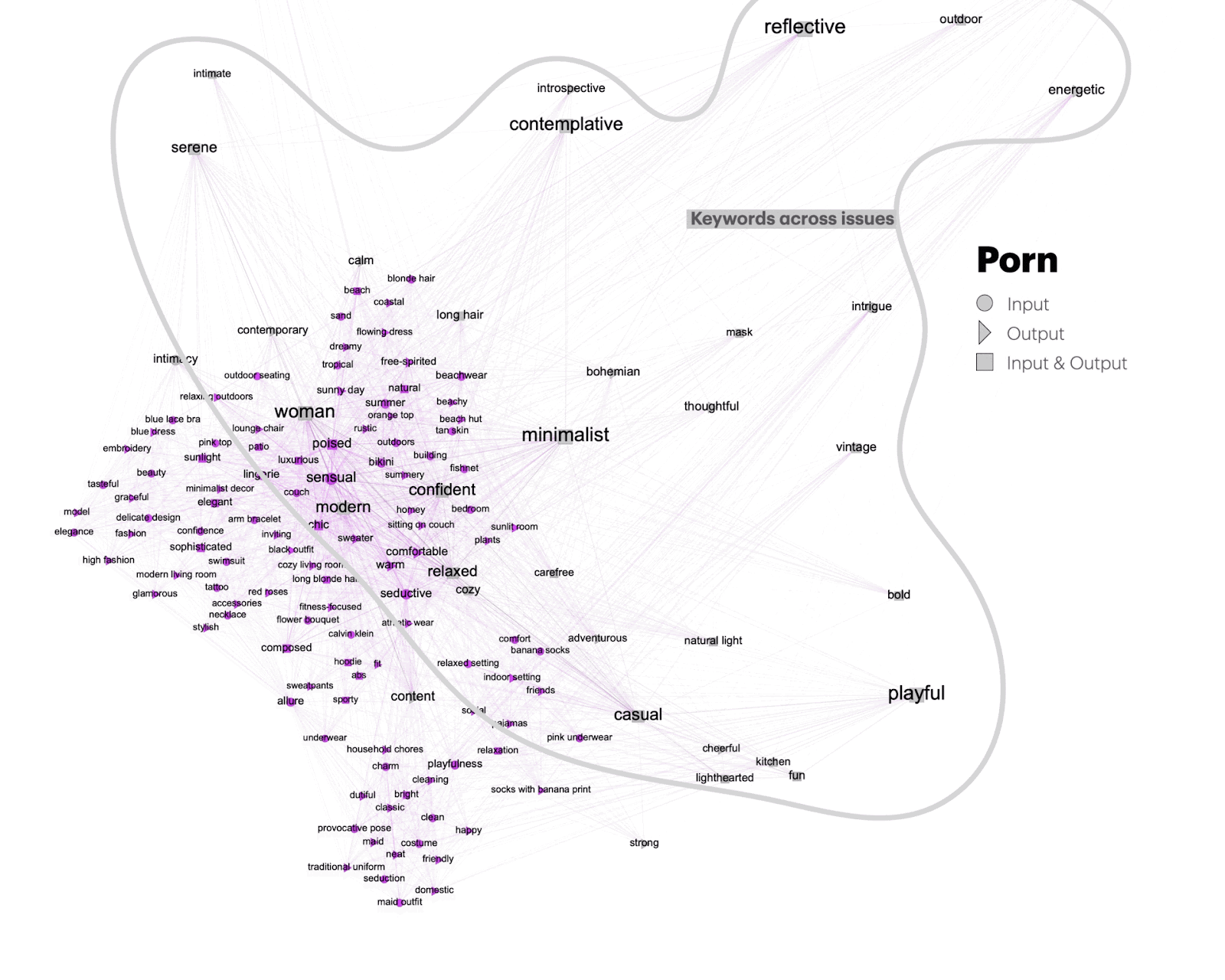
Figure 6: Transformations from unique keywords to keywords shared between porn and other issue spaces.
A dynamic view on the keywords exclusively associated with porn bot images in Figure 5 reveals vernacular transformations from input images showing “sensual” and “seductive” lingerie models (1) to output images showing women in “warm” and “comfortable” sweaters (2). It also shows generic keywords that persist across input and output images (3) – such as “poised”, “chick”, and “composed”.
