🌊 ☀️ 🇺🇳 Culture-policy climate spaces of COP28: multimodal cross-platform analysis in TikTok, Instagram and Twitter (X)
Team Members
Warren Pearce, Janna Joceli Omena, Yuting Yao, Carolin Schwegler, Jasmijn Visser, Leyla Rommel, Jöran LandschoffContent
1. Introduction
This project uses a range of experimental and established digital methods to investigate policy and cultural spaces of climate change on TikTok, Instagram and Twitter during the COP28 talks in Dubai, 2023. Our aim is to discover how image and text are used together to co-construct these spaces.
Previous research has made important advances in multimodal social media research. For example, Tuters and Willaert (2022) investigate the use of image and text in conspiracy spaces on Instagram, arguing that Instagram analysis should include the text from posts in addition to images. This treats images and text as separate corpora, providing important insights into the visual and textual vernaculars associated with conspiracy. We develop this approach further by analysing how image and text are used together to form climate vernaculars across the three platforms (Pearce et al., 2020).
Our research questions are as follows:
-
Who were the most visible and active unique users within culture-policy climate spaces across TikTok, Instagram and Twitter/X?
-
Did COP28 prompt distinctive image-text vernaculars across the three platforms?
-
How can computer vision and corpus linguistic methods be used to provide different perspectives on image-text combinations within social media posts?
2. Initial Datasets
We collected data for five search queries (climate change, netzero, COP28, antinatalism, veganism) across TikTok, Instagram and Twitter (X). Data was collected every day for nineteen days over the course of the COP28 negotiations in Dubai (27 November 2023 - 15 December 2023). The motivation for these search queries was not only to study the keywords/hashtags most directly associated with the COP talks (policy spaces), but also to study parallel ‘climate solutions’ (cultural spaces) as points of comparison and potential convergence.
Data was collected daily from each platform using Zeeschuimer (Peeters, 2023) and 4CAT (Peeters and Hagen, 2021). New accounts were created on each platform to minimise platform personalisation effects. The same account was used on each platform throughout the data collection process. This produced 15 data collections each day (five search queries, three platforms), and a total of 285 different datasets over 19 days. On each day, 4CAT was used to download the images associated with the posts, as image URLs on TikTok and Instagram are only functional for a limited time before expiring (the image files were saved for the purpose of image network mapping). We merged these 285 separate datasets into three datasets. For each platform, we copied all rows into a new spreadsheet, adding new columns for the ‘seed’ search query and the date of the data collection.
The removal of duplicates then emerged as the crucial and final task for building up the datasets. The repetition of posts on different days for the same search query may indicate an artefact of platform recommendation algorithms learning from a persistent focus on a limited set of search queries. To mitigate the influence of such repetitive content, we opted to eliminate duplicate posts within each dataset originating from distinct search queries. For this particular project, we opted to remove duplicates as the focus is on the multimodal (image-text) co-production of climate vernaculars, rather than the prominence of specific posts through search algorithms. This constitutes a more issue-centric view. Future projects using the same original datasets may adopt a more platform-centric view, where the repeated recommendation of posts in search results assumes greater importance, for example, in the ‘ranking cultures’ approach (Rieder et al., 2018).
3. Research Questions
- Who were the most visible and active unique users within culture-policy climate spaces across TikTok , Instagram and Twitter/X?
-
Did COP28 prompt distinctive image-text vernaculars across the three platforms?
-
How can computer vision and corpus linguistic methods be used to provide different perspectives on image-text combinations within social media posts?
4. Methodology
We have designed two complementary approaches for this project, utilising three separate digital methods (see Figure 1). The first approach(Method 1)_ focuses on the specificity of prominent users and posts and is complemented by Methods 2 and 3 which look for wider patterns of image and text usage in the five issue spaces we are interested in. Second, we experimented with methods 2 and 3 to complement each other by using two ways of mapping the image and text relations at scale across all the posts collected. In so doing, we seek to minimise the interpretative gap between text and image in digital methods research.
For the first research question, we aim to offer insights into: who is influential in different issue spaces and/or platforms (individuals, organisations, types of actors); and what kinds of images and text these actors are using within the different issue spaces and/or platforms? By locating individual influential authors, who are usually associated with the most engaged posts, this approach can provide resources for us to focus on the prominence of specific vernaculars debated on these platforms. While the other two methods can reveal collective patterns on the three platforms, they, to some extent, divorce users’ meaningful involvement in the discussion by treating every post equally, no matter how influential it is, as a single node.
