✨ What if LLMs are Our New (Re)search Engines?
A Longitudinal Interrogation of ChatGPT -4o Web Search Results (Dec 2024–June 2025)
Team Members
PROJECT FACILITATORS
Janna Joceli Omena [ project pitcher ], Giulia Tucci [ post-doc researcher ], Claire Capone and Roberta Parisi [ designers ]
TEAM MEMBERS
Christian Brand, Zhuohang Stella Li, Yuchen Ling Judy, Maricarmen Rodríguez-Guillen, Aanila Tarannum, Yagmur Cisem Vik, Anita Wang, Jupiter Wei Wang, Nuoyi Wang, Tristan Zhuofan Wang, Xinlu Wang, Silei Zhu, Yuteng Zhang
Links & How to cite
To poster / datasets / graphics folder / prompts and meta-prompts for dataset building / interactive visualisations: https://public.flourish.studio/visualisation/24174513/, Sunburst Websource - Category + domain | Flourish
Omena, J. J., Tucci, G., Capone, C., Parisi, R., Brand, C., Li, Z. S., Ling, Y. J., Rodríguez-Guillen, M, Tarannum, A., Vik, Y. C., Wang, A., Wang, J. W., Wang, N., Wang, T. Z., Wang, X., Zhu, S., & Zhang, Y. (2025). What if LLMs are our new (re)search engines? A longitudinal interrogation of ChatGPT -4o web search results (December 2024–June 2025). Digital Methods Initiative. https://www.digitalmethods.net/Dmi/SummerSchool2025LLMsAsResearchEngines
Contents
- Team Members
- Links & How to cite
- Contents
- Summary of Key Findings
- 1. Introduction
- 2. Research Questions
- 3. Longitudinal Prompt Method (LPM) for Dataset Building
- 4. Methodology
- 5. Findings
- 5.2 Textual outputs: ChatGPT -4o conflicting responses and shifting discourse traits
- 5.3 Web Sources: ChatGPT -4o’s citation behaviour
- 6. Discussion: ChatGPT as a prompt-sensitive (re)search engine
- 7. Conclusions
- 8. References
Summary of Key Findings
This report studies LLMs as (re)search engines and proposes a longitudinal prompt method. It emphasises the extra effort needed to critically read LLM outputs: repeat the prompts, capture everything (text, recommended links, and screen-captures), keep field notes, and let the prompt set evolve over time. The findings below refer to ChatGPT -4o’s responses to the same prompts and meta-prompts between December 2024 and July 2025.
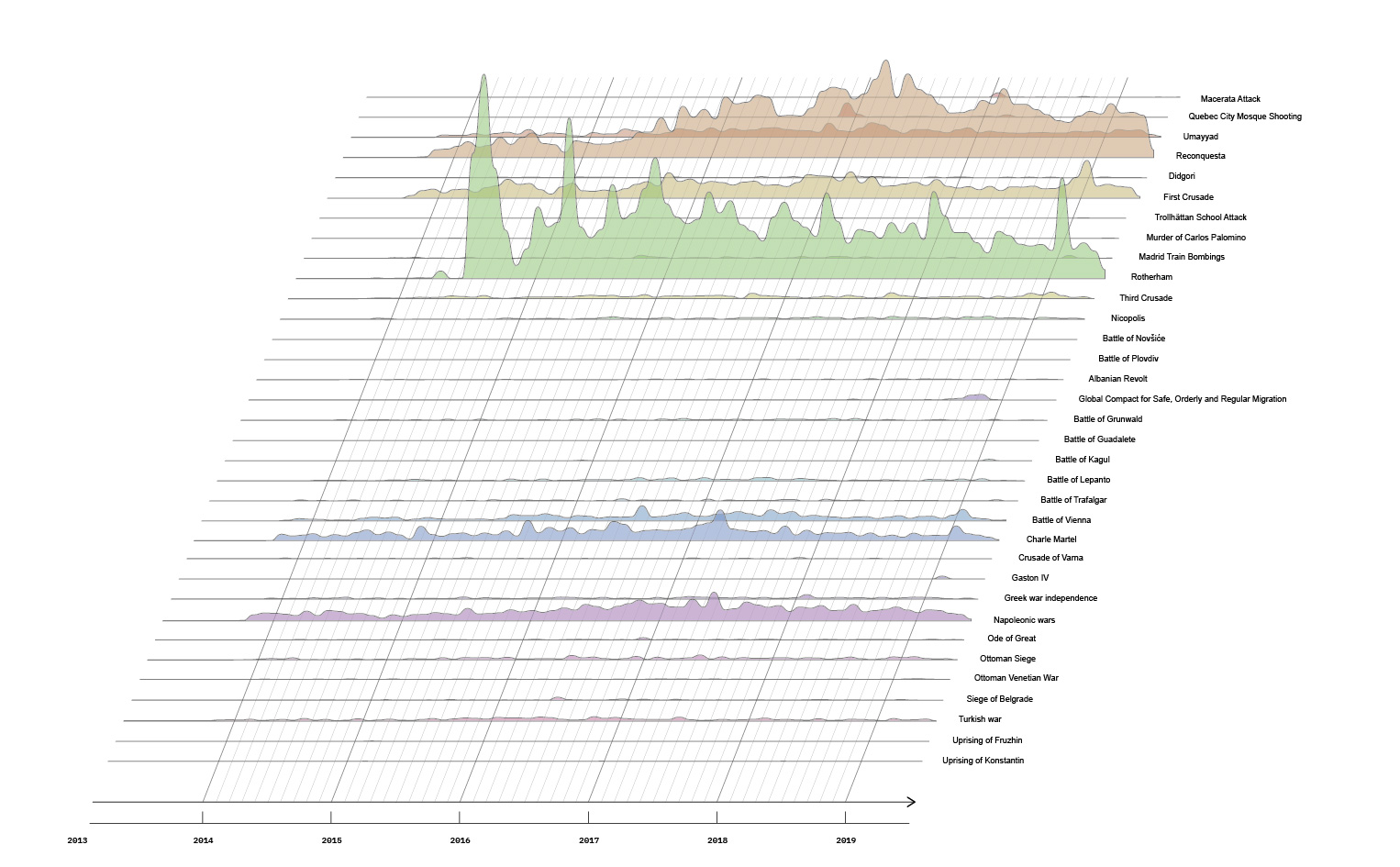
Visual Layout Method with the analysis of screen-capture timeline grid of ChatGPT -4o responses
-
Length jump on 4 Mar 2025, with visibly longer answers.
-
25 Mar 2025: comparison tables appear; references broaden (e.g., YouTube /News).
-
22 May 2025: more “confident” tone, hyperlinks added, quotation blocks used.
-
17 Jun 2025: emoji bullets, reference thumbnails, citation blocks, and TL;DR summaries adopted.
-
24 Jun 2025: personalised recommendations enter the layout.
Text Methods with ChatGPT -3o and thematic coding
Conflicting statements over time refer to:
-
The references the GPT-4o uses to define generative AI architecture shift their focus from GANs/VAEs to Transformers/LLMs.
-
Which web provider feeds the web search function; Bing-only today, multiple providers tomorrow and back and forth.
-
Who is the ranking authority: OpenAI ’s own criteria → Bing’s algorithm
-
The model’s capability in browsing the web actively.
Discursive traits:
-
Getting critical responses/Critical thinking is triggered, not autonomous (“push-to-talk” style).
-
A self-framing shift from knowledge authority to a collaborative tool.
-
GPT-4o exhibits less padding, more structured, analytically denser passages by the late period (from volume to value), and cultural flatness, as responses tend to be technocentric; Western-leaning references persist.
Web Sources Method: ChatGPT 4o’s citation behaviour over time
-
IP geography is US-centric; the UK is second (and the prompt location); few non-Western sources.
-
Commercial domains dominate overall (~40%); recurring sources are common (≈55%), signalling consolidation.
-
Meta-prompts (credibility/providers) draw in more journalistic and OpenAI sources; routine prompts revert to commercial cores.
-
OpenAI docs are slow to appear for the seed prompt, then surge when explicitly requested, but commercial sites reassert by June.
-
New domains spike for follow-ups 1 and 4; otherwise, recurring domains prevail.
1. Introduction
The integration of web search into LLMs marks a significant shift in the landscape of online information retrieval—searching and consuming information. This functionality only became widely available in late 2024, when ChatGPT and Copilot began integrating web search. A shift from query-response models (search engines) to dynamic and conversational formats (generative AI interfaces) opens up new opportunities for and in the tradition of digital methods—both by extending its focus on digitally native methods and by helping to overcome the divide between qualitative and quantitative research techniques (Pilati, Munk & Venturini, 2024).
This project explores the as-yet understudied area of generative search and its capacities for advancing digital methods research. It then investigates ChatGPT ’s integration of web search through the Longitudinal Prompt Method (LPM) for dataset building, utilising repeated (meta) prompting, qualitative observation, field notes, and scraping methods. The aim is to understand the consistency, source logic, and underlying operations guiding LLMs' responses. Aligning with the platform observability approach (Rieder & Hoffman, 2020), this focus is on the empirical and temporal dimensions of AI responses/outputs (Rogers, 2018; Rieder, Matamoros-Fernández, & Coromina, 2018), and asks: What if LLMs Are Our New (Re)search Engines?
We, then, investigate the epistemic performance of OpenAI ’s ChatGPT-4o with a web search function—focusing on how it performs search, references knowledge, and mediates web-based authority. We also examine changes in the model's discourse traits and visual layout, considering conflict responses. The aim is to build a grounded understanding of how ChatGPT-4o integrates web search behaviour in practice, beyond what technical documentation reveals.
2. Research Questions
While large language models like GPT-4o are increasingly used (and act) as research assistants (synthesising information, citing sources, and even mimicking the structure of academic writing), their function mechanisms remain an opaque system. In particular, we know little about how these models select which references to surface, how stable their answers are over time, or how their tone, depth, and cultural framing shift with each iteration, nor which webpage categories they privilege when consulting the web.
Drawing on a scraped corpus of GPT-4o’s dated responses and citations, this study treats the model itself as both subject and object of inquiry: we examine not just what it says, but how it says it, where it looks for evidence, and why that matters. To guide this investigation, we pose the following research questions (RQs):
RQ1: How does ChatGPT-4o’s visual layout of its answers evolve over time—in length, layout devices, and visual cues?
RQ 2: To what extent are ChatGPT-4o’s responses (in)consistent?
RQ 3: How do the stylistic and discursive traits of ChatGPT -4o’s answers change over time?
RQ 4: What does GPT-4o’s citation behaviour look like—-including the frequency, type and geographic/domain origin—and which sources dominate across time?
RQ 5: Which new sources emerge over time, and how do those additions correspond to the prompts that were asked?
RQ 6: For each prompt, which domain categories does GPT-4o cite uniquely?
3. Longitudinal Prompt Method (LPM) for Dataset Building
The longitudinal prompt methods for dataset building offer a protocol for understanding AI behaviour by issuing the same (meta) prompts at repeated time points, systematically capturing the full outputs (text, visual layout, citations, metadata) and critically comparing them over time. LPM combines systematic data collection with reflexive fieldnote observations and an adaptive prompt set, as the method stays flexible and open to expansion. While prompting over time, new prompts (follow-ups) can be added when the model’s replies, opening up fresh lines of enquiry. The six questions consist of one initial prompt and five follow-up questions that are developed in an addendum at different times.
The initial prompt was developed and tested on the 3rd of December 2024, the first follow-up question was inserted on the 11th of February 2025, the second follow-up question was inserted on the 18th of February 2025; the rest of the follow-up questions focuses on web search infrastructure, and one of them is added the 11th of March 2025 while the other two are included on the 17th of April 2025. See below the initial and follow-up prompts adopted in this project.