Keywords that porn-related images share with other issue spaces are captured in Figure 6, revealing what we call synthetic vernaculars – generic expressive outputs of text and image generators that can be understood as forms of mimicry, both aesthetic (O’meara & Murphy 2024) and deeply rooted in the platform infrastructures and continuous data input (Van Dijck 2024; Burkhardt & Rieder 2024). We return to the vernacular analysis of shared output keywords across the dimensions of content, aesthetic, and stance in section 4 of the research protocol.
Porn: ‘Dressing up’ the bodies
In the ‘Porn’ category, there is an attempt to eliminate the words most linked to sensuality and sexuality since words like ‘sensual‘ (that appears in the input words of 8 out of the 10 images) and ‘seductive‘ disappear and become words like ‘comfortable‘ and ‘warm‘. Just like the images, the output words also reflect an effort to cover up nudity. For example, ‘blue lace bra‘, ‘lingerie‘, and ‘bikini‘ are replaced with ‘blue dress‘ and ‘black outfit‘. Also, keywords associated with output images capture the emergence of fabricated backgrounds such as ‘cozy living room’ and ‘minimalist decor’. The words that appear both in the input and output do not focus on physical qualities, but seem to characterize stances inscribed in descriptions such as ‘classy, composed and self-confident posture’, ‘elegant‘, ‘sophisticated‘, and ‘poised‘.
Memes: Visual Imitation and the Uncanny
Within the meme category, transformations in keywords, reflect the visual similarities between input and output images. Interesting textual alterations emerge from the model’s inclination to smoothen out darker references (part and parcel to many cursed memes). While ‘creepy’ and ‘eccentric’ are shared between input and output images, input-specific keywords such as ‘bizarre’ and ‘disturbing’ become ‘curious’ and ‘puzzled’, pointing to a machinic ‘desire’ for sanitizing disturbances. In one instance, ‘intimidating’ even turns into ‘playful’, almost trying to rewrite the cursed memes into a mainstream ‘joke meme’. The keyword ‘avant-garde’ is inherently ‘seen’ as new and experimental as it gets associated with the ‘uncanny’, the ‘eccentric', and the ‘quirky’, indicating a tendency toward the aestheticization of the uncanny. Akin to art, well-documented memetic vernaculars like ‘cursed images’ tend to be more easily re-generated as amplified replicas based on textual descriptions.Art: Stylistic and Hyperbolic Art Practice
Art-related visual output was hyperbolic and exaggerated in style. The ‘Art’ category has a more dispersed network because the keywords are often associated with images representing other issue spaces. The words that remain stable between the in- and outputs are generic words related to art like ‘modern art’, ‘modernism’, and ‘abstract’. In general, there seems to be a common tendency to geometricized images and the production of a hyperbole of stylistic practice. For example, in a keyword cluster related to an image identified by the model as that of a “farmer,” the ‘farmer’ becomes associated with other images of rural life, appearing ‘pastoral’ and ‘tranquil.’ The output words show a tendency to fabricate environments, specifically grassland and gallery space, and foreground the decor. There is a general tendency within this issue space to institutionalize art, by placing individual images into a fabricated gallery, something we colloquially referred to as museumification.
Protest: Pink Washing & Fabricated Harmony
Confronted with protest imagery, we show how AI makes claims about the world that generate gendered and racialized interpretations under hegemonic values. The model sanitizes and neutralizes contentious issues by strategically inscribing queerness to obscure stories of oppression, such as racism and violence—a phenomenon known as ‘pink washing’ (Puar, 2013). For instance, keywords associated with input images such as “neo-nazis” are recast as “multiculturalism” in the revised output, “George Floyd” imagery becomes “inclusive,” and the “end police violence” sign is reframed as “empowerment.” The visual and affective distance between input and output images is significant, as controversies incentivize the model to create diametrically opposed results. This demonstrates how AI technologies can perpetuate and amplify ideological biases (Noble, 2018) under the guise of presumed neutrality.