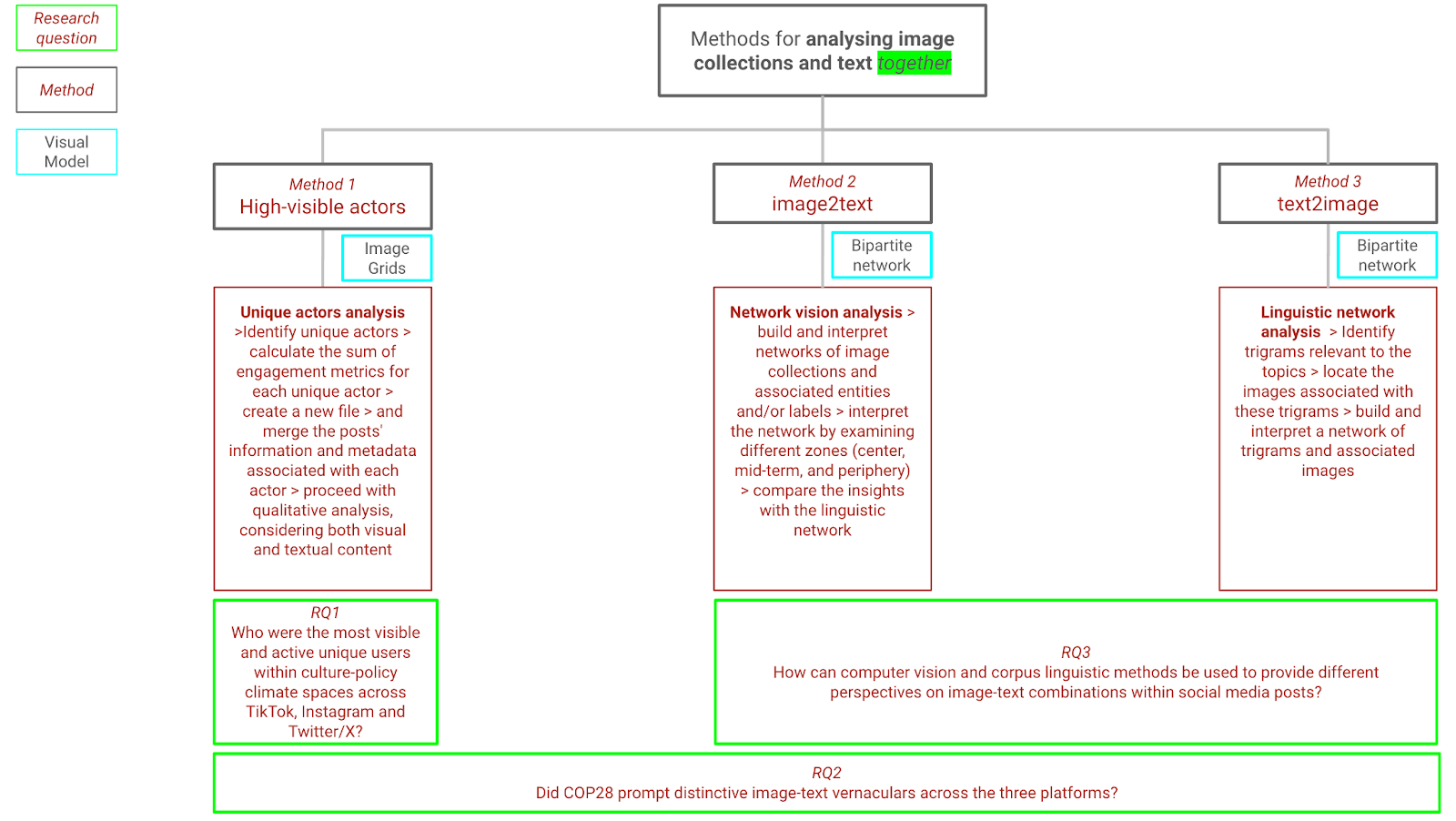
Method 1: High-visible actors
We identified unique actors on each platform, calculated engagement metrics per actor, and associated the related content (Omena, Rabello, & Mintz, 2020). We employ metrics pertaining to post frequency and aggregated user engagement to identify actors exhibiting high visibility within these five issue spaces. Specifically, for Instagram, the aggregate user engagement involves the cumulative ‘likes’ and ‘comments’ of the post(s) from an actor. In the case of TikTok, the engagement encompasses the sum of ‘likes’, ‘comments’, and ‘shares’; and Twitter engagement aggregates ‘retweets’, ‘replies’, ‘likes’, and ‘quotes’. ‘Plays’ on TikTok and ‘impressions’ on Twitter are excluded as they are considered to be feeds pushed to users, in contrast to the others that capture users’ proactive engagements.
Methods 2 and 3: Image to Text and Text to Image
For the second and third research questions, we adopt a ‘close-to-user’ perspective at scale through a combination of digital and linguistic methods by analysing image and text together, as they appear within social media posts seen by platform users, rather than as separate corpora. This novel approach has allowed us to define topics that go beyond search queries.
First, we approach image to text, employing network vision analysis to identify patterns of image usage. To do this, we adopted two separate AI techniques from Google Vision:
1. Machine Learning Vision: using label descriptions to analyse image content ‘within the frame’ 2. Web Detection Algorithms: using web entities to analyse web-derived knowledge of image context. In these approaches, the primary way into the dataset is to first cluster images according to their properties and web semantic context (either labels/content or web entities/context). Once image clusters are identified, we can then locate the corresponding text content for these specific clusters, thereby contextualizing groups of images through both their visual and text elements. Due to time constraints, our analysis was confined to cluster identification and analysis. Second, we approach text to image, identifying linguistic elements called trigrams which are linguistically relevant to the topics. When locating the images associated with these trigrams through network visualisation, we found some images which were relevant to more than one topic, and some were distinctive to one topic. The text to image approach facilitates a more issue-focused approach which partially overcomes the distractions provided by the platform affordances from the issue under investigation. In this approach, the primary way into the dataset is through the text used in the posts, identifying linguistic material commonly associated with each search query, and then linking these to image use. We propose to correlate images found in social media posts with the linguistic specifics of the texts accompanying those images. In other words, the question is whether or not various images are co-posted with similar linguistic elements and how similarities between images can be extrapolated in this way. To do this, the text ‘body’ of the data as we have named this aspect of the dataset is investigated using corpus linguistic methods to detect linguistic specificity. A linguistic dataset (corpus) was created for each platform (TikTok, Instagram, and Twitter/X), and sub-corpora were built for each topic (search queries) within each corpus (climate change, netzero, COP28, antinatalism, veganism). In this way, corpora and subcorpora can be compared to one another to identify the linguistic elements that are specific to each of these topics in our data. Rather simple linguistic methods are used as this is a first attempt to combine visual and linguistic analysis. Linguistic units selected for analysis are unigrams and trigrams, the first referring to words that are specific to a (sub-)corpus in comparison with another corpus, the latter to units of three words that co-occur in adjacency in the same text. Both were calculated for each topic for each platform, resulting in specific uni- and trigrams for each topic on Instagram, TikTok and Twitter, respectively. For both uni- and trigrams, the linguistic category of ‘lemma’ was used to count words such as be, being, was, and are as instances of the same linguistic phenomenon. To illustrate: was at COP28 and are at COP28 are instances of the same trigram be at COP28 in terms of the analysis. The unigrams are not used as markers for the image-text-network but rather provide information for detecting significant trigrams for a particular topic within a platform. The final objective is thus to compile a set of trigrams that mark specificity for a certain topic (or multiple topics) and can thus link the occurrence of such a trigram to said topics. To attain this set of trigrams, the texts were analysed with the corpus workbench (CWB) and tagged for parts of speech (pos) and lemmas using the Python NLP library Stanza. CWB provides powerful but simple options to search for specific collocations of words using the query processor CQP. Complex search queries can be constructed to set conditions for the context in which a specific linguistic item is to be found. For example, it would be possible to search for occurrences of the word ‘netzero’ while the sequence of words ‘at the climate conference’ is also present in the same text, the same paragraph, or the same sentence. Additionally, another restriction such as the occurrence of any verb before ‘netzero’ could be set. As stated above, rather simple queries are used for this study. The condition for the query of trigrams was that three words occur directly adjacent to one another while punctuation marks and emojis were disregarded. The queries were used in each platform’s subcorpus for each topic. In the next step, the results of these queries provided by CQP were exported counting each instance of the same parts of speech occurring as a trigram. In other words, any time a trigram consists of three nouns co-occurring, this is counted as one instance of the trigram ‘NN NN NN’. Thus, a frequency table of pos-tag-based trigrams was created for each topic for each platform. For the topic climate change on Twitter, the first five entries of that table are:| Trigram | Frequency |
| IN DT NN | 1572 |
| DT NN IN | 1410 |
| IN NN NN | 1390 |
| DT JJ NN | 1310 |
| NN IN NN | 1220 |
Table 1. Frequency table of pos-tag-based trigrams (example: first five entries from climate change on Twitter)
In the next step, the ten most frequent of those pos-tag-based trigrams were searched for individually again in the same corpus, this time counting their occurrence not based on part of speech, but on the category of lemma. The first five entries of that frequency table for the first trigram “IN DT NN” in the above table are:
| Trigram | Frequency |
| 90 | of the word |
| 63 | around the world |
| 62 | in the world |
| 46 | of the climate |
| 27 | at the forefront |
Table 2. First five entries of the frequency table for the first trigram “IN DT NN”
In the same way, the frequency of unigrams was calculated based on lemma. Their specificity for a certain topic was then determined by calculating the relative frequency of that unigram in the topic-based subcorpus compared to the frequency of that unigram in the whole corpus. Hence, what is called the ‘keyness’ of single words was calculated in regard to the topics in each social media corpus. These were used to manually identify key trigrams from the frequency tables from the previous analysis step.
Lastly, the thus identified trigrams were listed in a table, referencing key linguistic units for each topic on each platform. For each linguistic unit (=trigram), the text IDs of the texts in which these units occur were retrieved from the corpus and connected to the image IDs of the images posted along with those texts. This allows the creation of an edges table for a bipartite graph showing image ID nodes and topic nodes because the linguistic units can be linked to the topic(s) they are specific for on the one hand and to text IDs and their corresponding image IDs on the other.
| Topic | Platform | Trigrams |
| antinatalism | | Trigram1, trigram5, trigram10, trigram15, … |
| | Trigram4, … | |
| Tiktok | Trigram 15, … | |
| COP28 | | Trigram3, trigram10, trigram18, trigram11, trigram13 … |
| | Trigram 1, … | |
| Tiktok | Trigram19, … | |
| veganism | | Trigram2, trigram4, trigram6, trigram18, trigram12, … |
| | Trigram5, … | |
| Tiktok | Trigram8,... | |
| netzero | | Trigram1, trigram2, trigram7, trigram9, … |
| | trigram11,... | |
| Tiktok | trigram17,... | |
| Climate change | | Trigram2, trigram3, trigram4, trigram8, trigram10, … |
| | Trigram2, … | |
| Tiktok | Trigram1, … |
Table 3. Topics and corresponding specific trigrams (example data)
| Source (image ID) | Target (topic) |
| ID1 | antinatalism |
| ID1 | netzero |
| ID2 | Climate change |
| ID2 | veganism |
| ID2 | netzero |
| ID3 | antinatalism |
| ID3 | COP28 |
| … | … |
Table 4. Edges table for corpus linguistic-based image-topic-network (examples)
The text-to-image (Linguistic Topic-Image-Graph) network should, therefore be read following the below rules:
-
network shows two kinds of nodes: images and topics (‘CC’, ‘NZ’, ‘COP’, ‘AN’, ‘VG’)
-
each edge between an image and a topic indicates that linguistic material used as co-text for that image is highly frequently used for all posts on that topic
-
images connected to several topics (‘CC’, ‘NZ’, ‘COP’, ‘AN’, ‘VG’) thus indicate
-
If you are curating a dataset over time, you will get repetition of posts. These duplicates need to be deleted during curation because they are artefacts of the recommendation system.
-
Twitter (in particular) and TikTok may include posts that are adverts. If this is not the focus of the research, then this can be a challenge.
-
High visible actors according to engagement metrics. TikTok appears to be more likely than Twitter or IG to include viral videos in search results which are unrelated to the original search query, although these videos may not be high up the rankings. This may particularly be the case when the issue space is not a widespread one on TikTok. Therefore, the analysis of high-engagement actors needs to be interpreted carefully, because they may be dominated by the actors responsible for unrelated high-engagement videos.
-
TikTok may also misread the captions of the posts (e.g. A post with ‘28mph’ and ‘#COPS#’ in the video caption came into the search results of COP28).
5. Findings
5.1 High-visible actors
We have identified the top 10 high-visible actors for the five issue spaces on three platforms by ranking the sum of the engagement metrics of the unique post(s) associated with the unique user. These actors and their posts are then investigated qualitatively from both image and text perspectives.

Figure 2. Cross-platform analysis of unique high-visible actors
Climate change
IG: both positive and negative news about climate change, prominence of political aesthetics (Modi & Meloni image), scientific graphs about climate change;
TT: mostly occupied by climate activists with clips about their activities;
TW: very much a political space featured with world politicians and climate NGOs. We also see climate sceptics active in this domain.
Netzero
IG: very prominently shows three authors post only wooden/timer houses. This cottage-core vernacular is not only highly engaged but also evident conceptually and quantitively in the visual and linguistics networks we will show later. Others feature policy updates/explanations and critics of the government’s lack of response;
TT: most posts are viral and irrelevant to this topic, which tells a fact that Netzero is not a very engaged topic on TikTok and data collection on those topics beyond a certain number of posts is very likely to include some unrelated ones;
TW: most authors are associated with climate scepticism (some featuring graphs and pictures); King Charles’ speech at COP28 is also featured here.
COP28
IG: prominence of political aesthetics (Modi & Meloni image; group shot of leaders; King Charles);
TT: sweetening the pot with distractions (prominence of irrelevant viral videos; also see methodological challenges above);
TW: prominence again of Modi and Meloni. It is important to note the central role of Modi in international climate politics; and that many world leaders did not attend COP28, leaving a vacuum filled by Modi.
Antinatalism
IG: occupied by memes pro-antinatalism, of which many have many texts in the pictures;
TT: featured individual people articulating their arguments to promote antinatalism in a typical TikTok style;
TW: echoes what we see for netzero and COP28 on TikTok - 90% of the posts are viral and irrelevant ones. The only author posting relevant content is attaching screenshots of posts from another platform (Reddit) on parenting in a negative tone
Veganism
IG: prominence of activism - this may counter the observation from the vision network of veganism where vegan food and recipes are dominant;
TT: food and recipe - resonant with the observation from the vision network;
TW: there was also a sweetening of the pot with distractions but through irrelevant ads (e.g. St Mungo’s) rather than viral videos, occupying half of the top 10 authors’ posts. The rest see more about politics and activism.
5.2 Image to text analysis
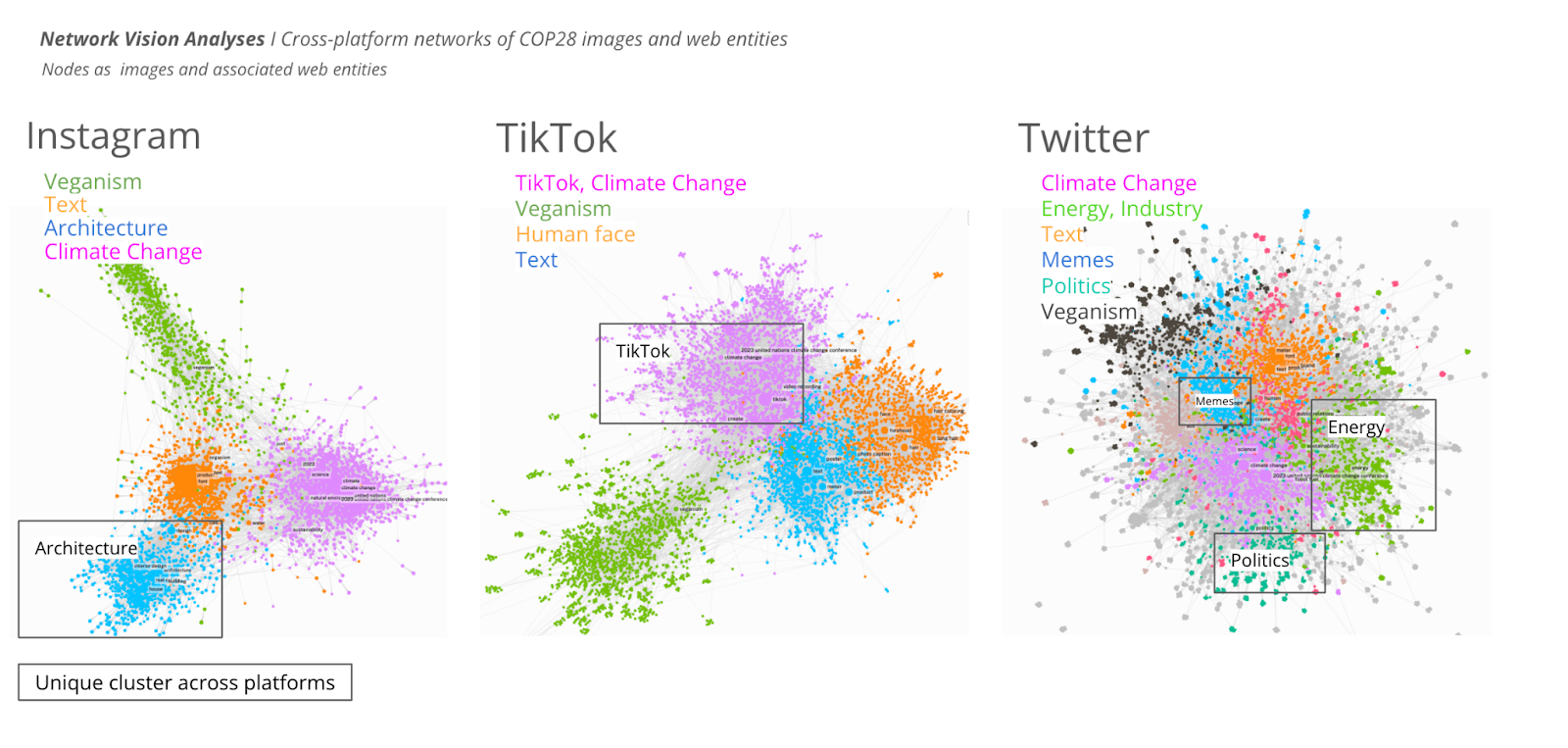
We examined a common visual cluster across platforms; what we describe here is the politics of veganism. Then, we identified a unique vernacular on Instagram pointing to wooden and container-based houses.
Comparative analysis of veganism clusters across platforms:
-
Twitter is still a visual political sphere for climate debates. For instance, veganism, lots of animals on the images >> a problem space
-
TikTok, veganism, no animals. We find food. >> Solutions for the vegan community, including how to cook. And this is the political aspect of TT.
-
The politics of veganism on Instagram are food-related and a lighter touch of quote-memetic visuals. Instagram is still keeping some of its fluffiness.
The co-text of images from antinatalism is very distinct from the rest of the dataset. With the others there is a lot of overlap. Within veganism, there are a lot of images that are not part of the climate discourse
Architecture cluster on IG, a unique characteristic of this platform:
Instagram is all about architecture. It represents a combination of practical elements that architects want to design more environmentally friendly buildings. However, it is more than that because there are a significant number of images containing wood. Wooden buildings sell the idea of ‘going back to nature’. Making houses out of containers refers to modular buildings, more financially accessible and connected with housing crises. This points to a second perspective, ‘solution-based alternatives’.
Prototypical image examples:
We created a folder with all IG-images of the ‘architecture’ entity. For a systematic collection of prototypical examples, we identified six subcategories of image types. In all those image types, people and/or text can appear additionally.
Subcategories of image types (connected to the entity ‘architecture’)
architectural drawings (of houses, etc.) +/- people/text
rooms/interior design +/- people/text
futuristic city views +/- people/text
futuristic buildings +/- people/text
tiny/wooden houses +/- people/text
unicoloured background +/- people/text
Subcategories of images connected to the entity ‘antinatalism’
aphorisms/text +/- unicoloured background/people
quote card/text +/- unicoloured background/people
comic/text +/- unicoloured background/people
meme/text +/- unicoloured background/people
reel/video screenshot/text +/- unicoloured background/people
screenshots from other platforms (twitter)/text +/- unicoloured background/people
5.3 Text to image analysis
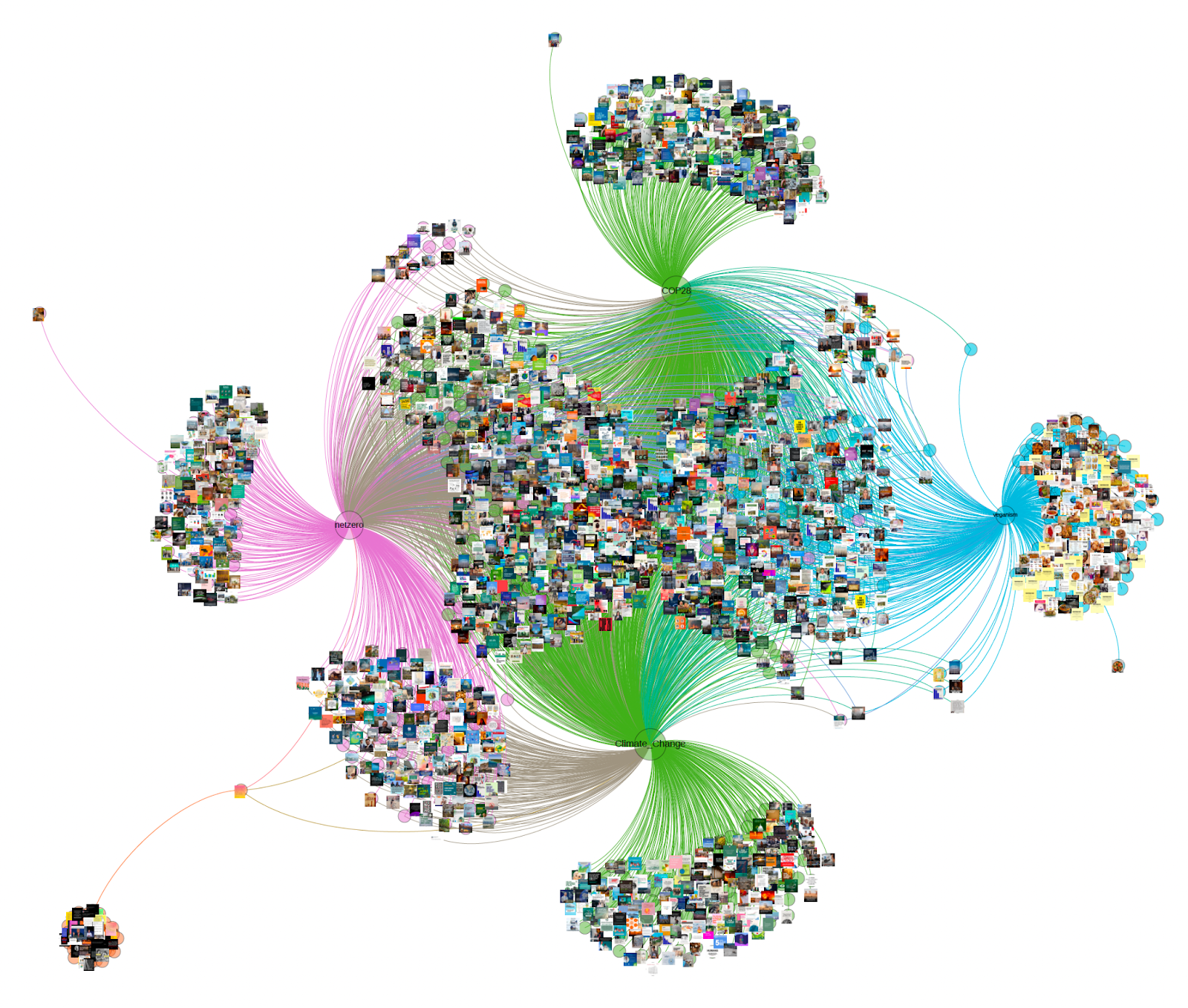
Figure 4. Instagram linguistic network and associated images
1. images used in posts on ‘antinatalism’ are linguistically contextualized very differently than all the other topics5.4 Methodological finding
Two different approaches to contextualise images and text in a situated perspective (not separate - see Tuters and Willaert 2022). We are minimising the interpretative gap between image and text in digital methods research. We are suggesting two different, but complementary, interdisciplinary approaches.
1. Approaching the text first, identifying trigrams which are linguistically relevant to the topics. Then finding the images associated with these trigrams through network visualisation, finding some images which were relevant to more than one topic, and some which were distinctive to only one topic. Enables a more issue-focused approach, which overcomes some distractions provided by the platform affordances from the issue under investigation. A limitation of this approach is that it blinds the research to platform cultures of use, as it focuses exclusively on text directly associated with the topic under investigation.
2. Approaching the image first, network vision analysis using web entities. Descriptive and contextual terms come not from the posts but from web-derived knowledge of image context. It enables the researcher to have a holistic vision of the image collection, including posting practices not precisely associated with the discussion topic. Moreover, it also allows the analysis of image clusters and associated text content.
Each of these two approaches yields a key finding on Instagram. Approaching the text first, we highlight the detachedness of the anti-natalism issue space from others within climate change. Notably, there is little or no significant shared textual content with veganism, the other cultural climate space being considered here. Approaching the image first, we find the prominence of architecture and buildings within the Instagram climate change issue space, specifically on modular housing and timber constructions (the latter having echoes of cottagecore).
6. Conclusion and Limitations
6.1 Conclusion
We find a distinct separation between the policy and cultural spaces of climate change on TikTok, Instagram and Twitter during the COP28 talks. There appear exclusive vernaculars in the discussion and vision of certain solutions to address climate change (e.g., timber constructions and container-based houses regarding netzero on Instagram). This separation is not so evident in some other cultural resources we have been looking at in the past. For instance, antinatalism is an increasingly prominent cultural perspective on environmental crises that appears in contemporary literature rather but not on social media.
The two complementary approaches through the three digital methods are proven to be able to provide both a concrete and collective understanding of social media posts; and can minimise the interpretative gap between text and image in digital methods research.
6.2 Limitations
One of the limitations of our project comes from the ways of constructing the datasets for Methods 2 and 3. We merged our initial 285 datasets into three based on the three platforms, which allows more comparative analysis across different platform affordances and user cultures. Another option can be merging all original datasets into five based on the five search queries, which will enable a more issue-focused exploration of these topics among all the social media platforms we chose to work on.
Second, we opted to remove duplicates as the focus is on the multimodal (image-text) co-production of climate vernaculars, rather than the prominence of specific posts through search algorithms. This constitutes a more issue-centric view. Future projects using the same original datasets may adopt a more platform-centric view, where the repeated recommendation of posts in search results assumes greater importance, for example, in the ‘ranking cultures’ approach (Rieder et al., 2018).
7. References
Basch, C. H., Yalamanchili, B., & Fera, J. (2022). #Climate Change on TikTok: A Content Analysis of Videos. Journal of Community Health, 47(1), 163–167.
Koop-Monteiro, Y., Stoddart, M. C. J., & Tindall, D. B. (2023). Animals and climate change: A visual and discourse network analysis of Instagram posts. Environmental Sociology, 9(4), 409–426.
Omena, J. J., Pilipets, E., Gobbo, B., & Chao, J. (2021). The potentials of Google Vision API-based networks to study natively digital images. Diseña, 19, 1-25.
Omena, J. J., Rabello, E. T., & Mintz, A. G. (2020). Digital methods for hashtag engagement research. Social Media + Society, 6(3), 2056305120940697.
Pearce, W. et al. "Climate change on Twitter: Topics, communities and conversations about the 2013 IPCC Working Group 1 report." PloS one 9.4 (2014): e94785.
Pearce, W. et al. "The social media life of climate change: Platforms, publics, and future imaginaries." Wiley interdisciplinary reviews: Climate change 10.2 (2019): e569.
Pearce, W, et al. "Visual cross-platform analysis: Digital methods to research social media images." Information, Communication & Society 23.2 (2020): 161-180.
Rieder, B., Matamoros-Fernández, A. and Coromina, Ò., (2018). From ranking algorithms to ‘ranking cultures’ Investigating the modulation of visibility in YouTube search results. Convergence, 24(1), pp.50-68.
Rogers, R. (2019). Doing digital methods. Sage.
Schwegler, Carolin, Anna Mattfeldt, and Berbeli Wanning. "Natur, Umwelt, Nachhaltigkeit." Eds. A. Mattfeldt. et al. Perspektiven auf Sprache, Diskurse und Kultur (2021): 1-32.
Stijn Peeters, & Sal Hagen. (2021). 4CAT Capture and Analysis Toolkit (v1.18). Zenodo.
Stöckl, Hartmut. "Linguistic multimodality–multimodal linguistics: a state-of-the-art sketch." Eds. J. Wildfeuer et al. Multimodality: Disciplinary thoughts and the challenge of diversity (2019): 41-68.
Tuters, M., & Willaert, T. (2022). Deep state phobia: Narrative convergence in coronavirus conspiracism on Instagram. Convergence.
Vidal Valero, M. (2023). Thousands of scientists are cutting back on Twitter, seeding angst and uncertainty. Nature, 620(7974), 482–484.
Wang, Yihe, and Kathryn E. Ringland. "Weaving Autistic Voices on TikTok: Utilizing Co-Hashtag Networks for Netnography." Computer Supported Cooperative Work and Social Computing. 2023. 254-258.
Ideas, requests, problems regarding Foswiki? Send feedback