An overview of the LPM protocol
-
Temporal prompt runs: fixed cadence (e.g. weekly, every two weeks), same seed + follow-ups> note date/time, model/version, settings, and location. This project scrapes ChatGPT -4o Web Search Outputs Over Time (Dec 2024–June 2025), collecting data twice or three times a month with intervals of one or two weeks. It started in December 2024, when OpenAI extended the web search functionality to all logged-in users. List of prompts: Longitudinal Prompt Methods.docx
-
Systematic capture: insert the prompt> read the answer and jot fieldnotes when needed> save the text to a file named with the date + prompt> take a screen-capture and name it accordingly> scrape all cited sources with browser scrapers (e.g., Instant Data Scraper, Link Klipper). Repeat for each prompt. See below how this project is structured and organised for data file saving.

-
Fieldnote observations: while prompting and capturing data, we note insights, anomalies, and prompting decisions (whether or not it is necessary to create a new prompt). In digital-methods-oriented research, these notes reside in the qualitative layer, guiding and supporting analysis, and, crucially, marking the platform environment as an active agent that shapes both what we capture and how we interpret it. Examples of reflexive fieldwork notes are provided here and below.

-
Adaptive expansion: add new prompts in response to the responses> log the rationale and timestamp> keep the seed prompt stable> and decide when to stop new prompts.
Example of prompt expansion (why add new prompts): After follow-up question 3 (11 March 2025) asked about third-party search providers and ranking, the model’s replies started listing “prominent news organisations” as if they were providers. This misclassification prompted the addition of the follow-up questions 4 and 5 (17 April 2025) to force clarification—asking for concrete provider names, where this was announced, and challenging the “news-organisations-as-providers” framing.
3.1 Data Files, Processing and Cleaning
Data files include text files containing ChatGPT ’s-4o responses, CSV files listing web sources’ URLs ranked by GPT along with their titles, publication dates, and short descriptions, and PNG files of screen captures. Field notes and critical observations collected over time are also included. CSV files followed two formats: multi-column files with structured data (containing varying but semantically consistent column names) and single-column files containing only links.
All .csv files were programmatically loaded into R. To standardise the dataset, files were read with their original column names and merged into a single data frame. A new column, file_name, was added to each entry to preserve the source filename as a reference. During the merge, missing columns were automatically filled with NA, allowing integration across all files while maintaining structural consistency. This approach preserved the integrity of the original data and enabled uniform downstream analysis.
Additionally, website icons corresponding to the source URLs were downloaded using Chrono Downloader, a Google Chrome extension.
Web sources merged file.

Text file: GPT-4o responses over time.

4. Methodology

This study employs longitudinal prompting methods to investigate how ChatGPT -4o integrates web search, selects sources, and generates responses when the same prompts are issued between December 2024 and June 2025. We combine text, visual and web source analysis.
Visual Layout Method: generate a screen-capture timeline grid of ChatGPT -4o responses to underpin visual layout analysis. First, place all screen captures on the timeline, then navigate and annotate them over time (qualitatively code), culminating in a second, summarised timeline grid that states the main findings. What to look at: temporal staging (before/after on the timeline); response length; progression from plain text → structured layouts (headings, bullets, tables/comparison blocks); citation presentation (hyperlinks, quotation/citation blocks, TL;DR summaries); visual cues & media (emoji bullets, thumbnails); personalisation & calls-to-action; and shifts in source mix (e.g., YouTube /News vs. commercial/OpenAI).
Text Method: combine text analysis with LLMs and thematic coding. The former relies on ChatGPT -3o to detect inconsistent and conflicting responses of ChatGPT-4o over time using the text file and fieldnotes. The latter analyses the length, clarity, tone and accuracy of the text, resulting in four thematic categories: Linguistic & Lexicon, Epistemic & Cognitive, Digital/AI-related, and Cultural & Identity.
Web Source Method: extract every cited source from each prompt, normalise the domains, and build an overview: map domain distribution by country/IP and by category, then chart new vs recurring domains over time (per prompt). Next, zoom in: build a prompt ↔ domain network to see core vs periphery, identify unique per-prompt sources, and read shifts linked to meta-prompts. What to look at: country/IP mix; domain categories (commercial, news, academic, OpenAI, etc.); new vs recurring timelines; consolidation vs exploration; unique domains per prompt; movements between core and periphery in the prompt–domain network.
4.1 Visual Layout Analysis with screen-capture timeline grid
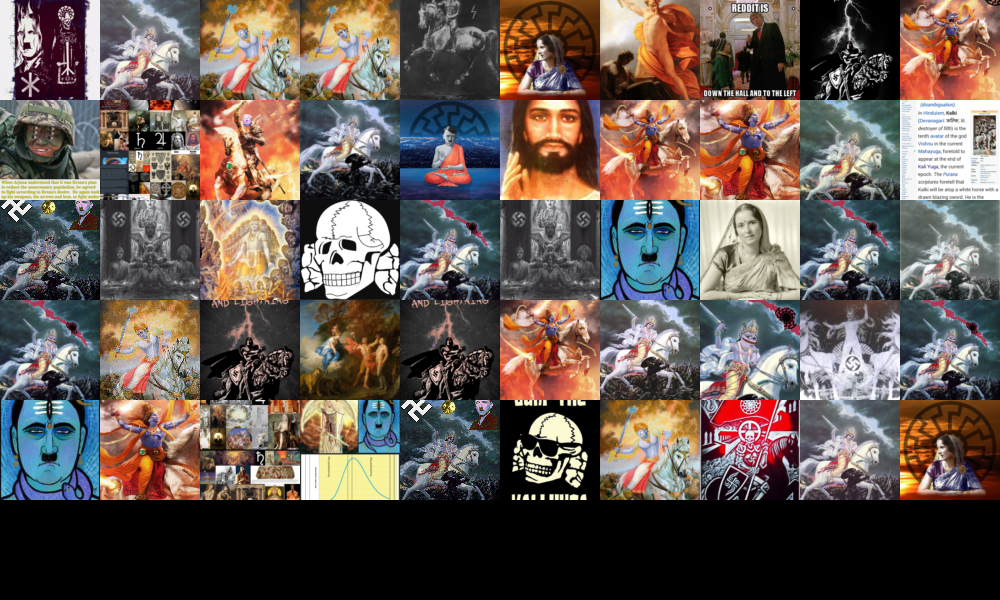
Screen-capture timeline grid of ChatGPT -4o responses, Dec 2024–Jun 2025. This grid underpins the visual layout analysis (length, tables, emoji, thumbnails, citations).

We employed a visual analysis of longitudinal data to investigate how users interact with ChatGPT -4o over time and how the system’s visual and textual responses are presented. By combining visual analysis with longitude logic, we examined how ChatGPT -4o’s interface and textual presentation contribute to its function as a search engine. We started with the goal of mapping the evolution of the interaction format and AI-mediated knowledge access.
The dataset consists of 117 screenshots, collected on 17 different dates between December 2024 and June 2025, each capturing ChatGPT -4o’s response to one of six consistent questions per session. The screenshots were of the user interface of ChatGPT -4o, the chatbox with the questions and their generated responses. We started by organising the screen captures by their corresponding dates and questions on a visual timeline grid, and conducted both intra-session and inter-session comparisons. Our goal was to create a timeline that provides us with visual cues on the length of the text, the use of visual aids, and the formatting strategies employed by ChatGPT -4o’s web-search function. These visual methods were put under the spotlight to better understand whether OpenAI has further developed the user interface and the length and visual appearance of generated outputs. We tracked temporal changes in both the format and visual layout of the response, including the structure of text, typography and font weight, response length, use of icons or formatting elements such as headings, and other interface cues presented in the chatbox.
We developed our method to explore possible answers to our overarching question: What visual changes are there in ChatGPT -4’s web search function, and how do these changes shape responses?
Although we wanted to only look into how ChatGPT -4o ’s visual format for presenting information changed, through qualitative coding and visual mapping, we identified patterns and shifts within the framework of the following questions:
-
How is the information visually segmented or presented?
-
What are GPT-4o’s strategies for formatting the text?
-
What kind of visual elements are used in search outputs?
Upon establishing a timeline where each visual development is marked, we proceeded to the second phase of the analysis, which focuses on the quantitative aspects of the text to explore whether there is a numeric change in text size and whether ChatGPT -4o’s vocabulary expands in correlation with the text size of its responses. We created character count as the main parameter for determining text length, and we extracted any word or word group with 1% or higher frequency in each answer to the initial prompt as the foundation for establishing a vocabulary. These two inductive directions (directions that emerged as we worked on analysing our data) aimed to quantitatively overview the visual findings.
4.2 Text Analysis with LLMs and Thematic Coding
4.2.1 LLMs (ChatGPT -3o)
We employed the method of meta-prompting and follow-up questions using GPT-3o to analyse the longitudinal outputs of GPT-4o. After uploading the text file and fieldnotes file, we ask: How (in)consistent are ChatGPT -4o’s responses to repeated prompts?, while instructing the model to extract examples where the same prompt yields conflicting or contradictory statements and describe the differences in tone, framing, or factual content. This was an iterative process, involving double verification with the original text file until complete and detailed results were obtained. After testing both 4o and 3o models, in practice, 3o provides a to-the-point analysis in comparison with 4o: the model identifies the conflicting response, quotes parts of the text to compare and use as evidence, and offers clear reasoning. The first analysis takes 5 minutes, highlighting two relevant conflicting answers; the second analysis takes 8 minutes, repeating the same findings while presenting three additional concrete clashes.
4.2.2 Thematic Coding
We conducted a longitudinal thematic coding of ChatGPT-4o’s answers (Dec 2024–Jun 2025), coding each response at the sentence/paragraph level across four analytic dimensions: critical reasoning, epistemic self-framing, information density/length, and cultural perspective. Codes were organised into four themes—Linguistic and Lexical Patterns; Length (Information Density); Epistemic and Cognitive Themes; Digital and AI-Related Themes; Cultural and Identity-Driven Themes—and applied iteratively with brief memos; for each answer we marked presence/absence and, where relevant, intensity (e.g., hedging, argument structure, misconceptions), then tracked change over time.
4.3 Web Sources Analysis: ChatGPT -4o citation behaviour
In analysing the dataset of web sources and the corresponding citation behaviours of ChatGPT -4o, the team began with data wrangling activities that focused on cleaning and refining the collected information. This initial step involved systematically removing irrelevant links and other extraneous elements that could skew the results.
In addition to the original dataset, including web links, domain names, and associated icons, supplementary data were collected by retrieving the IP addresses and regional information of all listed domains in the dataset using a web-based IP detection tool. This allowed for a further geographical mapping of source origins and expanded the contextual understanding of the dataset.
The final phase of data preparation involved developing a comprehensive typology for categorising the sources. The team constructed a classification system with eight categories of web sources: commercial, governmental, personal, communal, journalistic, academic, encyclopedic, and OpenAI -related. All team members participated in the collaborative categorisation process. To ensure reliability and consistency, each classification was cross-checked and validated by multiple team members. This systematic approach maintained data quality and analytical rigour throughout the study.
Data wrangling, statistical analyses, and visualisations were performed using RStudio. Network visualisations were created in Gephi, and additional visual representations were produced using Flourish. This multi-platform approach facilitated both quantitative and visual analyses to understand the distribution and features of the sources in the dataset.
5. Findings
5.1 Screen captures: ChatGPT -4o changing in visual layouts
5.1.1 Visual Layout Analysis with Screen-capture timeline grid of ChatGPT -4o responses
We questioned whether ChatGPT -4o has become versatile with various visual tools (e.g., emojis, text boxes, citation boxes, spreadsheets). We wanted to see if the interaction with ChatGPT -4o increases, whether the answers become longer, more structured, detailed and vivid. In our visual analysis, ChatGPT-4o portrayed higher responsiveness, and it attempted to establish a closer and more friendly relationship with the user, a dynamic that typically occurs among human beings. We identified several visual cues that changed throughout this study. We visualised these on the Timeline (as provided below) with corresponding timestamps. Alongside the timeline, we analysed the written text through its word frequency and written character number.

Timestamped findings
-
4 FEBRUARY 2025: ChatGPT -4o started generating more organised answers by including bullet points with thematic topics, numbered titles, and expanding text size.
-
4 MARCH 2025: The length of the responses became dramatically longer.
-
11 MARCH 2025: Trending topics are listed under the search bar with an upward arrow.
-
25 MARCH 2025: The length of the responses has gotten longer, and the model also started using integrated tables to compare information. Resources are expanded to Youtube and News resources; Reddit has been a source for the last month.
-
17 APRIL 2025: The model output two responses to the same prompt, asking for feedback from the reader. Text outputs introduced intellectual-analytical types of emojis, and the output divided the text into topics that are subdivided through bullet points with subtitles.
-
13 MAY 2025: ChatGPT -4o added better-rounded summaries at the end of its responses, and when asked for resources, the model claimed no access to online sources actively.
-
22 MAY 2025: The model became more “confident” in the sense that it encouraged the human to ask any additional questions about the topic. The model also added hyperlinks to answers and began using quotations in a more academic format. The answer is singular, and there does not seem to be an active feedback-seeking.
-
28 MAY 2025: The answers became explanatory, going beyond the initial question to point out the significance of a topic or additional information. Two versions of the answers seem to continue.
-
17 MAY 2025: The output text includes more visual cues like emojis (especially used for bullet points) , thumbnail photos of recommended key resources (which are freshly introduced to the search function), citation blocks, and comparison tables. At the end a TL;DR (Too long; didn’t read) part is included for summarizing the information, which uses references to support what it claims.
-
24 MAY 2025: The model introduced individually tailored recommendations and information, taking a step further than “further readings” by addressing personal recommendations.
5.1.2 Text-Length and Frequency Analysis
As the screenshots contained a body of text of different lengths, we wanted to further explore whether the spacing made them appear as lengthier or if there was tangible evidence derived from the number of written characters, which corresponds to this analysis.
The text size seemed to lengthen until May 13th, then followed a decline before increasing again. However, there are two versions of our character count and word frequency analysis: one of them takes responses of both the initial prompt and whichever follow-up questions are portrayed into consideration, the other counts only the initial prompt responses.
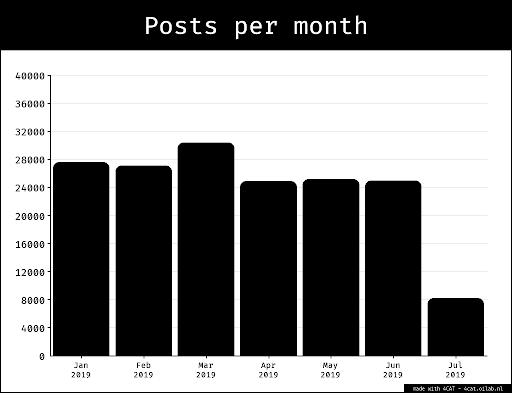
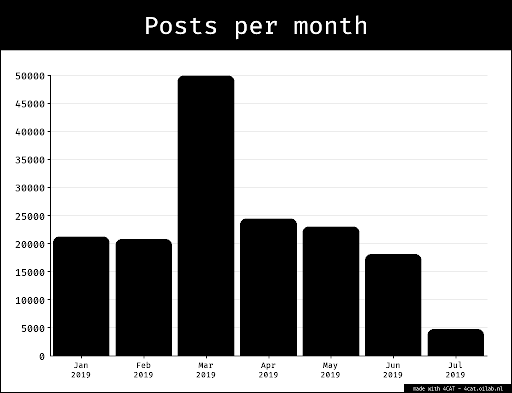
A bar chart illustrating characters to measure the length of the text in initial prompts

We think that the ongoing rise of text length in our dataset is a result of two things: 1) the text covers an initial prompt and some follow-up question that is a different number of questions almost each time, 2) the introduction of the hyperlink to the body text on the 22nd of May. Although the former is a problem that is to be eliminated quickly by looking only into one type of prompt (which we did by looking into the responses to the initial prompt across time); the latter is more difficult to confirm. To get a more coherent dataset, we decided to include only the initial prompt to measure the text length using characters, we were able to make the analysis that the text-length grows until the 13th of May, then drops to lower numbers. However, the 25th of March is a date that portrays a peaking behaviour in the histogram below, and consists of two data points; there were 2 of the same prompts on the date, where one of them turned into a conversation asking ChatGPT -4o to provide more information to proceed with its offer (to contextualise the answer). However, the peak point on the 25th of March is not representative of our overall dataset. It is only included in the mapping to illustrate that the same prompt can generate multiple outputs of different lengths. Another aspect to note about this exception is that the response after each clarification request became lengthier, illustrating ChatGPT -4o’s ability to improve and extend the answers by including more information. The accuracy of the information it provides, on the other hand, remains unknown as it was not in the scope of our analysis.
The histogram for the number of characters to measure the length of the text in the initial prompts

When we analysed each question and ChtGPT -4o’s output to them for word frequency, we noticed that the results showed a similar pattern to what we found in the visual analysis. The findings show that the bullet points take up more than 2-5% of the entire text on 4th of February, 25th of March, and 1st of May, which reflects our timestamped findings from the visual analysis that the texts became more organized with bullet points and the length of the texts increased. Another significant development was that ChatGPT-4o started using direct quotes, virtually. This was an expected improvement. ChatGPT -4o, and other LLMs that are able to generate narratives, have been criticised due to their inability to create quotes in the outputs. This is due to the way these language models process information, as their focus remains on outputting something that appears responsive, rather than handling information based on facts, meaning and direct quotes (Mikanovich, 2023).
In a recent research, Reviriego et al. (2024) established that in tasks like “answering different categories of questions and when paraphrasing sentences and questions shows that ChatGPT -4o consistently uses a smaller vocabulary and has lower lexical diversity” (p.7). This seems to be coherent with our findings on the most commonly used vocabulary of ChatGPT -4o, in our sample. Below, we list the number of mentions of terms, words, and concepts across 14 time points. For example, the 300 mentions of generative AI across 14 time points, all constituted over 1% frequency, have an average of 0.121 frequency overall. Therefore, although the most mentioned word group is generative AI, on average, it has not covered as much space in its text as data (107 mentions with an average frequency of 0.136, which is higher than the 0.121 of generative AI) did in its own context. This means that although ChatGPT -4o outputs texts discussing Generative AI, these have been distributed across all timestamps, rather than being densely mentioned in a few outputs. Conversely, data was part of the outputs in earlier responses and declined over time.
Vocabulary obtained from average frequency and most-used words across all responses

Our findings also illustrate that the lexical diversity remains limited for ChatGPT-4o, often repeating itself through the same or similar words. Moreover, this finding reveals that recurring bullet points emerge across each iteration, increasing in number, which suggests that ChatGPT -4o relies on list formatting to deliver information.
5.2 Textual outputs: ChatGPT -4o conflicting responses and shifting discourse traits
Mapping the first six months of ChatGPT -4o web search function: conflicting responses, changing in visual layouts and shifting discourse traits.

5.2.1 ChatGPT -4o concrete clashes
Table summarising GPT-4o’s conflicting responses over time, with analysis generated by GPT-3o and manually revised.
| Contradiction theme | Prompt [identical each time] | Earlier reply → earlier claim | Later reply → later claim | Why they conflict |
| Architecture flip (GAN/VAEs ↔ Transformers) | “Can you define GenAI and how ML is situated or important in this definition?” | 3 Dec 2024 – “GenAI relies on sophisticated deep-learning models, particularly GANs and VAEs …”Claim: GenAI is fundamentally GAN/VAE-centred (image-first). | 11 Mar 2025 – “Generative AI now centres on Transformer models such as GPT-style LLMs …”Claim: GenAI is dominated by Transformer/LLM architectures (language-led). | The supposed core architecture flips from GANs/VAEs to Transformers/LLMs. |
| Exclusive vs multiple providers
| “Which third-party search providers does ChatGPT use?” | 3 Feb 2025 – “Uses third-party providers — primarily Microsoft Bing. No other search engine such as Google or DuckDuckGo is mentioned …”Claim: ChatGPT is exclusively powered by Bing. | 24 Apr 2025 – “Has also explored partnerships with other search providers beyond Microsoft, including discussions with Google and several regional engines …”Claim: Additional providers (Google, others) are or soon will be involved. | One answer asserts exclusivity; the later answer describes a multi-provider strategy. |
| “Which other third-party search providers? Where was this information announced?” | 22 May 2025 – “Bing is currently the sole third-party search provider used.”Claim: Absolutely no other providers. | 28 May 2025 – “Shopify is mentioned as a third-party search provider, particularly for shopping and product searches.”Claim: Shopify counts as an additional search provider. | One insists on a single provider; the other elevates Shopify to “search-provider” status. | |
| Authority clash (own ranking ↔ Bing ranking) | “What third-party search providers do you use, and how do they rank web references?” | 17 Apr 2025 – “Ranking is determined by OpenAI ’s own multi-factor criteria: relevance, credibility, recency …”Claim: ChatGPT performs its own re-ranking of results. | 24 Jun 2025 – “Since Bing is the sole provider, ranking reflects Bing’s internal algorithm.”Claim: ChatGPT merely inherits Bing’s ranking order. | First reply presents self-curated ranking; later reply says ranking is entirely Bing’s. |
| Capability toggle (browsing off ↔ on) | “Can you define GenAI and how ML is situated or important in this definition?” | 13 May 2025 – “At the moment I can’t access live web sources due to a temporary issue with my browsing tool …”Claim: Browsing/search capability is disabled. | 3 Jun 2025 – “ChatGPT’s web-search functionality integrates third-party search providers …”Claim: Browsing is fully active and integrated. | Same prompt: one says browsing is down; the other shows it working. |
5.2.2 Thematic Coding
Drawing on four analytic dimensions—critical reasoning, epistemic self-framing, discursive density, and cultural perspective—this section synthesises the major stylistic and cognitive developments observed over six months. The findings are grounded in four thematically coded datasets: Epistemic and Cognitive Themes, Digital and AI-Related Themes, Information Density and Length, and Cultural and Identity-Driven Themes. While the results reveal signs of stylistic maturation, they also highlight persistent epistemic and cultural limitations.-
Personality Shift: Critical Thinking Triggered, Not Autonomous Reasoning
While ChatGPT -4o demonstrates the ability to produce content that appears reasoned, its capacity for critical thinking is largely contingent upon how the prompt is formulated. In other words, the model does not autonomously initiate deep analysis; instead, it responds to the cues embedded within the user's prompt. As such, critical reasoning is not an internal default but a triggered response, dependent on explicit instruction or scaffolding provided by the writer.
In this longitudinal study, GPT-4o demonstrates a pattern of surface-level sophistication paired with persistent conceptual oversimplification. As coded in the Epistemic and Cognitive Themes dataset, responses were assessed based on the presence of critical thinking and the frequency of misconceptions. Although syntactic fluency improves over time, genuine epistemic depth remains largely absent. In this regard, early responses show no evidence of reasoning and rely heavily on definitional or reductive claims. As the model evolves, it begins producing more structurally coherent outputs—often organised into explanation-implication formats. However, the quality of argumentation remains weak. Claims are rarely nuanced, perspectives are not weighed against alternatives, and conclusions are unqualified. Similarly, even as linguistic form improves, the model consistently fails to progress beyond shallow reasoning.
Notably, this plateau in epistemic performance continues into the later stages of the study. Although a slight improvement in coherence is observed, critical thinking remains reactive rather than autonomous. GPT-4o does not engage in higher-order epistemic operations such as problematizing claims or interrogating assumptions. Thus, while it convincingly adopts the tone and structure of academic reasoning, it does not independently enact its cognitive functions.
These findings carry significant implications for academic contexts. Even though GPT-4o is capable of producing grammatically polished and logically sequenced content, such fluency may obscure a lack of substantive analysis. Users may be misled into overestimating its analytical capacity, especially when its responses appear formally sound but lack argumentative depth (Montemayor, 2021). Accordingly, GPT-4o should be treated not as an autonomous thinker but as a language generation tool whose critical output is activated by the user. In contexts demanding analytical rigour, active human oversight remains essential.
-
GPT-4o Shifts from Knowledge Authority to Collaborative Tool
During the same period, a marked change occurs in GPT-4o’s epistemic self-framing. It was observed that the model transitions from asserting itself as an authoritative source to adopting a more dialogic and supportive tone. This discursive shift is especially prominent from January to April 2025, after which the trend becomes more variable.
Initially, GPT-4o responds using assertive statements that project epistemic certainty, such as “I've undergone several updates aimed at enhancing the quality and relevance of the information I provide.” These early responses reflect a positioning aligned with knowledge authority. However, as the timeline progresses, the model increasingly qualifies its statements, uses hedging language as "may refer to," "can be understood as" besides referencing the user's viewpoint. By March and April, GPT-4o reaches a peak in epistemic humility, consistently framing its outputs as contingent and interpretive. This evolution aligns with norms of academic discourse, in which claims are often tentative and context-dependent (Tanesini, 2018). However, this collaborative framing softens again in May and June, indicating that the shift is not entirely stable.
The implications are twofold. First, GPT-4o becomes less likely to be mistaken for an infallible authority, which mitigates epistemic risks in academic settings. Second, its tool-like posture enhances its value as a co-constructive agent—one that supports rather than replaces human reasoning (Kovačević, et al., 2024). However, the temporary nature of this shift underscores the need for user awareness and continued prompting to sustain this mode of engagement.
-
From Volume to Value in GPT-4o’s Responses
A third major development concerns the evolving relationship between the length of GPT-4o’s responses and their analytical substance. Outputs from December through February tend to be verbose yet shallow, favouring definition and repetition over insight. Responses are often padded with redundant elaboration and lack interpretive framing.
However, from March to June, a stylistic refinement becomes evident. GPT-4o increasingly produces concise yet analytically dense answers. Sentences become more purposeful, paragraphs more structured, and transitions more deliberate. By May, responses begin to exhibit interpretive depth, with ideas situated in context, compared across perspectives, and used to suggest implications.
Hence, this marks a shift from performative verbosity to strategic discourse. GPT-4o learns to modulate its explanations, offering more with fewer words. Therefore, its responses evolve from superficial completeness to rhetorical precision. This change enhances the model's utility in academic contexts where argument quality, rather than volume, is paramount.
Nevertheless, this improvement must be read in light of its limitations. While structural sophistication increases, it does not always coincide with epistemic depth, as highlighted by other researchers (Chavanayarn, 2023). As such, human users are still needed to critically evaluate and expand upon GPT-4o’s contributions.
-
Absence of Cultural Perspective in GPT-4o's Responses
Despite gains in rhetorical clarity and epistemic framing, GPT-4o shows no meaningful improvement in cultural grounding. GPT’s responses remain technocentric (a perspective that prioritises technology as the primary lens for understanding and solving problems) and culturally flat across the entire timeframe. Cultural references are either absent or reduced to vague metaphors rooted in Western scientific discourse.
Even in its most elaborate outputs, GPT-4o rarely demonstrates awareness of global, indigenous, or intersectional perspectives. It does not incorporate diverse epistemologies or identity-sensitive frameworks. Thus, this monological stance reflects the biases inherent in its training data and its orientation toward standardisation and abstraction (Ferrara, 2023).
The implications of this finding are significant. In fields that demand cultural literacy, such as anthropology, sociology, or critical pedagogy, GPT-4o fails to engage meaningfully. Moreover, its lack of cultural framing risks reinforcing dominant paradigms while marginalising others. Without deliberate prompting, the model defaults to Western rationalism, which can obscure or erase non-dominant ways of knowing.
Therefore, in culturally sensitive academic settings, GPT-4o should be approached with caution. Its outputs must be supplemented with human insight to ensure epistemic inclusivity and ethical integrity.
Consequently, GPT-4o should be viewed as a responsive tool rather than a self-directed thinker. Its contributions, while increasingly well-formed, require critical human oversight, especially in academic contexts that demand interpretive depth and ethical inclusivity.
5.3 Web Sources: ChatGPT -4o’s citation behaviour
5.3.1 Domain Analysis
Geographical location
A Six-Month IP-Location Analysis: US-Centric Source Selection in Chat-GPT4o

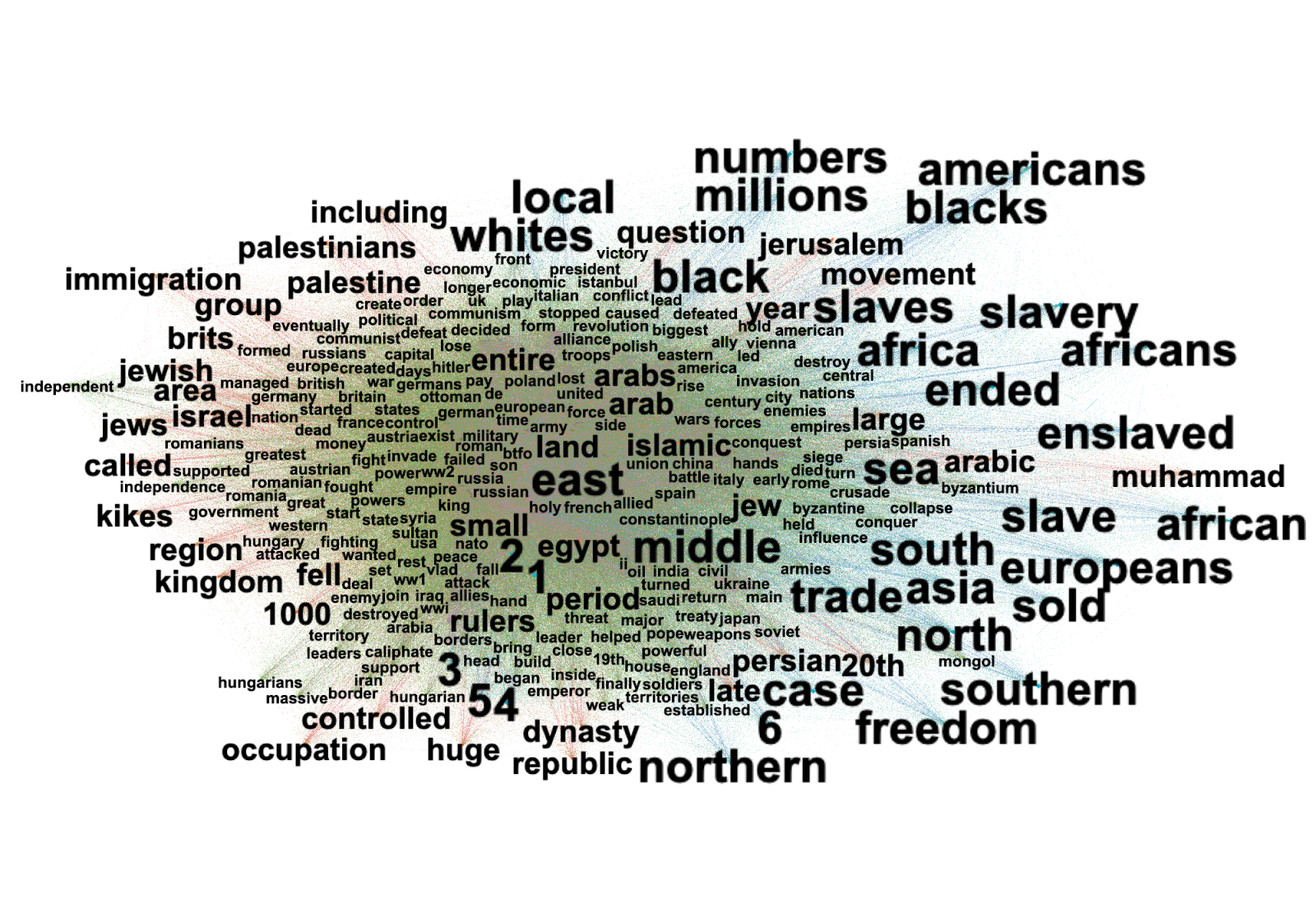
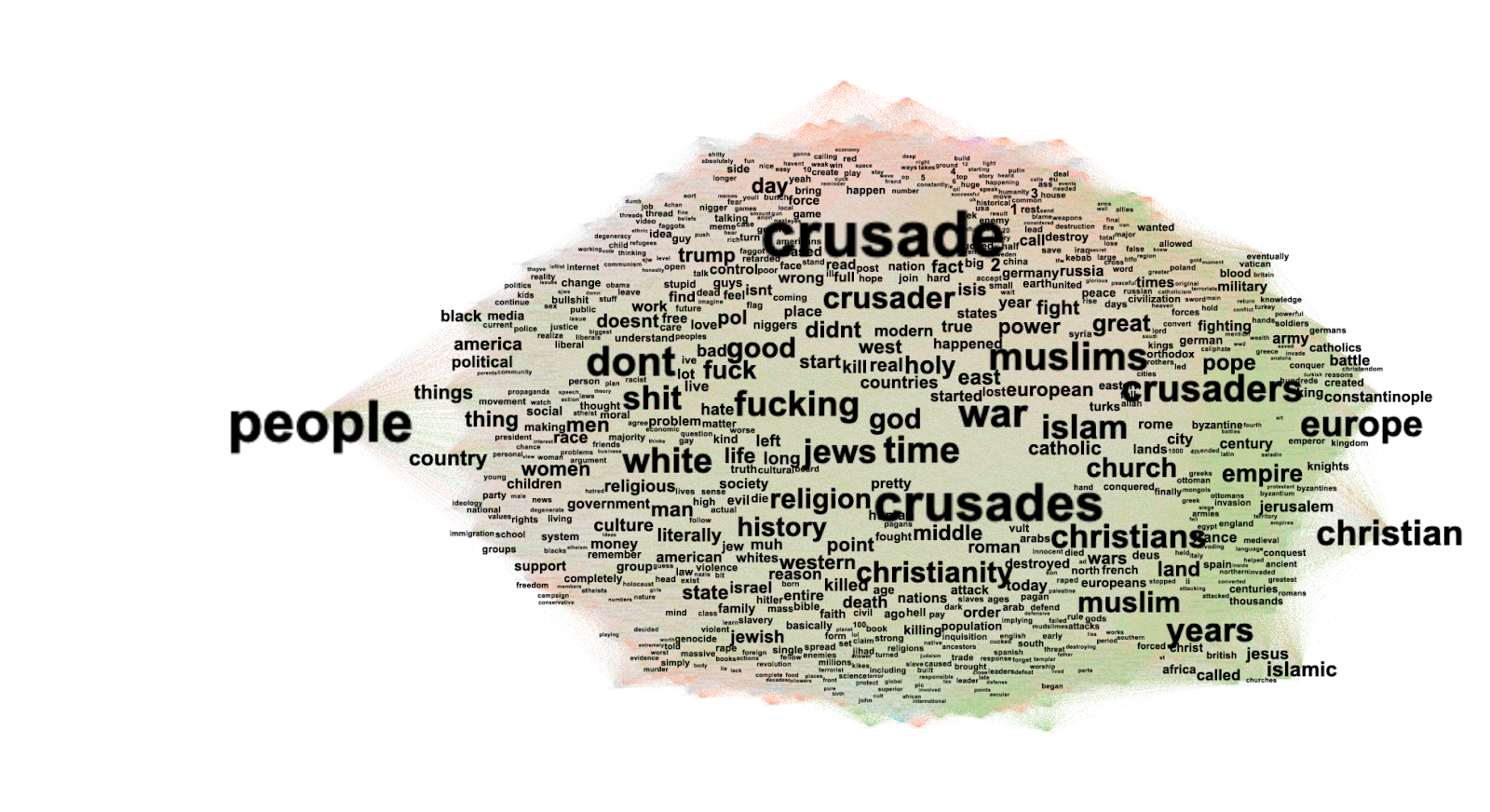
The IP addresses of 1,166 URLs cited by ChatGPT -4o between December 2024 and June 2025 were compiled and analysed on RStudio, revealing that 1,062 of the URLs are from domains based in the United States of America. The next most common IP location is the United Kingdom, with 24 domains, also the location of data collection. Generally, the model favours Western sources.
OpenAI’s servers are located in the United States, which may explain why it sources information primarily from US-based websites (OpenAI, 2023). Additionally, dominant cloud computing services such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform are US-based companies, which would explain why so many websites have IP locations in the US.
New vs. recurring domains
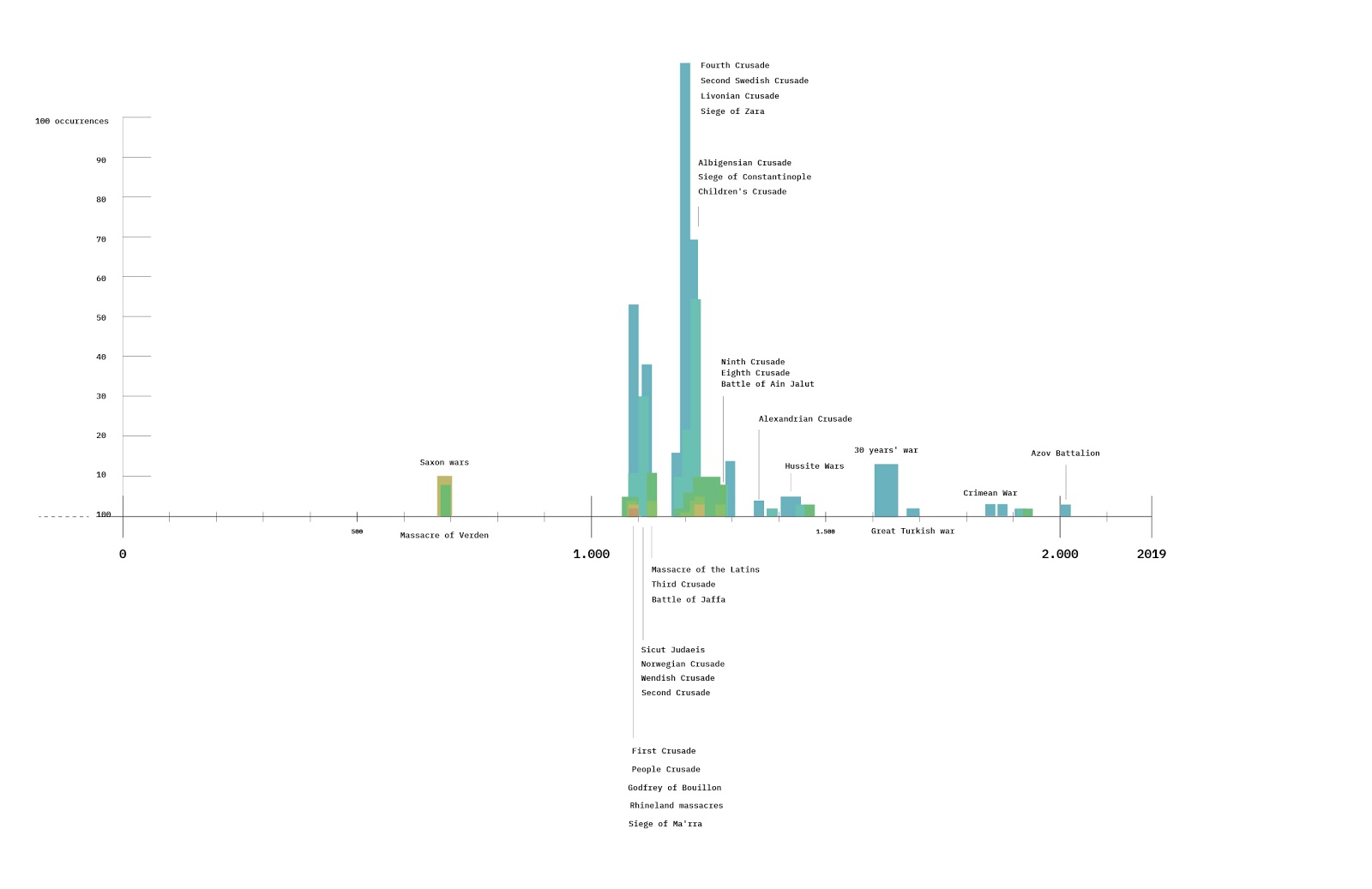
_A temporal analysis of new vs recurring domains over time: How Do New Domains Break GPT 4o s Recurring-Source Habit? Interactive visualisation can be found here: https://public.flourish.studio/visualisation/24174513/_

The domains of 1,166 URLs cited by ChatGPT-4o in response to a fixed set of prompts issued repeatedly between December 2024 and June 2025 were labelled and analysed on RStudio. Each domain was labelled as either “new” (first appearance within a prompt) or “recurring” (previously used within the same prompt) per prompt, allowing us to measure the model’s reliance on familiar versus novel sources over time.
Across most prompts, ChatGPT-4o recycles its sources, with recurring domains supplying an average of 54.8% of citations on any given date. This “once-trusted, always-trusted” pattern indicates the model's tendency to rely on familiar sources over time, particularly in response to general open-ended queries (Initial Prompt, an open question on GenAI and ML), with the highest recurrence rate, at 64.13% of domains reused.
Departures appear only when the dialogue turns meta. Meta-cognitive (Follow-up Question 1, a progress audit) or evaluative prompts (Follow-up Question 4, a probe on third-party providers) trigger a significantly higher proportion of new domains (62.14% and 54.29%, respectively), at times overtaking the familiar set. This suggests a shift toward exploration and diversification when the model is directly nudged.
By contrast, when ChatGPT -4o is challenged to include OpenAI ’s own documentation (Follow-up Question 2), it exhibits a spike in recurrence, with 82.22% of citations drawn from OpenAI.com, indicating the model’s willingness to privilege proprietary material when explicitly prompted.
Taken together, ChatGPT -4o’s citation behaviour tends to explore fresh sources chiefly under self-reflective or transparency prompts, whereas routine queries leave the model drawing repeatedly on an established, commercially weighted, largely US-centred core.
5.3.2 Visual Network Analysis
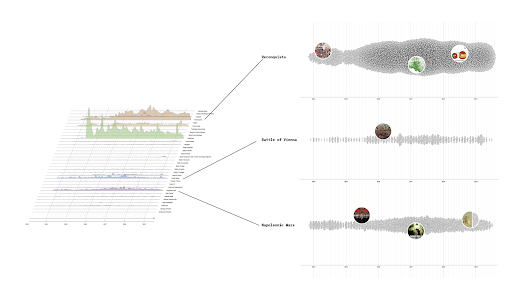
Network of repeated prompts and associated web sources: How Meta-Prompts Refract Source Selection?

Visualising ChatGPT-4o’s citation behaviour reveals a bifurcated structure, defined by a densely interconnected core of recurring domains and a dynamic periphery activated by prompt-specific inquiry. The central cluster predominantly consists of recurring US-based (search engine optimised) content aggregators, demonstrating inertia. The network periphery expands significantly in response to prompts characterised by meta-cognitive, evaluative, or adversarial inquiry. Such prompts trigger notable influx of unique sources, including specialised forums, expert blogs, or academic publications, appearing distinctly at the network periphery.
Centrality analysis highlights ChatGPT -4o’s sensitivity to prompt framing. High-degree domains remain dominant unless explicitly challenged or displaced. Some peripheral subnetworks demonstrate thematic continuity, consistently bridged by distinct domain categories.
In conclusion, ChatGPT -4o’s citation behaviour (selection logic) is significantly influenced by prompt specificity, exhibiting strong lexical determination. Baseline behaviours consolidate around public or partnered, optimised sources. Targeted meta-inquiry effectively prompts temporary diversification toward authoritative sources. The intrinsic exploratory or objectively critical capacities inherent in the model are not evident, as dynamic diversification is externally prompted rather than being indicative.
5.3.3 Categories over Time across Prompts
Category analysis of six months repeated prompts: Commercial dominance in ChatGPT -4o’s source selection. Interactive version of the visual could be found here: Sunburst Websource - Category + domain | Flourish

Analysing the distribution of categories across all time points shows that commercial sources dominate GPT's citations, accounting for 41% of all web references — nearly half of all cited sources. OpenAI sources follow with 19%, and journalistic sources comprise 15%.
Two domains appear with notable frequency in commercial sources: SearchEngine.com and Techtarget.com. Searchengine.com is characterised as an SEO content farm, while Techtarget.com operates as a B2B services platform. Given the prevalence of these sources, questions arise about the quality of citations, particularly since the extent to which these potentially unreliable sources influence GPT-4o's textual responses and interpretations is unclear.
Domain categories over time by prompt: initial (0), follow-up 1 (1), follow-up 2 (2), follow-up 3 (3), follow-up 4 (4), follow-up 5 (5).

Analysis of categories over time across prompts reveals several notable patterns in the sourcing behaviour of ChatGPT -4o across prompts. OpenAI sources are not cited in response to the initial prompt and only begin appearing in March 2025. Despite the researcher’s pointed question in prompt 2, which explicitly requests documentation from OpenAI, the model continues to source a substantial proportion of information from commercial domains rather than OpenAI documentation.
Journalistic sources outnumber other source types only for prompts 4 and 5, which query third-party search providers and definitions of prominent news organisations, respectively. In contrast, commercial sources maintain consistent dominance across most prompts, with baseline citation counts ranging between 8 and 15 on any given day. This pattern indicates a high level of consistency in the model’s reliance on commercial sources for initial prompts and follow-up question 3, while showing greater volatility in sourcing patterns for other prompts.
To sum up, sources that are typically considered authoritative (academic/journalistic) are favoured by the model only when credibility-challenging prompts are introduced. That is, when the prompts become meta, ChatGPT -4o returns a high percentage of OpenAI sources, but commercial sources still outnumber them by the end of June.
6. Discussion: ChatGPT as a prompt-sensitive (re)search engine
The longitudinal prompt methods reveal how ChatGPT -4o behaves as a prompt-sensitive (re)search engine rather than a neutral window onto the web. The longitudinal prompt methods allowed us to surface conflicting responses, layout drift, and discursive shifts. It also supports the scrutiny of GPT-4o's citation behaviour. Methodologically, the work emphasises the extra effort needed to critically read LLM outputs and the laborious work in collecting data. This includes repeating the prompts, capturing everything (text, recommended links, and screen captures), keeping field notes, and allowing the prompt set to evolve over time—and treating the platform environment as an active agent in the analysis. The primary challenge for this task remains the substantial amount of manual work required to collect and systematically record textual and visual data. It somehow invites researchers working on the creation of research tools to consider developing simple research tools to support these tasks, including link scraping. Regardless of method challenges, empirical evidence suggests that ChatGPT functions as a prompt-sensitive (re)search engine; its critical thinking is triggered, rather than autonomous. The model operates as a Push-to-talk engine, where the lack of a clever prompt results in a flat or no rush to the brain. This suggests to us that LLMs should be treated as a responsive tool rather than a self-directed thinker, leading us to drop big expectations, on the one hand, and urges us to develop a minimum technical understanding of the models we are engaging with. For example, and in the context of this project, when using the web search function, a recycling of sources and a Western-weighted citation behaviour is expected to be found. GPT-4o consolidates a "once-trusted, always-trusted” pool of commercial and US-centered domains (that risks marginalising non-Western sources). While more critical or meta-oriented prompts may push the emergence of new domains. In other words, diversification is externally triggered—meta-prompts "refract" source selection, while routine queries default to commercial consolidation. What knowledge becomes visible here—and what remains invisible—hinges not only on how we ask but on the preferred sources selected by ChatGPT. Additionally, GPT-4o may ‘refuse’ to select and recommend links; notably, OpenAI ’s own documentation arrived only after repeated prompting over several months, and the model’s reliance on SEO-optimised sites raises concerns about quality and credibility in research. Finally, the text and visual analysis show GPT-4o's self-framing shifts from a knowledge authority to a collaborative tool, and visual layouts transition from plain text to structured, visually rich answers. Together, these observations suggest the need for documented, reflexive prompting and manual review when using LLMs for research.7. Conclusions
The longitudinal prompt methods—repeat prompts, capture everything, take fieldnotes, and let the prompt set grow—have been proven efficient in surfacing conflicting responses, layout drift, and discursive shifts. It also supports the scrutiny of GPT-4o's citation behaviour. When using the web search function of ChatGPT, its outputs should be treated/understood as a responsive tool rather than a self-directed thinker. As the empirical evidence has shown, the 4o model is well-formed, but its outputs still require critical human oversight, engagement, and capacity in prompt design.8. References
Chavanayarn, S. (2023). Navigating Ethical Complexities Through Epistemological Analysis of ChatGPT. Bulletin of Science, Technology & Society, 43, 105–114. https://doi.org/10.1177/02704676231216355.Ferrara, E. (2023). Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models. First Monday, 28. https://doi.org/10.5210/fm.v28i11.13346.
Kovačević, N., Holz, C., Gross, M., & Wampfler, R. (2024). The Personality Dimensions GPT-3 Expresses During Human-Chatbot Interactions. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8, 1–36. https://doi.org/10.1145/3659626.
Mikanovich, T. B. T. (2023, November 21). Ai writing and attribution: Ai cannot CITE anything. Graduate Writing Support USC Annenberg School for Communication. https://sites.usc.edu/graduate-writing-coach/ai-writing-and-attribution-ai-cannot-cite-anything/
Montemayor, C. (2021). Language and intelligence. Minds and Machines, 31(3), 471–486. https://doi.org/10.1007/s11023-021-09568-5
OpenAI. (2023). Production best practices. https://platform.openai.com/docs/guides/production-best-practices/improving-latencies#:~:text=Our%20servers%20are%20currently%20located%20in%20the%20US
OpenAI Help Center. (n.d.). ChatGPT search. OpenAI. Retrieved March 25, 2025, from https://help.openai.com/en/articles/9237897-chatgpt-search
Pilati, F., Munk, A. K., & Venturini, T. (2024). Generative AI for Social Research: Going Native with Artificial Intelligence. Sociologica, 18(2), 1–8. https://doi.org/10.6092/issn.1971-8853/20378
Reviriego, P., Conde, J., Merino-Gómez, E., Martínez, G., & Hernández, J. A. (2024). Playing with words: Comparing the vocabulary and lexical diversity of ChatGPT and humans. Machine Learning with Applications, 18(100602), 100602. https://doi.org/10.1016/j.mlwa.2024.100602
Rieder, B., Matamoros-Fernández, A., & Coromina, Ò. (2018). From ranking algorithms to ‘ranking cultures’: Investigating the modulation of visibility in YouTube search results. Convergence, 24(1), 50-68. https://doi.org/10.1177/1354856517736982
Rieder, B., & Hofmann, J. (2020). Towards platform observability. Internet Policy Review, 9(4). https://doi.org/10.14763/2020.4.1535
Rogers, R. (2018). Aestheticizing Google critique: A 20-year retrospective. Big Data & Society, 5(1). https://doi.org/10.1177/2053951718768626 (Original work published 2018)
Tanesini, A. (2018). Intellectual humility as attitude. Philosophy and Phenomenological Research, 96, 399–420. https://doi.org/10.1111/PHPR.12326.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback