You are here: Foswiki>Dmi Web>ToolDatabase>ToolTimestamp (18 Jun 2013, ErikBorra)Edit Attach
Timestamp Ripper
Rips and displays a web page's last modification date (using the page's HTML header). Beware of dynamically generated pages, where the date stamps will be the time of retrieval.

Instructions
Enter a list of URLs. The input box works the same as the Issuecrawler harvester: dump text and the URLs are fetched out. Note only http:// and www. URLs are recognized. Launch the tool and the script retrieves timestamps for URLs inputted.
Sample project
Open Google.com. Set Google Preferences to: 'Number of results: display 100 results per page'. Save preferences.
Query Google.com for site:.gov.ig. Scroll down to the bottom of the results page. To check the number of available results, click results page 10. Here one notes whether there are 1000 results available (the maximum served by Google Web search) or fewer.
Copy and paste all 10 pages of results in a file and save the file. Input the text in the Harvester. Select 'Only return hosts' and 'Only return uniques.' Launch Harvester. Copy paste the result in a file and clean up the list for URLs that are aberrant, i.e. URLs that are not .gov.iq. For a more exhaustive list, please also query Google for inurl:.gov.iq and just .gov.iq. Repeat data cleaning procedure as above, where duplicates and non-Iraqi URLs are removed.
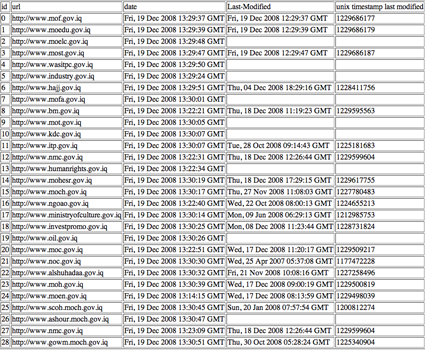
Enter the URL list in the timestamp ripper and launch the tool.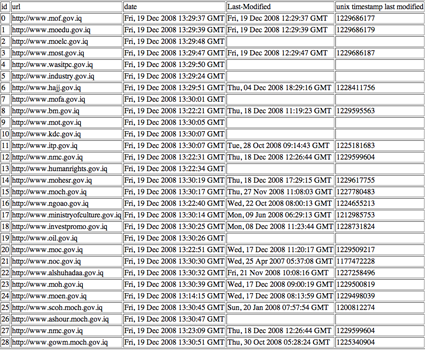
One notes the different levels of attention paid to the governmental sites. Whereas certain sites are 'fresh', most likely through the use of dynamically generated content, other Iraqi governmental sites are stale, with page timestamps up to a year and a half old.
Take care also to visit the front pages of the Websites under analysis, and check their status. In the example of the Iraqi Web, the oldest homepage, noc.gov.iq (the North Oil Company) is a splash page, where the user chooses English or Arabic. The English and Arabic front-pages have these URLs, respectively: http://www.noc.gov.iq/english_ver/homepage_en.htm and http://www.noc.gov.iq/arabic_vr/hompage_ar.htm. Entering those two pages into the timestamp ripper shows that the Arabic page is fresher (4 November 2008) than the English (24 September 2008), and that overall both pages are 1-2 months old.
Enter the URL list in the timestamp ripper and launch the tool.
One notes the different levels of attention paid to the governmental sites. Whereas certain sites are 'fresh', most likely through the use of dynamically generated content, other Iraqi governmental sites are stale, with page timestamps up to a year and a half old.
Take care also to visit the front pages of the Websites under analysis, and check their status. In the example of the Iraqi Web, the oldest homepage, noc.gov.iq (the North Oil Company) is a splash page, where the user chooses English or Arabic. The English and Arabic front-pages have these URLs, respectively: http://www.noc.gov.iq/english_ver/homepage_en.htm and http://www.noc.gov.iq/arabic_vr/hompage_ar.htm. Entering those two pages into the timestamp ripper shows that the Arabic page is fresher (4 November 2008) than the English (24 September 2008), and that overall both pages are 1-2 months old.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
iraqi_north_oil_company_timestamps_19Dec2008.png | manage | 25 K | 19 Dec 2008 - 14:13 | EstherWeltevrede | |
| |
timestamp.png | manage | 25 K | 19 Dec 2008 - 13:54 | EstherWeltevrede | |
| |
timestampripper_sample_19Dec2008.png | manage | 175 K | 19 Dec 2008 - 14:08 | EstherWeltevrede |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r5 < r4 < r3 < r2 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r5 - 18 Jun 2013, ErikBorra
Ideas, requests, problems regarding Foswiki? Send feedback