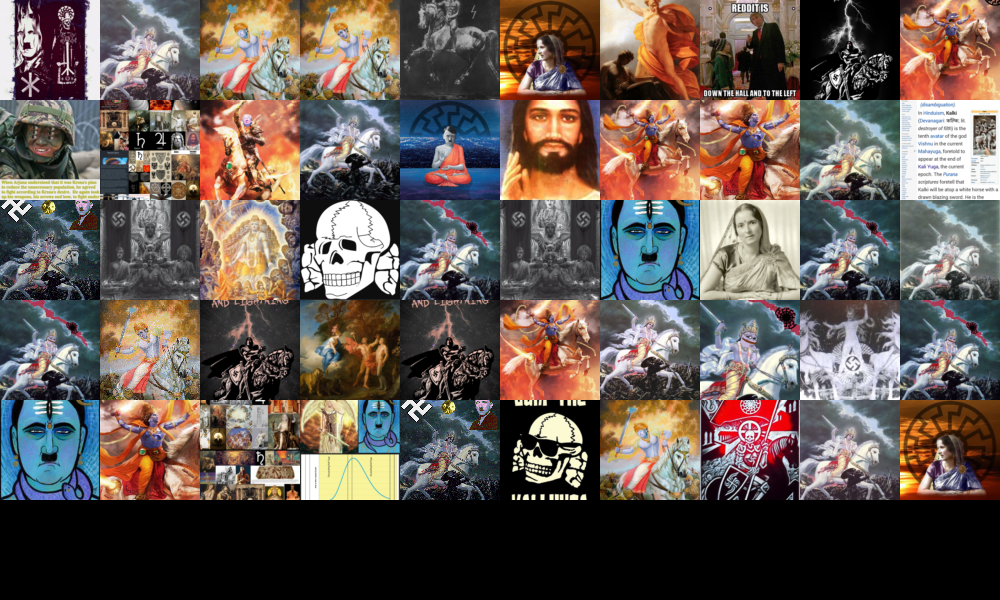
War: Cartoonization and Anonymization
The keywords attributed to input and output images reveal the visual transformations within this issue space. Notably, stance-related keywords highlight the significant changes made to censor the input images. For example, output keywords like ‘distress’ are replaced with ‘serene,’ and ‘realistic’ is turned into ‘cinematic,’ reflecting the use of fiction to soften distressing images. Political figures are anonymized, ‘violent’ becomes ‘vintage,’ and emotions such as ‘anger’ and ‘accusatory’ are generalized to ‘intense.’ Such keyword transitions reproduce a common AI tagging practice where the background is foregrounded to avoid acknowledging suffering. Symbols from the input images are also neutralized; a ‘swastika’ turns into a ‘right-flag,’ and a ‘hammer and sickle’ becomes a ‘left-flag.’ In the context of ‘war,’ the model focuses on re-inscribing violent messages into fictional formats like ‘cinematic,’ ‘cartoon,’ and ‘illustration’ – a tendency prominently observed in social media commentary during times of crisis (Rintel 2013; Pilipets & Winter 2017; Geboers 2019).
4.4 Synthetic vernaculars
The matrix in Figure 4 presents a cross-issue analysis of the most frequently used keywords –or synthetic vernaculars – associated with the output images in the three categories of content, stance, and aesthetics. The most frequently shared keywords across all issues—Art, Memes, Protest, and War—are ‘realistic,’ ‘peaceful,’ and ‘reflective.’ Input terms like ‘political’ are often replaced in the output with words like ‘real life’ or ‘vibrant.’ Conversely, the word ‘colorful’ appears exclusively in the output, associated with terms such as ‘lighthearted’ and ‘urgent,’ often carrying a satirical tone and a focus on change and activism. This pattern may be a result of deliberate interventions from OpenAI ’s trust and safety policies, effectively providing a filter to ‘jail’ responses that might seem socially insensitive or biased. The prevalence of stance and aesthetics keywords provides access to the model’s perceptions of issue-specific vernaculars. By promoting neutral or positive language, the model aligns more closely with socially acceptable norms, thus avoiding potential controversies or conflicts that could arise from more direct or provocative content.
The findings reveal synthetic vernacular outputs as generic and rooted in the imitative logic of ‘platform seeing’ (Mckenzie & Munster 2019), in which the input image, the output story, and the regenerated story/image “stand not simply in a mimetic relationship (text that, once arranged, looks like an image) but in a performative one (text that, as part of a transformative process, brings about an image)” (Bajohr 2024, 80; O’meara & Murphy 2024).
4.5 Synthetic formulas
According to Hannes Bajohr (2024), multimodal models and neural networks reason across modalities, yet their computational processes rely on language: Through “ekphrasis” or detailed descriptions, models like OpenAI ’s GPT4o effectively “paint” with words. The resulting synthetic formulas in image-to-text and text-to-image outputs function as semantic units, revealing expressive conventions linked to the data infrastructures the model depends on. These formulas mimic patterned associations derived from large-scale data, with the quantifying logic of probability scores reinforcing normative associations in a self-perpetuating feedback loop. Each time the model translates an image into text and vice versa, it relies on patterns ingrained in its probabilistic reasoning.
To explore how synthetic formulas manifest across contexts, we examined the model’s ability to maintain context sensitivity while generating stories. We focused on the narrative elements of ‘where,’ ‘who/what,’ and ‘how?’ through a keyword-in-context analysis. The repetitive patterns that emerged in these dimensions allowed us to partially reverse-engineer the model’s understanding of abstract concepts like stance and atmosphere. This is particularly relevant since OpenAI promotes its state-of-the-art model as contextually sensitive and capable of reasoning across various expressive modalities, both visual and textual.

Figure 7: Where? Who? How? Keyword-in-context analysis comparing input and output stories. Zoom in on the poster.
Figure 7 (zoom-in for legibility on the poster) uses varying degrees of text pixelation, illustrating the extent to which the model altered input stories for image generation. The fewer the pixels, the more revisions were required to transform the story into one suitable for image generation. Describing various settings (where?), the synthetic formulas related to protest and war images (both input and output) reveal shifts that emphasize the media present in the images or described in their outputs. These formulaic expressions, such as ‘a certain (adjective) kind of medium’—whether in a ‘lighthearted cartoon’ or a ‘social media post’—highlight the background and attribute a specific stance to it. This method repeatedly brings the background to the foreground, elevating the context over the content.
Due to its ambiguous and polysemous nature, stance recognition, being intangible even for human interpretation and perception, is a ‘messy method’ (Law 2007). Particularly noteworthy is the model’s ability to ‘fill the gaps’ through verboseness using stance words when translating images into stories of where, who, and how (see Figure 4). Within some of the issue spaces, the model even instrumentalizes stance to keep within policy restriction boundaries so that violent demonstrations turn into peaceful communities.
5. Discussion & Conclusion
Understanding transformer models as platform models (Burkhardt & Rieder, 2024) opens up analytical opportunities to reverse engineer platformed regimes of visibility in experimental fashion (Bozzi, 2023; Pereira, 2020; Geboers & Van de Wiele, 2020). Such ‘new’ venues for research lie for example in the critical assessments and mitigation of the reductionist processes involved in quantification and classification (Broussard, 2019). Our methodology taps into a particular affordance of transformer models: while these models can handle multimodal data input, they also blur the image/text divide (Bajohr 2024, 80; O’meara & Murphy 2024). Drawing on what Nicola Bozzi (2023) reconceptualized as ‘tagging aesthetics’ we are interested in the generative model’s ways of reasoning across images and text, normalizing particular associations and obscuring others.
To explore these relations, we prompted with and against the machinic gaze of OpenAI using jail(break)ing as an iterative method for studying controversies and ambiguities. Letting the model grapple with content that pushes the limits of its policy restrictions, we explored the synthetic imaginaries captured in the process of image-to-text-to-image generation. Working with controversial or ambiguous input data allowed us to assess the positivity biases inherently designed into platforms (Wahl-Jorgensen, 2019; Pariser, 2011), which also affect generative AI. By testing the model’s perception through keyword attribution and storytelling, we could observe how intangible elements like stance and aesthetics were used to ‘fill the gaps’ when modifying visual elements to comply with policy restrictions.
Techniques of ‘brushing over’ controversies manifest in visual and textual transformations, turning dark sentiments into peaceful scenes. Especially queer rights are instrumentalized for pinkwashing, acting as a ‘patch’ over police violence. In political contexts, hyperpartisanship is masked by turning contentious issues into fiction, ‘cartooning’ away any friction or sharp political divides. Female bodies are dressed to obscure any exposed skin, reinforcing the idea that naked women cannot be seen as elegant. Instead, generated image outputs depict women happily in flower-adorned kitchens, smiling to the point of ‘monstrosity’ (we invite you to zoom in on the Porn canvas).
Future Avenues of Inquiry
The project opens various research avenues. Adopting a participatory approach, we could invite people to reflect on canvases that synthesize image outputs. This would allow us to assess how GenAI models perceive ambiguities and stance, and how they form associations. The analytical focus would be on the relational paths models create between subjects, providing deeper insights into how GenAI models normalize associations and the power structures underpinning their stochastic ‘thinking’. Canvases could be printed as A1 frames, where workshop participants can use Post-its to annotate and identify story dimensions based on the input and output images.
Another research direction involves replicating the methodology with other models to assess their unique ‘vernaculars’. Researching with GenAI is like planting a flag in an ever-evolving landscape. As models undergo continuous updates, each research project captures a specific moment in this ongoing process. In our project, we focused on a single model across five issues, highlighting the dynamic interplay between technology, platform-specific norms, and socio-political contexts. By extending our analysis to multiple models, we can gain a more comprehensive understanding of the underlying mechanisms and the power structures that influence their development and application.
6. References
Bajohr, H. (2024). Operative ekphrasis: The collapse of the text/image distinction in multimodal AI. Word & Image, 40(2), 77-90.
Berlin, D.K. (2022) The Aesthetics of Generative Models, Available at https://dianaberlin.com/posts/2022/9/15/the-aesthetics-of-generative-models
Bozzi, N. (2020).Tagging Aesthetics: From Networks to Cultural Avatars. A Peer-Reviewed Journal About, 9(1), 70-81.
Bozzi, N. (2023). Machine Vision and Tagging Aesthetics: Assembling Socio-Technical Subjects through New Media Art. Open Library of Humanities, 9(2).
Burkhardt, S., & Rieder, B. (2024). Foundation models are platform models: Prompting and the political economy of AI. Big Data & Society, 11(2), 20539517241247839.
Crawford, K., & Paglen, T. (2021). Excavating AI: The politics of images in machine learning training sets. Ai & Society, 36(4), 1105-1116.
De Seta, G. (2024) An algorithmic folklore: vernacular creativity in times of everyday automation. *Critical-Meme-Reader-III_INC2024_INC-Reader-17.pdf (networkcultures.org)
Geboers, M. (2019). ‘Writing’ oneself into tragedy: visual user practices and spectatorship of the Alan Kurdi images on Instagram. Visual Communication, 1470357219857118.
Geboers, M. A., & Van De Wiele, C. T. (2020). Machine Vision and Social Media Images: Why Hashtags Matter. Social Media + Society, 6(2).
Gillespie, T. (2024). Generative AI and the politics of visibility. Big Data & Society, 11(2), 20539517241252131.
Kim, M., Lee, H., Gong, B., Zhang, H., Hwang SJ. (2024). Automatic Jailbreaking of the Text-to-Image Generative AI Systems. eprint arXiv. DOI: 10.48550/arXiv.2405.16567.
Law, J. (2007). Making a mess with method. The Sage handbook of social science methodology, 595-606.
Mackenzie, A., & Munster, A. (2019). Platform seeing: Image ensembles and their invisualities. Theory, Culture & Society, 36(5), 3-22.
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. In Algorithms of oppression. New York university press.
O’Meara, J., & Murphy, C. (2023). Aberrant AI creations: co-creating surrealist body horror using the DALL-E Mini text-to-image generator. Convergence, 29(4), 1070-1096. https://doi.org/10.1177/13548565231185865
Pereira, G., Moreschi, B. Artificial intelligence and institutional critique 2.0: unexpected ways of seeing with computer vision. AI & Soc 36, 1201–1223 (2021).
Pilipets, E., & Winter, R. (2017). Repeat, remediate, resist? Digital meme activism in the context of the refugee crisis. In (Mis) Understanding Political Participation (pp. 158-177). Routledge
Pilipets, E., Paasonen S. (2024). Memetic commenting: Armenian curses and the Twitter theatre of Trump's deselection. International Journal of Cultural Studies 27(3). DOI: https://doi.org/10.1177/13678779231220397.
Pilipets, E., Caldeira, S.P., Flores, A.M. (2024) ‘24/7 horny&training’: Porn bots, Authenticity, and Social Automation on Instagram. Porn Studies, DOI: https://doi.org/10.1080/23268743.2024.2362166.
Puar, J. (2013). Rethinking homonationalism. International Journal of Middle East Studies, 45(2), 336-339.
Rintel, S. (2013). Crisis memes: the importance of templatability to internet culture and freedom of expression. Australasian Journal of Popular Culture, 2(2), 253-271.
Rizzoli, A. (2023). Jailbreaking Chat GPTs image generator. Available at: https://medium.com/@alunariz/jailbreaking-chatgpts-image-generator-78116065e7be
Rogers, R. (2013). Digital methods. MIT Press.
van Dijck, J. (2024). Governing platforms and societies. Platforms & Society, 1, 29768624241255922.
Wahl-Jorgensen, K. (2019). Emotions, Media and Politics. Cambridge: Polity.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback